3D Computer Vision: From Stereo Vision to 3D Reconstruction
Back in 2018, I was an engineer working on autonomous shuttles, and tasked to build an object detection and tracking system. The task was simple; "you design an object detection system, if there's an obstacle in front of the shuttle, you return it and we break."
So think about it.
It's 2018, and only one thing came to my mind: YOLO.
At the time, everybody was sharing YOLOv2, and how it was so fast, so powerful, and how every computer vision engineer needed to learn it. And I did learn it. So I spent a few weeks building the object detection model, and trying to integrate it in the car.
This task was a matter of a few days, or so I thought...
You see, the bounding boxes returned by YOLO were in 2D. For example, an obstacle was returned to me like (100, 120, 400, 420). But how could I use that to break? I needed the actual distance to the camera of each obstacle. And even more than this, I needed the exact 3D position of each obstacle. Otherwise, why do you implement object tracking and all these things?

I thought YOLO was useful, until I actually used it and realised I had no clue what to do with it. I was stuck, because I was using 2D Computer Vision. But the real world is in 3D, and thus, what I needed was 3D Computer Vision.
This "2 week" minor task suddenly turned into a several months, major project. In this article, I'm going to describe exactly why you need to build 3D vision skills, how to do it, and what you can do once you have them.
Why you need to shift from 2D to 3D Vision
If you're an engineer and you learned machine learning, it's likely that all you've done is 2D Computer Vision. Thus, you probably know how to load, preprocess, and classify images, how to detect objects with bounding boxes, and maybe even how to classify each pixel using semantic segmentation.
This is useful to lots of applications, but I found that in the space of robotics, you need to combine that with 3D. And not only in Robotics, but also in Augmented Reality, Drones, Self-Driving Cars, and even smart retail systems like Amazon One.
When going 3D, there are LOTS of things you can suddenly do, for example you can:
- Find the depth of an obstacle in an image
- Fuse the camera image with a LiDAR or RADAR (Sensor Fusion)
- Build 3D models of the world (3D reconstruction)
- Create Maps and Navigate in them (Visual SLAM)
- Get a Bird-Eye View of the World
- And many more...
Yes, 2D is okay, but it will limit what you can do, what you can build, and where you can work. When you go 3D, you'll however learn new things. Your bounding boxes are in 3D, you have depth maps, and even Point Clouds.

So let's see how to do this:
The one goal of a 3D Machine Vision system
When you start learning about 3D, you'll stumble across lots of new terms, such as "Stereo Vision", "Pseudo LiDAR", "Structure From Motion", "Camera Calibration", "Monocular Depth Estimation", "Disparity", "Depth Maps", "Camera Models", "Photogrammetry", "Multi-View Stereo", "SLAM", "Active and Passive Stereo", "Voxel", and more...
This can all become very complicated very quickly, so let's break it down to one idea:
When doing 3D Computer Vision, the one thing you want is to turn one or more images into a 3D model.
If you have one line to remember from this article, it's this one. By model, I mean point cloud, but also a real 3D model, like a video game character for example.
Why is a 3D model needed? Simply because of what I said before, we need the real distances, positions of objects, lanes and buildings in relationship to another, trajectories, and all of that needs to be 3D, because the real world is 3D. For example, you can find many 3D and even 4D implementations in my article on 3D Object Tracking.
In this article, I want to mainly explain you 2 core ideas of this world:
- Depth Estimation
- 3D Reconstruction
If you understand these 2 concepts, you're then good to get started with 3D, so let's dive in the first one:
Depth Estimation: From 3D Object Detection to Point Cloud Reconstruction
You remember how I said with 2D Bounding Boxes, you can't do anything? Well, it's clear we need to shift our object detection system from 2D to 3D, but how?

Monocular Depth Estimation
The first solution would be to use Deep Learning to predict the distance of the object inside the bounding box. We could have an annotated dataset, with boxes and distances; and this was the very first thing I tried. The data was labelled using a LiDAR, and my network was a basic CNN that was called for each bounding box and that returned the distance.
This is called "monocular depth estimation", and this is okay, but it turns out to be quite hard to do, and even harder if you then want to create a 3D model. This is why we need Stereo Vision.
Stereo Vision
Let's say you have 2 cameras. We call that a "stereo" setup. Thanks to these stereo images, and thanks to triangulation and geometry, we can build a depth map. And from this depth map, we can use geometry to retrieve a 3D point cloud.
This is a 2-View 3D Reconstruction system:

Ok but what's a depth map? Before I move on to the next example, I need to explain briefly what's behind the core idea of this algorithm.
So what's a Depth Map?
A Depth Map is the size of the original image, but rather than having every pixel representing a colour, we have every pixel encoded with the distance information. Simple, it's a map where each pixel has a distance.
Example (notice how the dark pixels mean "far" and the white pixels mean "close"):

