Visual Features & Tracking: The fundamentals
What is a Visual Feature?
Today, let's get technical!
I will talk about Visual Features.
It's something that is used in Computer Vision for object tracking, panoramic stitching, SLAM (Simultaneous Localization And Mapping), 3D modeling, and many other applications.
👉 You don't need any advanced skill to understand this email, just the fundamentals.
If you ever got interested in Computer Vision...
You might have seen fancy words like SURF, BRISK, SIFT, ...
Did you?
If not, that's okay, but it's only a matter of time before you do...
So what is all of this?
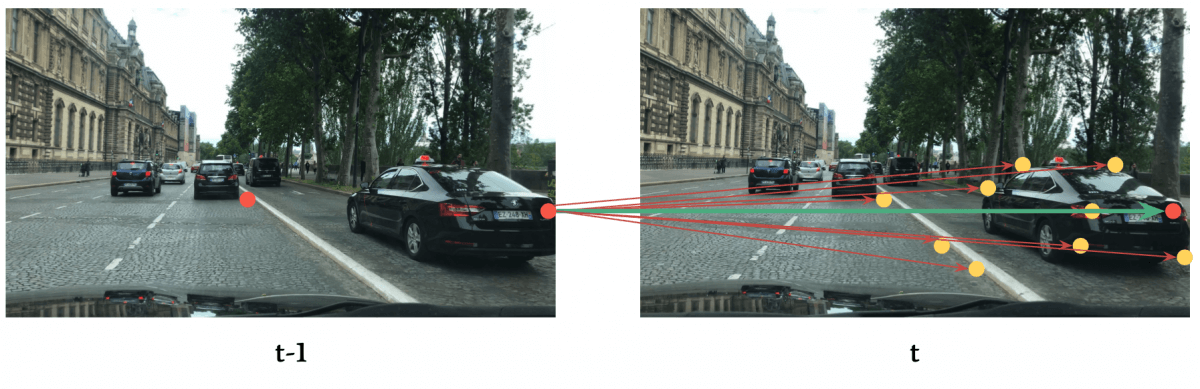
The general problem is about Image Matching: We want to find points in an image that can be found in other images.
👉 For example, we might want to track keypoints in a vehicle scene across several images.

If you come from Machine Learning...
You'll tell me to train a vehicle detection system.
And if you enrolled in my course MASTER OBSTACLE TRACKING...
You'll tell me to implement the SORT algorithm...
... Which means detecting vehicles using Deep Learning, and tracking them using the Hungarian Algorithm and Kalman Filters... (Enroll here if you didn't understand a word of that last sentence )
👉 This is another type of tracking algorithm, which doesn't rely on obstacle detection algorithm.
The general idea is the following:
- Detect keypoints using Feature Detectors
- Compute the features of these keypoints using Feature Descriptors
- Match these keypoints between images using Feature Matchers
Let me give you an example.

👉 In these two pictures, I have accomplished Step 1 - Get the Keypoints.
So what's a keypoint? It's something very unique, like a corner, a strong gradient, a line, ...
You don't need a Deep Learning algorithm to find corners, you just need to compute the difference between two pixels and look at the gradient.
When selecting a keypoint detector, we must of course pay attention to:
- The Scale
- The Rotation
- The Intensity Change
- The Affine Transformation
I know it doesn't really mean anything, the idea is to make this possible:

