

19 Machine Learning Types you need to know (Advanced MindMap)
Back when I was discovering Machine Learning, it didn't take long before I got introduced to this image:
A couple of years later, the image is much more different, and now looks like this:

That's right, I labeled that as a nightmare.
And even though we can be incredibly thankful to the researchers that spent years developing these types of learning, it also became super hard to understand from a learner point of view.
What is Semi-Supervised Learning? Or Weakly-Supervised? And Active Learning? Contrastive Learning? Are you kidding me?
I think it's time for an article to introduce to the new Era of Machine Learning we're living in — and not just with basic explanations, but with images, pictures, mindmaps, and examples that make sense.
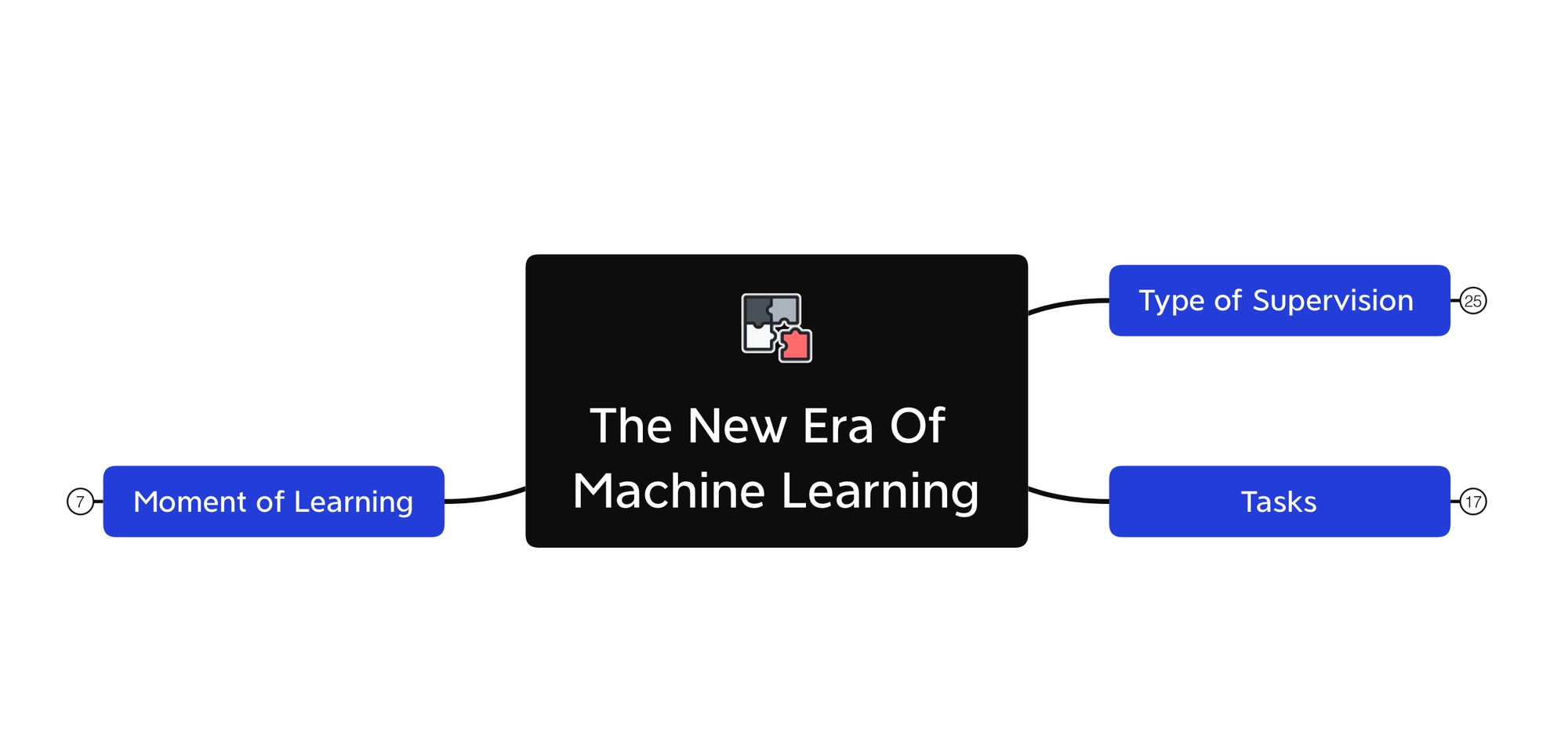
In this article, I'm going to classify Machine Learning by 3 different ways:
- The Type of Supervision (supervised, unsupervised, ...)
