Computer Vision Applications in Self-Driving Cars
In Self-Driving Cars, Computer Vision is one of the most important and useful topic. In fact, we can pretty much agree that the camera is the only sensor you cannot ditch in a self-driving car.
In an earlier article called “Introduction to Computer Vision for Self-Driving Cars”, I talk about how Computer Vision works for basic applications. These are the “traditional” Computer Vision techniques.
In this article, I mentioned 3 major Perception problems to solve using Computer Vision.
- Lane Line Detection
- Obstacle & Road Signs/Lights Detection
- Steering Angle Computation
For these problems, I respectively used traditional Computer Vision, Machine Learning and Deep Learning

It’s not that these algorithms do not work, but today, we are able to do SO MUCH BETTER using Deep Learning.
In this article, I want to explore the cutting-edge techniques that we are using TODAY (>2021) in self-driving cars.
We’re going to see the advanced applications of Computer Vision in self-driving cars, such as object detection in 3D, deep tracking, or segmentation!
- Introduction to Computer Vision for Self-Driving Cars
- Object Detection in Self-Driving Cars
- 2D Object Detection
- 3D Object Detection
- Stereo Vision
- Lane Line Detection
- Object Tracking
- Segmentation
- Conclusion and How to Become a Computer Vision Engineer in Self-Driving Cars
Object Detection in Self-Driving Cars
2D Object Detection

In my first article, I explained how to deal with object detection using Machine Learning. For that, we used HOG (Histogram of Oriented Gradients) features and a Support Vector Machine (SVM) classifier.
Today, we are using Deep Learning to detect objects: algorithms such as YOLO, SSD, or RetinaNet are the cutting-edge approaches for this!
When detecting obstacles, the result is generally more than simply outputting car or not car. We need bounding box coordinates (x1, y1, x2, y2) that we previously had with the sliding window. We need score confidence (to threshold low confidence values) and the class (car, pedestrian, …) that the SVM algorithm got.
In Deep Learning, we can simply have an architecture outputting one neuron per desired number at the end of the neural network.
The convolutional layers are here for autonomous feature learning (size, color, shape) while the last layers are here for the output. They learn to generate the bounding box coordinates and the other relevant features we need. All is done in a single neural network.
Here’s an example architecture of a very popular algorithm called YOLOv4.
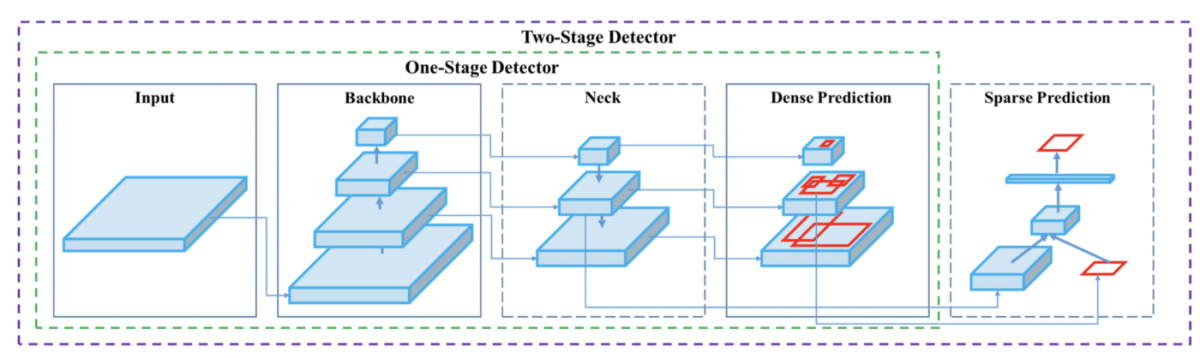
In this algorithm, we send a simple input image through multiple layers of neurons that output a bounding box. To learn more about it, I invite you to read my YOLOv4 research Review!
Algorithms like YOLO are today considered state of the art, they can perform at really high frequency (over 50 FPS) and almost never miss obstacles.
3D Object Detection
The main problem with 2D object detection is that… well, it’s in 2D! The real world works in 3D. Instead of working with Pixel coordinates, we want to translate this into XYZ coordinates.
For that, we can either use Stereo Vision or Monocular 3D Object Detection. Which is our first topic!
Moving from 2D to 3D Bounding Boxes allows to understand vehicle’s exact position and distance from us, as well as its precise orientation and direction.
Using Deep Learning and Geometry, we can try and convert a 2D Bounding Box into a 3D one. Research from CVPR 2021 also shows that now, Neural Networks are trained to estimate depth and the 3D box directly from the 2D image.

