

Active Learning: the Fundamentals
A few days ago, I came across a startup’s website in which the main argument was Active Learning. When I read about it, I instantly felt “ They know what they’re doing.
When people talk about Artificial Intelligence today, they mean Machine Learning. And when they mean Machine Learning, what they really mean is active learning or supervised learning.
Active learning is another subfield of Machine Learning we call semi-supervised.
I spent a few hours trying to understand the topic, just so I can explain it to you. Today will be an introduction. After this article, you will have a better idea of what Active learning means, and you’ll know if it’s a good thing to have on a website or a resume.
What is Active Learning?
Today Machine Learning is confused with supervised learning.
One image we see everywhere when getting interested in Machine Learning is this one.
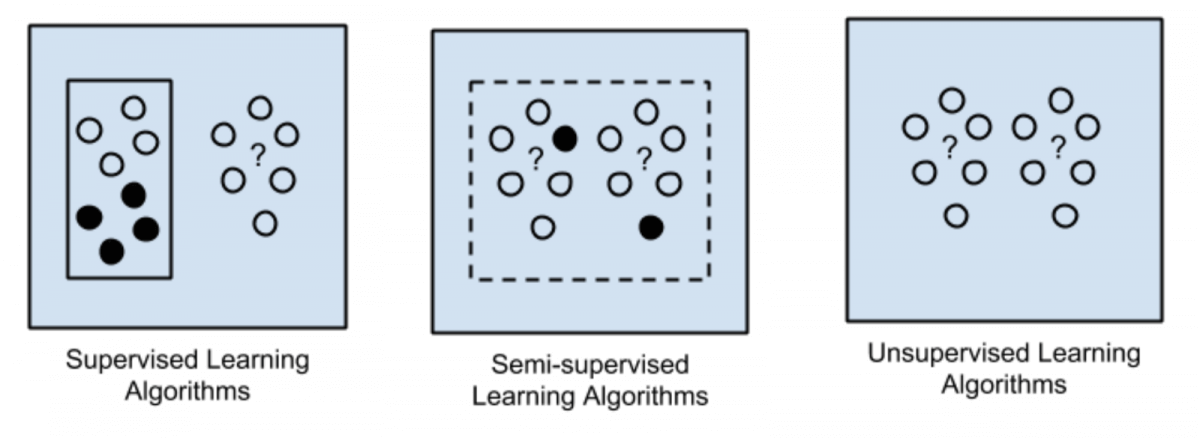
You might also encounter Reinforcement Learning, which is not detailed here.
So, where is Active Learning?
If you’re like most of the Machine Learning Engineers, there is a high chance that you do the following association:
- Supervised Learning — Classification or Regression
- Unsupervised Learning — Clustering
- Semi-Supervised Learning—I’ll have a look maybe next year
It’s not your fault, Active Learning tutorials are not as popular as the rest. In fact, when I searched on Youtube, it was a disaster. It wasn’t better on Medium.
Active Learning is a rare topic. Does it deserve more attention?
How is Active Learning used?
The most frequent use case of Active Learning is one we see every day.