See? Rotation, Scale, Intensity, ... it works.
What are popular Keypoint Detectors? (Most are natively implemented in OpenCV)
- Harris Corner Detector (Harris, Stephens)
- Good Features to Track (Shi, Tomasi)
- SIFT - Scale Invariant Feature Transform (Lowe)
- SURF -Speeded Up Robust Features (Bay, Tuytelaars, Van Gool)
More real-time:
- Features from Accelerated Segment Test (FAST) (Rosten, Drummond)
- Binary Robust Independent Elementary Features (BRIEF) (Calonder, et al.)
- Oriented FAST and Rotated BRIEF (ORB) (Rublee et al.)
- Binary Robust Invariant Scalable Keypoints (BRISK) (Leutenegger, Chli, Siegwart)
- Fast Retina Keypoint (FREAK) (Alahi, Ortiz, Vandergheynst)
- KAZE (Alcantarilla, Bartoli, Davidson)
Those are cool names.
If you're good with maths, it's quite possible to understand these algorithm.
The second part is about creating Descriptors to match these keypoints.
If we can match them, we can track them, build 3D Maps, and many more...
The Problem? For a single keypoint, there are hundreds of possible matches... and only one correct answer.
This is why algorithms also do something called Description.
An algorithm can be in Detector mode (detect the keypoints) or in Descriptor mode.
A descriptor is an algorithm that will compute unique features.
👉 For example, the dominant color of the 16x16 patch around a specific keypoint can be a feature. A good feature we can use is called HOG (Histogram of Oriented Gradients).
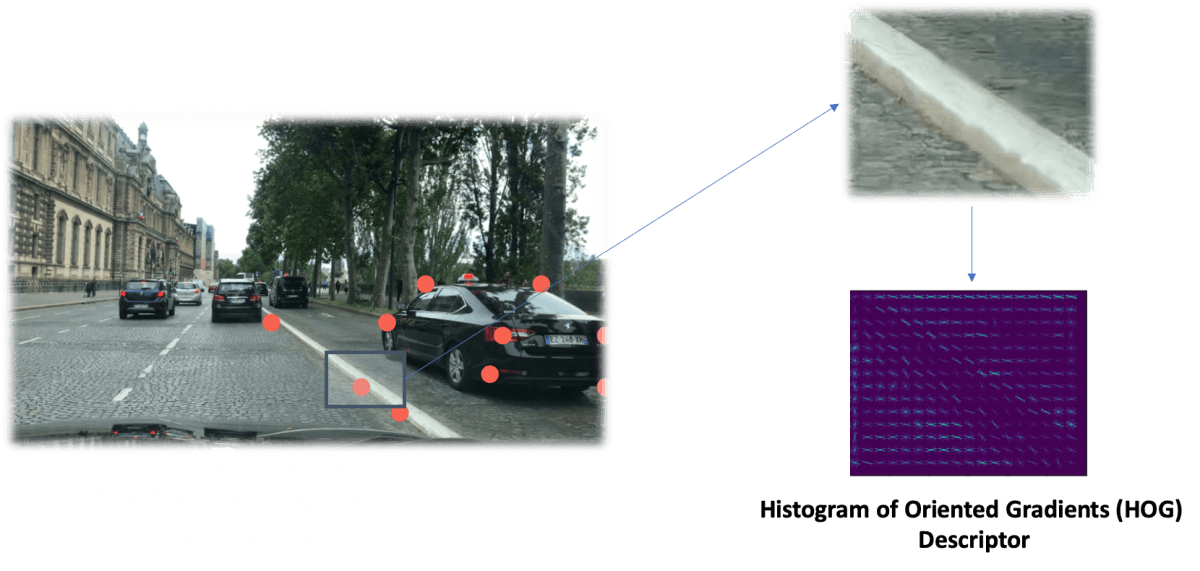
Got the idea?
Most detectors (SURF, SIFT, BRISK, BRIEF, ...) also are descriptors.
Descriptors must be highly distinctive (for 2 points, I must have two different descriptors), and invariant as much as possible to variations (viewpoint, light, ...).
Finally, we must match the Histogram of Oriented Gradients Features.
To match keypoints, we need a cost function.
The Sum of Absolute Differences (also called the L1-Distance) is often used, but some algorithm also use the Sum of Squared Differences (L2-Distance), or even something called the Hamming distance.
Algorithms for matching can be very different: it can go from Brute Force Matching to Deep Learning.
In Computer Vision, we're closer to the first.
- BFMatching (Brute Force) is doing an NxM work and compares all the keypoints descriptors from the first to those from the second.
- An algorithm named FLANN (Fast Library for Approximate Nearest Neighbors) is also very much used. The difference is that it builds a KD-Tree and thus reduces the complexity.
👉 It's good to understand how this works, but keep in mind that you can do all 3 with basically 3 lines of code (one for the detector, one for the description, one for the matching).
👉 Since algorithms don't work the same, you can't pair every algorithms together (for example AKAZE and SIFT). If you don't do the work of understanding the algorithm, you'll be stuck with an OpenCV error you can't solve.
As I said in my LiDAR/Camera article, these matchers must also take repetitions into consideration.
Here, both windows would have roughly the same cost.

What is good with Visual Features?
They have been optimized to run in real-time.
- They also multiple things like LiDAR/Camera fusion or tracking.
- They don't rely on learning - and can therefore be seen as more trustworthy.
I hope you learned a lot today!
I'll see you tomorrow in the mailing list 👋🏻
Jeremy