The paper where the image is from discusses an approach to estimate 3D Bounding Boxes using Deep Learning and geometry.

As you can see, we want to not only estimate the dimensions of the 3D Box, but also the orientation, and the confidence.
In this approach, Deep Learning is again used for feature learning (dimensions, angle, confidences). Geometry is then used to translate information into a 3D world.
Having 3D Bounding Boxes can allow for 3D matching with 3D sensors such as LiDARs. It allows better understanding of the orientation of a vehicle and then anticipating its behavior. 2D Bounding Boxes are often presented when people learn self-driving cars technology. However, 3D Bounding boxes are much more relevant to the problem.
Stereo Vision

In case you don’t trust Monocular 3D Object Detection, it’s also possible to detect obstacles using 2 cameras. This is called Stereo Vision.

Using geometry principles, we’re able to retrieve the exact 3D coordinates of an obstacle, reconstruct the scene in a 3D Point Cloud, and much more!
A particular note on the use of Deep Neural Networks here for a special case called Disparity Matching! There is a lot of active research on Stereo Vision using Deep Learning!
I invite you to visit my dedicated course MASTER STEREO VISION: Expert Techniques for Pseudo-LiDARs & 3D Computer Vision to learn how to implement this on real self-driving car data.
Lane Line Detection
For lane lines detection, Deep Learning can be used in the exact same way.
The role is to generate the lane line equation coefficients. Lane lines can be approximated with first, second, or third-order coefficients equations. First-order equation would simply be ax+b (a straight line) while higher-dimensional ones will allow for curves.

In a CNN, the convolutional layers learn features, while the last layers learn lane line coefficients (a, b and c).
This may seem simple: set a few convolutional layers, set a few dense layers, and set the output architecture to have only 3 neurons for a, b and c coefficients.
In reality, this way is harder. Datasets are not always mentioning lane lines coefficients, and we might also want to detect the type of line (dashed, solid, …) as well as whether the line belongs to the ego vehicle lane or to an adjacent one. There are multiple features we may want to have and a single neural network may be really hard to train and harder to generalize.
A popular approach for solving this problem is using instance segmentation. In segmentation, the goal is to give a class to each pixel of an image.. In segmentation, the goal is to give a class to each pixel of an image.
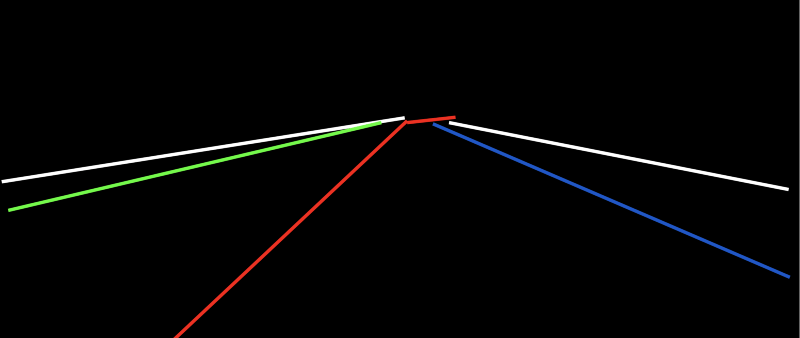
In this approach, each lane corresponds to a class (ego left, ego right, …) and the goal of the neural network is to generate an image with these colors only.