- The Moment of Learning (online, offline, ...)
- The Tasks to solve (meta, multi-task, contrastive, ...)
Let us begin:
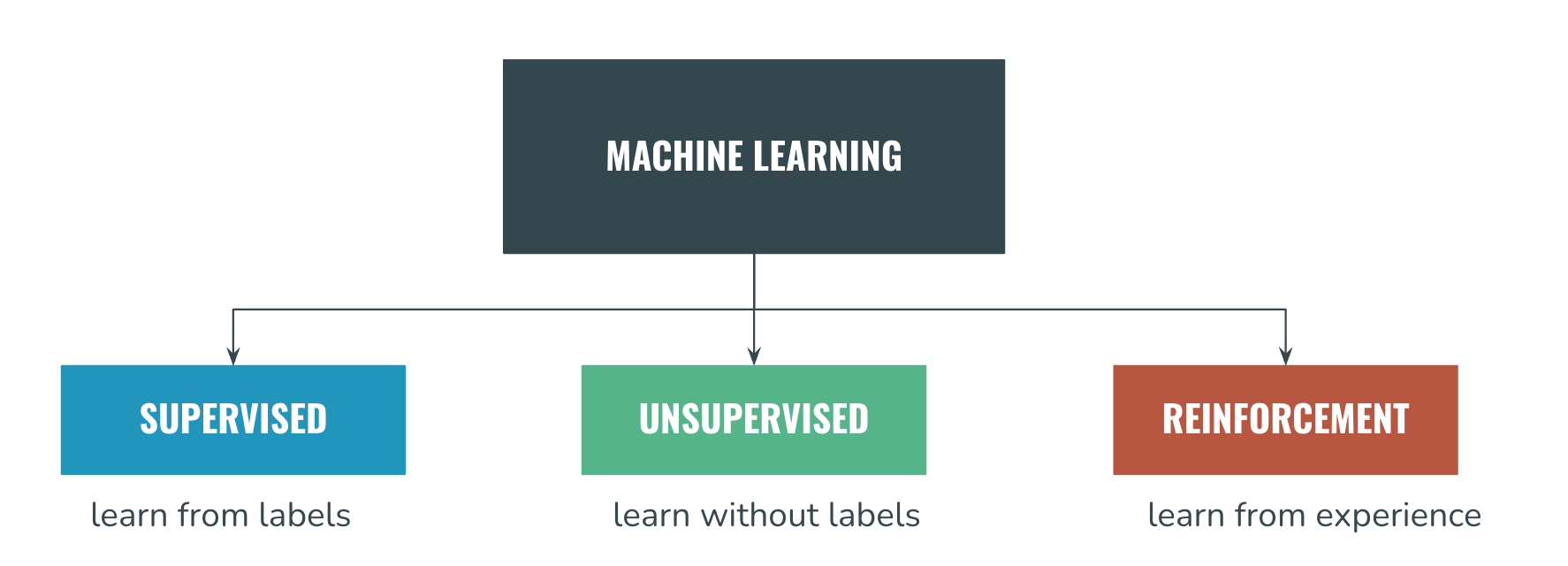
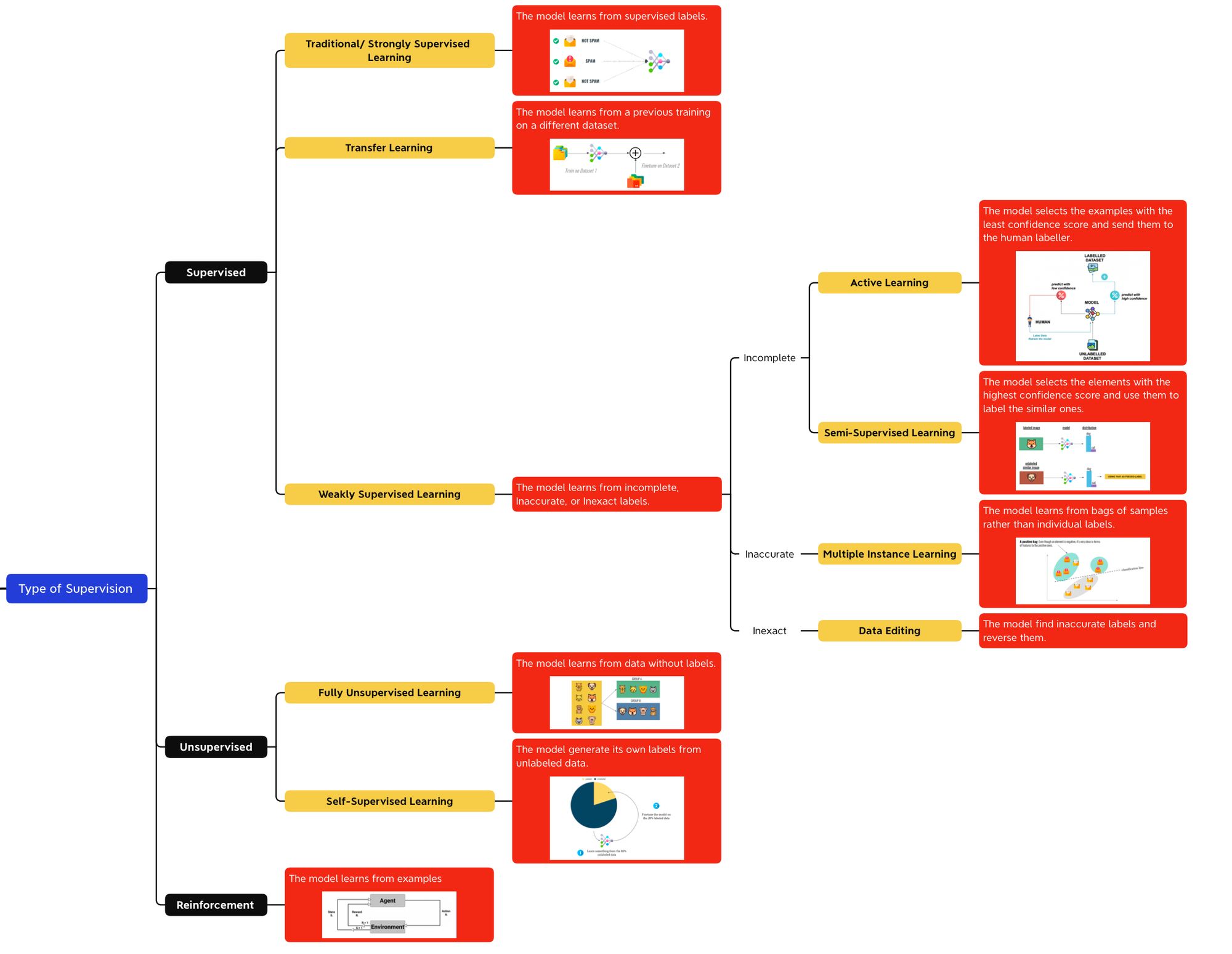
Classification #1: Supervision
We already know the 3 types of supervision, and they probably need no introduction:
- Supervised Learning — learning from labels
- Unsupervised Learning — learning without labels
- Reinforcement Learning — learning from experience
If you're reading more types out there, such as semi-supervised, or weakly-supervised, they're all "types of supervision". And to go even further, we can afford to not create a 4th, 5th, or 10th branch, but to integrate all the new types of supervision into these 3 branches.
For example, if you read the Machine Learning literature, you'll learn that Weakly Supervised Learning is a type of Supervised Learning. The same way, all of these new types of learning are sub-types of supervised or unsupervised learning.
So we're good, we're sticking with these 3. Now let's dive into the first type: supervised learning.
What Supervised Learning Algorithms have become
For most, supervised learning is about having a dataset with labels. But sometimes, we don't have 100% of the labels, or we have labels but we aren't sure they're correct. That's when we dive into the other types of supervised learning.
- Strongly Supervised Learning — the usual ML
- Weakly Supervised Learning — the new ML
Strongly Supervised Learning (what you already know)
When learning about strongly supervised learning, we have data with labels. All the elements are labeled. This is Strongly Supervised Learning.