Have you ever wondered what happened here?
Are you a human labeller?
What happens if you (voluntarily) choose wrong?
When selecting the traffic lights (or other), you are a link in the Active Learning Process.
Active Learning is used a lot when you need to label data. Data labeling is expensive, long, and boring. I once labeled a custom object detection algorithm, it took me hours of repeating the same task.
What is the labelling process for object detection?
Mostly, you fill a txt file with bounding box coordinates and class of each object. You generally install a GitHub project to simply draw on an image and automatically generate a file. Still, it’s very long and tedious.
Now, can Active Learning help here? YES.
Active Learning is used to reduce the labelling time.
How? By only labeling the hardest elements.
The term “Active” implies that the model is constantly learning. And it's doing so by using the newly encountered elements for training.
Active Learning Architecture
Let’s say you have a model that is doing okay at recognizing cars. You’d like your model to improve with time, and with new events. In particular, every time you cross a new car, you’d like to add this car to your dataset.
If your car detector is already trained and running, it should recognize at least 90% of the vehicles with high confidence . The other 10% should be either false positive, false negative, or low-confidence detections.
What active learning does is adding every high confidence detection to the dataset, and asking a human to label every low-confidence detections in the remaining 10%.
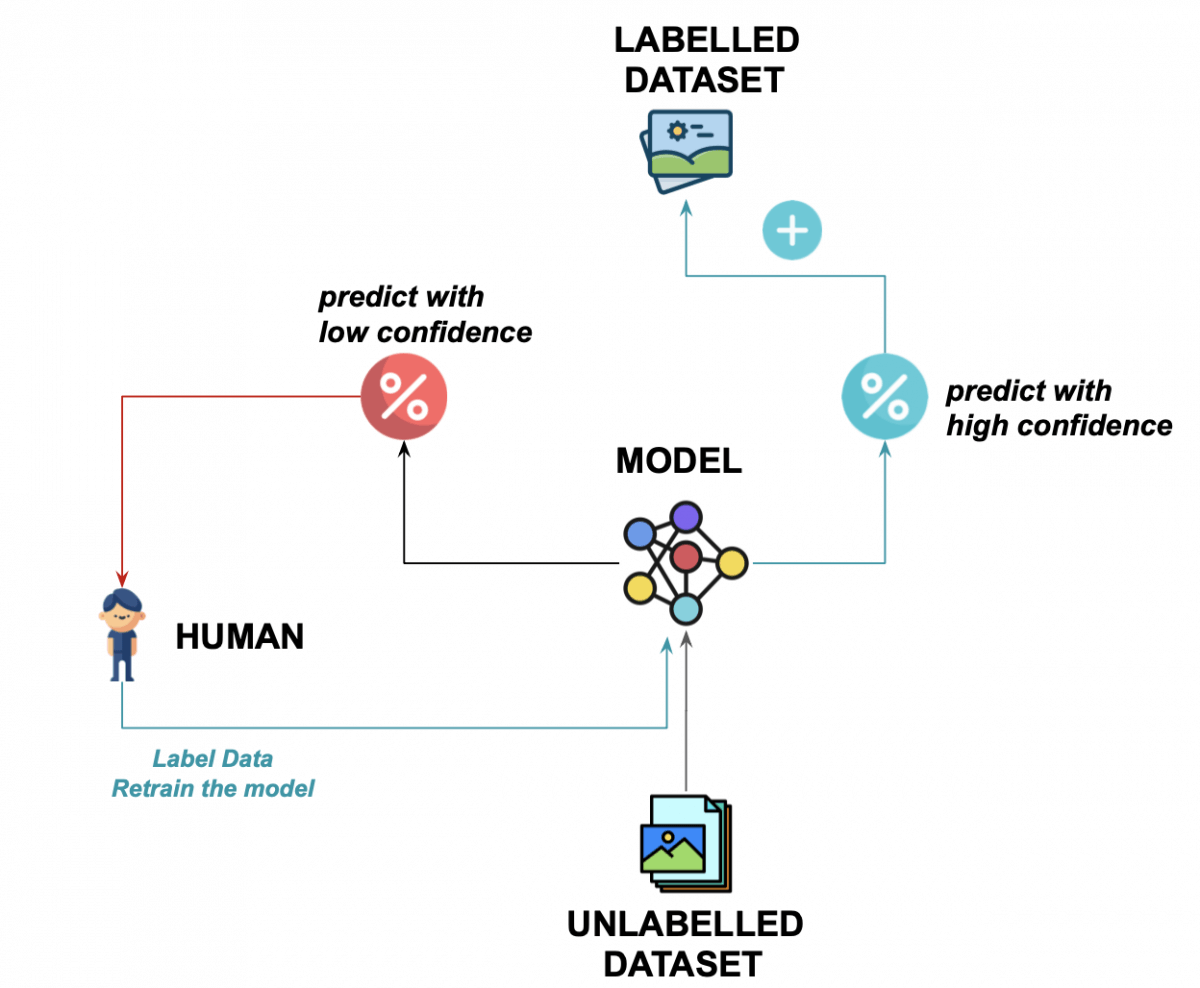
We start with an unlabelled dataset (the world) and a trained model.
We run the model on each new unlabelled example, it generates a prediction or label.
If the confidence is high, we accept the label and add the element to the dataset. We eventually retrain the model using the new data.
If the confidence is low, we ask a human to hand-label the data
We rerun the model and go back to 3.
👉 Using this technique, we have a model that is constantly improving.
Every time you run your model, it will learn at the same time by adding every new element to the dataset .
When it’s not sure (it should be 10% of the time), you will do it by hand.
When we see traffic lights from Google Recaptcha, we actually see difficult images, where the model is unsure. We are the humans that label the images and improve the model.
If we label it wrong, there should be a consensus between every human involved; a bit like a bagging algorithm (majority vote). Think about it, the model is already struggling with this data point, and we label it wrong for fun.
Is is that simple?
It can be. But as you might have guessed, there is some complexity in it.
Especially, how do we select the elements to label and the elements to validate?
This is the question that creates a whole field of research.
There are a lot of different techniques, I will simply list a few.
- Uncertainty sampling
- Query By Committee
- Expected Error Reduction
- Expected Model Change
- Expected Variance Reduction
The one I mentioned in my image is uncertainty sampling.
We select low confidence results and hand-label them.
The other techniques involve going deeper into the model.
One thing to be careful with is the confidence given by the model.
If everything relies on this, we must be sure that the model doesn’t incorrectly label with 99% accuracy.
Active Learning is a growing field.
Let’s keep an eye on it! In 2021, the algorithms will learn using this technique. Just remember you learned it first here!
BONUS VIDEO: How NVIDIA uses Active Learning for Self-Driving Cars





{kind=link}