Here is the 4-step process we use:
- Image Formation and Calibration: We calibrate 2 aligned images and get the intrinsic and extrinsic parameters.
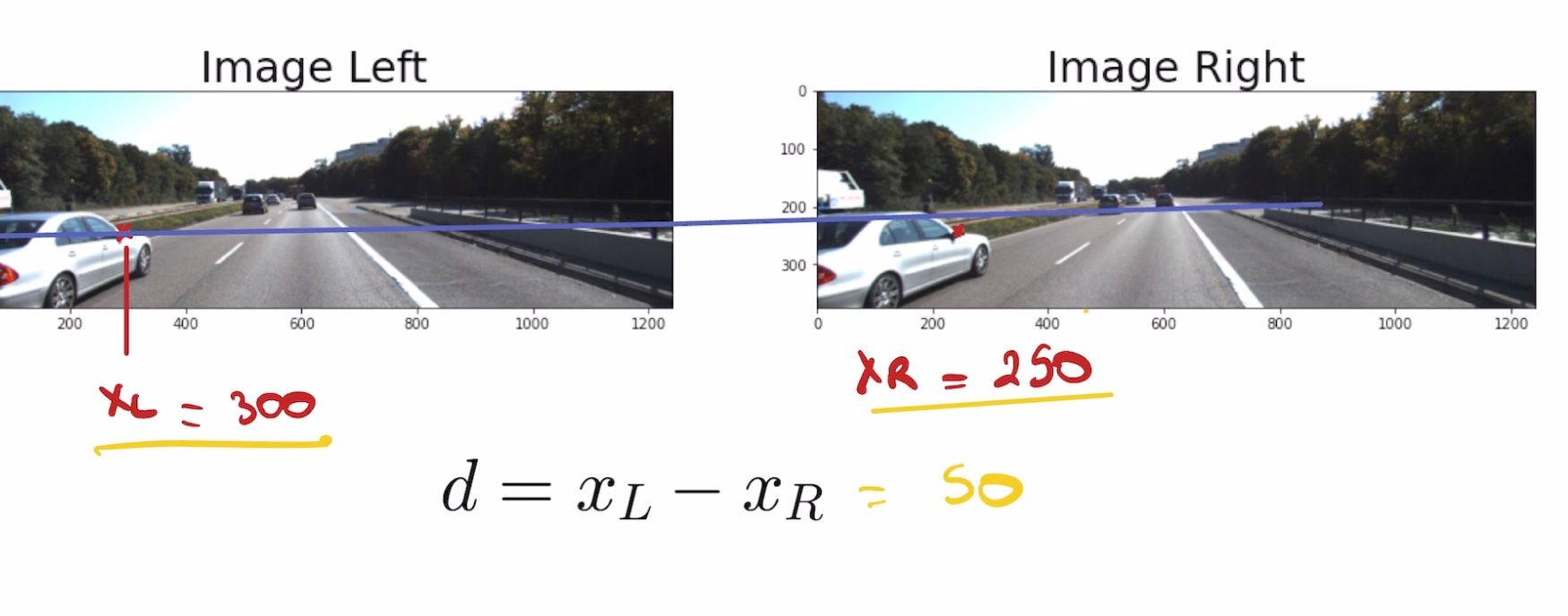
- Disparity Estimation: We find the "stereo disparity" between the 2 images (think when you close one eye and then the other, what is the pixel difference for the same point?).
- Depth Maps: We then use the intrinsic and extrinsic parameters from (1) and the disparity map from (2) to build a Depth Map.
- Two-View Reconstruction: We convert the Depth Map into a point cloud. We do point clouds, but we could also do voxels, full 3D models, etc...
The main idea is behind the word "triangulation" — because we have 2 images of the same object, we can calculate the disparity, and then build a depth map.
You can learn how to do that in my course MASTER STEREO VISION, where the final project is 2-View Reconstruction. I also teach a basic introduction in my article on Stereo Vision.
When you have a Depth Map, you know what is the distance of each pixel, so you can do 3D Object Detection, and the 2-View 3D Reconstruction.
Next:
3D Reconstruction: From Photogrammetry to NeRFs
What I showed you before was made from 2 images, and notice how we don't have a nice 360° view of the road. We have two ways to build the 3D model, either by stacking more images, and using more depth maps and geometry to build the model; or by sending all the images to a neural network and build scenes.
Let's see them:
Photogrammetry: Advanced Geometry and Point Cloud Reconstruction
What we can do is to use multiple view geometry to then build the rest of the object. In my 3D Reconstruction Exploration, I teach how to do this using Multi-View Stereo and Structure From Motion to recreate a fountain from 8 images:

This is called Photogrammetry, and it's all about building this model using several cameras, with known or unknown camera parameters (including their relative position to each other). In the first case (known parameters), we call the problem Multi-View Stereo. In the second case (unknown parameters), we call it Structure From Motion.
Really cool, you take a video of something, and then boum! You have the 3D model.
Finally:
Neural Radiance Fields: Deep Learning for 3D Reconstruction
Lately, a cutting-edge algorithm called "NERFs", or Neural Radiance Fields has been very popular in the Deep Learning space, because it does the same thing as above, not with photogrammetry (traditional geometry), but with Neural Networks. Thus it has better lightning, can estimate missing images, and give incredibly cool results.

Mindmap Recap
Next steps: How to build cutting-edge 3D Skills
If you've read this far, it's likely that you're interested in what I have to say. First, note that you can learn much more about 3D through my daily emails.
The idea is simple: every day, you receive an email about cutting-edge technologies. It can show you technologies you need to learn, explain to you how to learn them, and it often even contains career tips and interviews with field experts. Don't think it's just your regular boring newsletter, over 10,000 engineers read it religiously, and many don't miss a single email.
If you're already reading my emails, the next level is to take my course MASTER STEREO VISION. It's a course I recently updated, and it contains many projects and information about Stereo Vision and 3D Computer Vision. It has been a complete game changer for many of my engineers. This course also contains a "DLC" specifically on 3D Reconstruction, which is accessible only to the participants of the course.
I'll see you inside!