In this type of architecture, the neural network is working in two parts. The first part learns the features, the second part learns the output. Just like for bounding box detection.
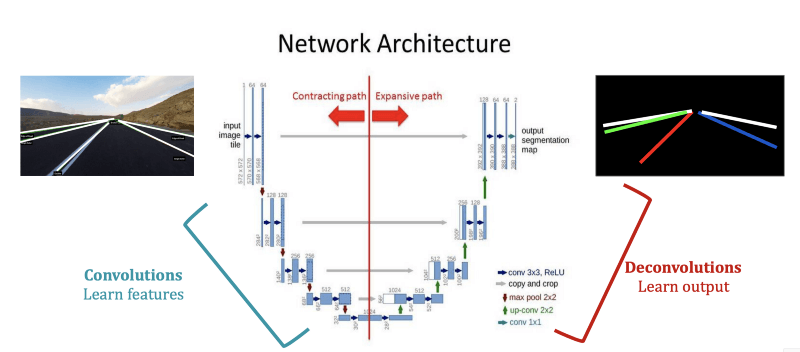
If the output is a simple black image with colors, it’s then very simple to use Machine Learning and a linear regression (or multiple) to find the lane lines on the same color points.
These approach generally outperform the traditional ones and can be 10 times faster. In my tests, I had 5 FPS for the Computer Vision approach and about 50 FPS for the Deep Learning approach.
Object Tracking
In my article Computer Vision for Tracking. I mention a technique to track obstacles through time using a camera, Deep Learning, and Artificial Intelligence algorithms such as Kalman Filters and the Hungarian Algorithm.
Here’s the result on two images:

Here, bounding boxes do not change colors from frame 1 to frame 2 as it would do in a classic YOLO approach. The car on the right has a black bounding box on frame 1 and on frame 2 because of the association. Same color objects don’t have the same color boxes either.
It can be very difficult for neural networks to learn to get this result. That is why we use bayesian filtering and an association algorithm. Have a better understanding here.
In this approach, Deep Learning is used for bounding box detection, and the result is immediately passed to the other algorithms that decide if the vehicle is the same as the previous one or not. To decide, convolutional features can also be used as matching depends on what the object looks like as well.
Using time this way can then allow for other applications such as tracking and behavioral prediction.
Freespace Detection

Freespace detection is quite popular in the self-driving car world. Yet a lot of people still wonder what is the use. I didn’t have the chance to use it since developments do not prioritize freespace use; but I hope to have a good idea of the use.
The architecture is similar to the segmentation part with the lane line detection problem.
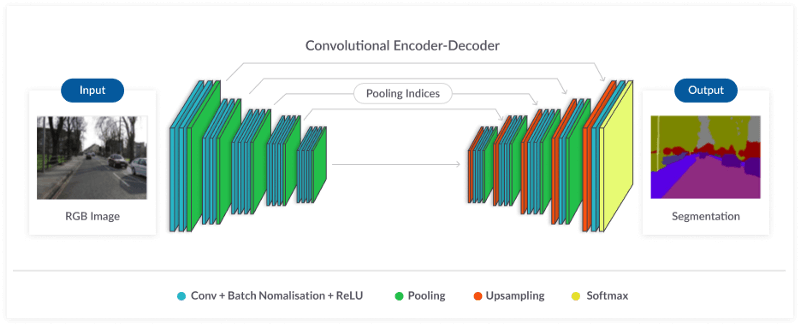
This is an Encoder-Decoder architecture. Encoder means convolutions and learning features, decoder means recreating the feature map.
Freespace can be pretty useful to know how to manoeuvre around a slow vehicle and change lanes. It can also be used when lanes are unavailable and need to be recreated or when there are obstacles in the way and the car needs to stop. Freespace can therefore be used for redundancy with obstacle detection algorithms.
I have an entire course on IMAGE SEGMENTATION, I invite you to check it out here and learn how to apply segmentation algorithms to find drivable areas.
Conclusion
We have discussed multiple ways to use Computer Vision and Deep Learning in a self-driving car. The purpose here is always the same: PERCEPTION.
It turns out we can also use Deep Learning for Localization, with SLAM algorithms for example. There are also others things we didn’t mention, such as Sensor Fusion.
There is a huge need for engineers to understand how to code state of the art research papers. Approaches are always changing and it might be challenging if you don’t know how to adapt to using new techniques frequently.
In the end, Deep Learning is the go to solution in self-driving cars if we are using the camera.
I have created a Deep Learning MindMap that will explain to you every use of Deep Learning in Self-Driving Cars. It’s going to get much further in these Computer Vision algorithms, but also for the Localization and Planning parts. It’s also linked to 4 videos and an article on Deep Learning in Self-Driving Cars!
📩 To download the mindmap and the bonus videos, I invite you to join the daily emails and receive my cutting-edge content on Self-Driving Cars and Computer Vision!