Of course, I'm insulting you with this image... and I'm about to do it once again by showing you Transfer Learning:
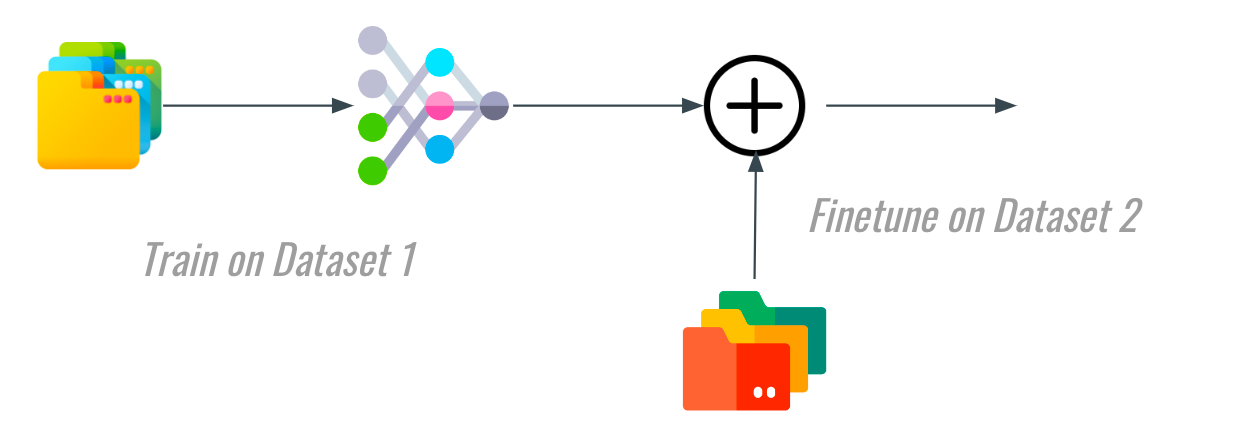
Transfer Learning is supervised learning, but we're now using 2 datasets, and transferring the knowledge learned on Dataset A to make the learning on Dataset B faster.
I'm showing you these basics because this started a trend in Machine Learning: training models faster!
And how do we train even faster? By reducing the time to label. Labeling a dataset is what cost the most amount of time.
When using 100% correctly labeled data, we are asking some people in third world countries to label entire datasets for days (I have been one of these people, no judging 👀).
Couldn't we use datasets with partial labels? Or even inaccurate ones?
We can! And this is what's behind the new ML type I want to talk about:
Weakly Supervised Learning
Weakly Supervised Learning happens when your labeled data is incomplete, inaccurate, or somewhat inexact, but can still be used to train a model.
To repeat, it's when the dataset is:
- Incomplete — we're missing some labels
- Inaccurate — some labels are noisy
- Inexact — some labels are wrong
The first case is when the labels are incomplete. For example, you may have a part of the data that isn't labeled, and so you'll ask an AI to solve the issue.
Incomplete Labels (Active Learning & Semi-Supervised Learning)

In practice, you may have a much bigger portion of your dataset that is unlabeled. You may even have the majority of it.
Usually, it's done using either Active Learning, or Semi-Supervised Learning.
- Active Learning is when the model selects examples with the least confidence score to be manually labeled by a human. The rest is labeled by the AI, the human is in the loop, and is basically helping with the difficult examples. You can learn more about it in this article.
- Semi-Supervised Learning is very similar. But it does the opposite: rather than selecting the least confidence score examples, it will select the high confidence examples and look for similar examples in the dataset.
While Active Learning is trying to make the human a part of the process, by selecting the least confidence scores, Semi-Supervised Learning will take the high-confidence samples, and then look for similar examples in the dataset. "If these 2 examples are 99% similar, and I have a label for one, I can assign the same label for the second one."
Now, what about the others case of weakly supervised learning? We just saw the case when we had incomplete labels, but we can also have noisy or inaccurate labels.
Inexact Labels (Multiple Instance Learning)
The second type of "weakly supervised" learning I want to describe is when the labels are noisy.
What does noisy means? Imagine you were asked to label students in a University as "Pass" or "Fail", and you of course have access to the grades. Students pass starting 50% good grades.
If you were looking at each student individually, you'd be spending HOURS doing it, and you would have a label for each student. But if you're looking at a "bag" of students, and just assigning one label for them, you're going much faster.
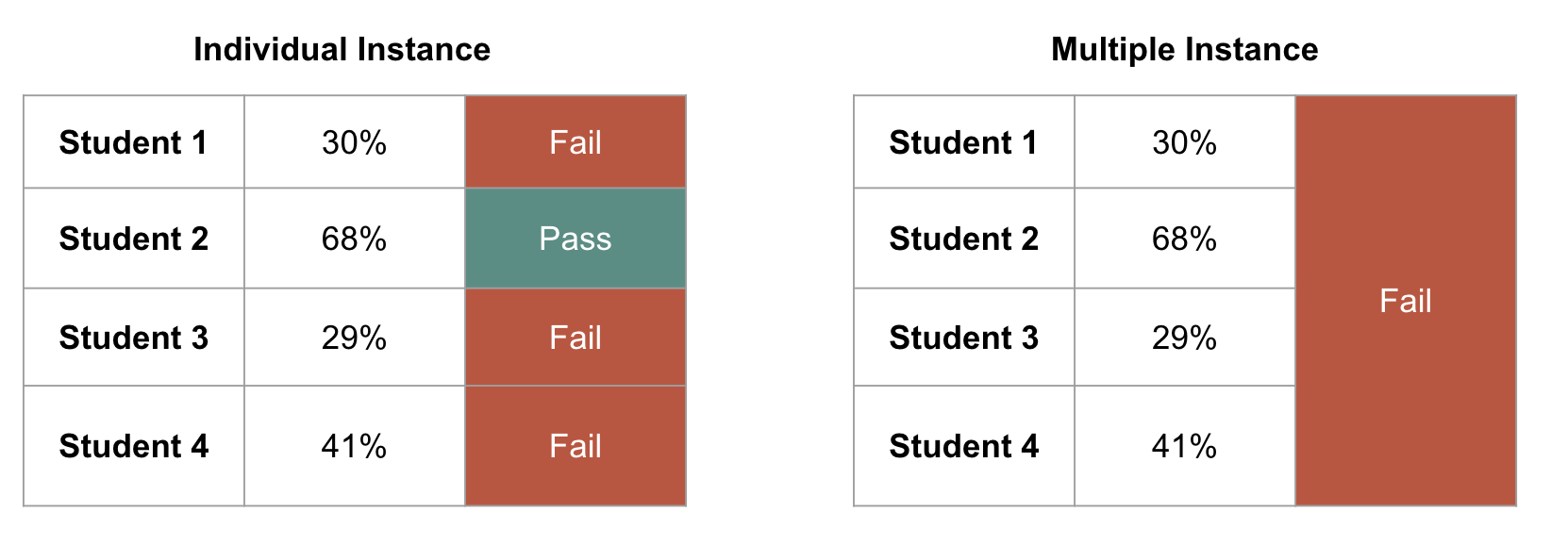
Rather than individual labels, you have bags of data. To be more specific, you have:
- Negative Bags — Full of negative samples
- Positive Bags — Containing at least one positive sample
Here is a Spam/Not Spam example of bags:
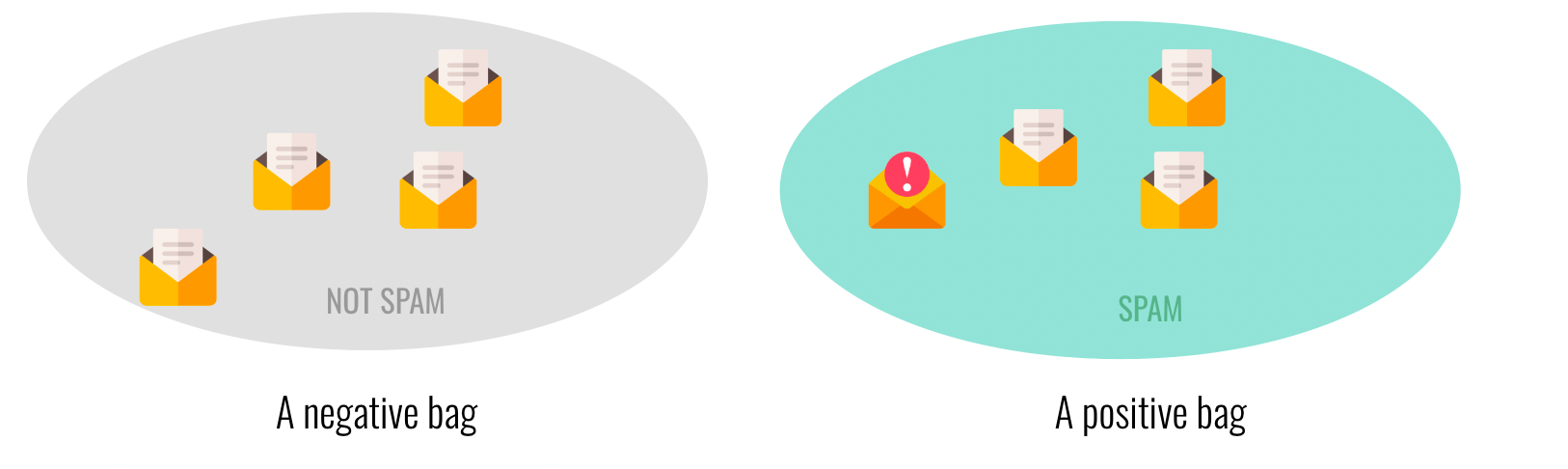
If you look at the bag in general, you'll notice that even though the "SPAM" item is alone, the others aren't far in the embedding space. They're negative, but they aren't really far from being positive. So we label the entire thing as positive.
In a classification example, it could give this:
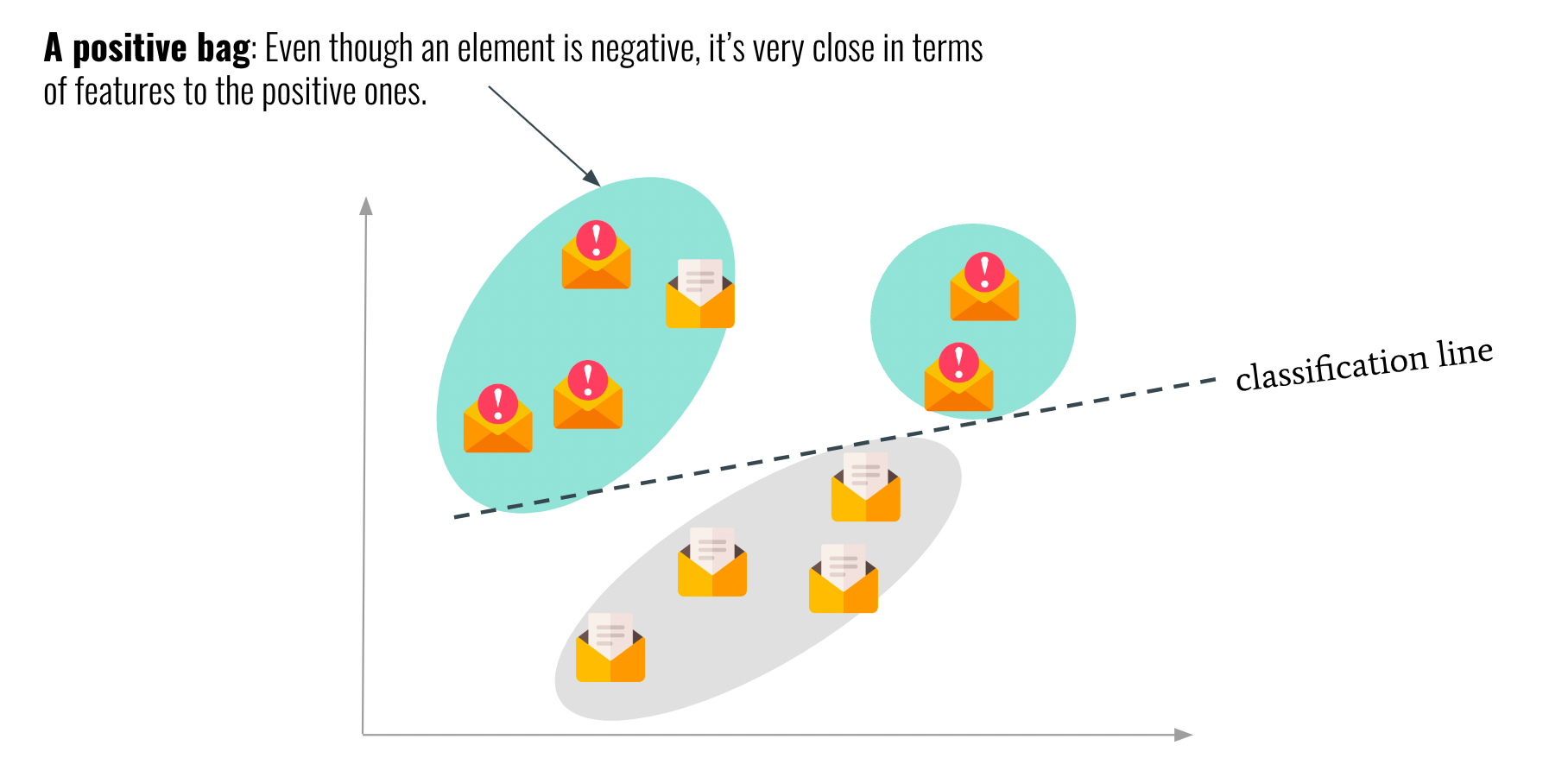
This entire field is called "Multiple Instance Learning" — and it's when you learn from bags, rather than individual instances.
Inaccurate Labels
Finally, we have "inaccurate" labeling, when some labels are false. This might be because you just scraped some data without really looking at individual elements, or just because you purchased a dataset that is known to contain some errors. The way to solve this is through identification of these false labels.
What you want to do is basically edit the dataset, by using models that will be trained to identify errors in the data. We call that data-editing.
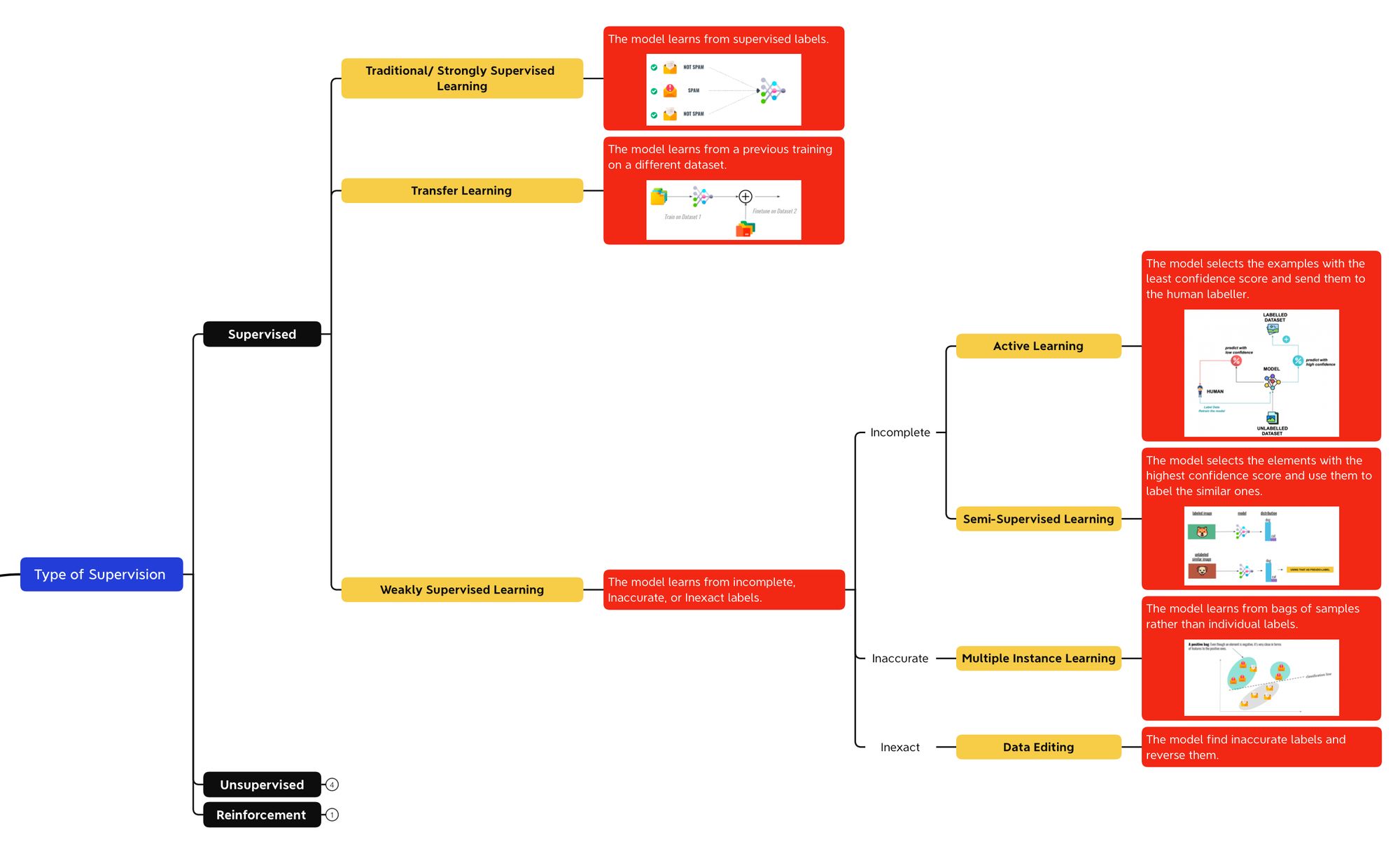
We've just seen a few elements of supervised learning:
- Fully Supervised Learning
- Transfer Learning
- Weakly Supervised Learning, including Active Learning, Semi-Supervised Learning, Multiple Instance Learning, and Data Editing.
Let's now look at unsupervised Learning.
Unsupervised Learning
The second type of supervision is unsupervised, and it happens when we have no labels.
Here, we have two types of unsupervised learning algorithms: fully unsupervised, and self-supervised.
Fully Unsupervised Learning
You probably know at least a bit the first type, that involves all the algorithms such as clustering, dimensionality reduction, outlier detection, principal component analysis, etc...
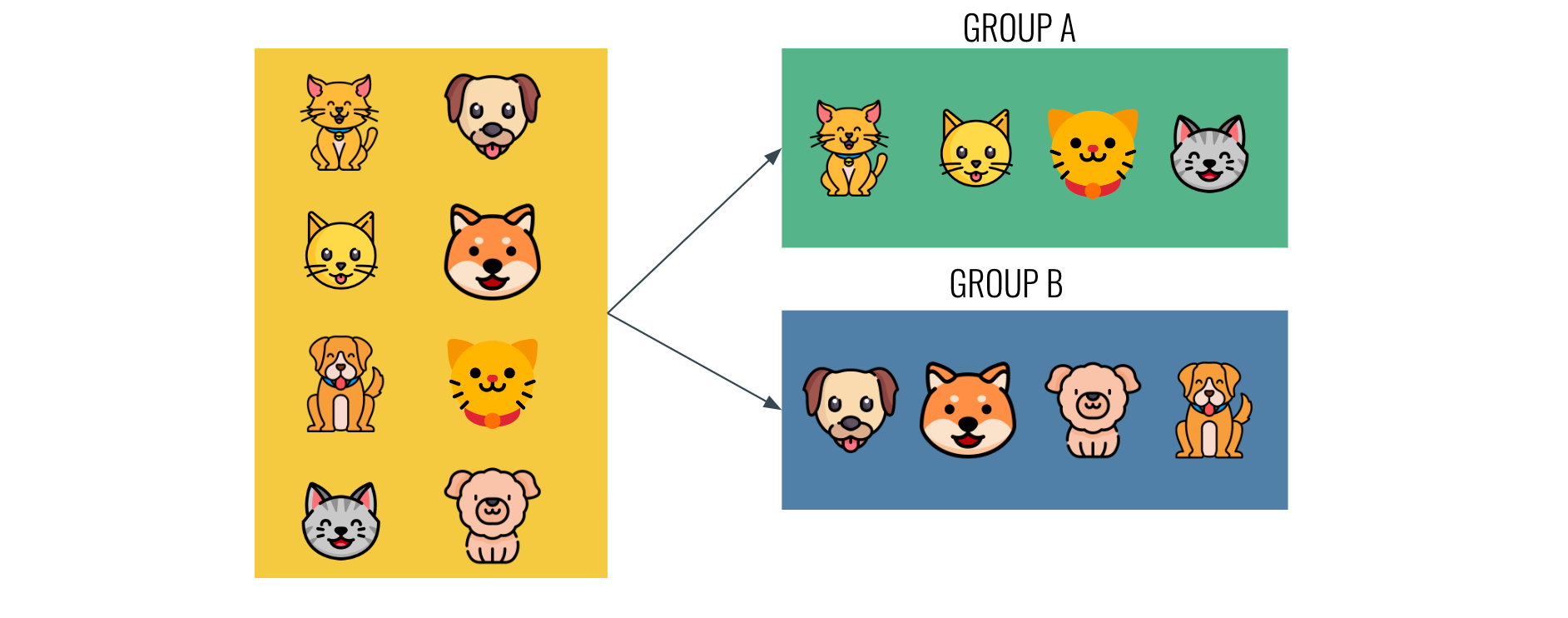
These are using distance calculation to separate examples based on how close the features are.
A more realistic example is 3D Drivable Area Segmentation, that I teach in my Point Clouds Fast course, and that is about finding the outliers in the point clouds to segment the ground.

These techniques perform well in these scenarios, but only solve the same type of problems: unsupervised learning problems!
This is why a second type of learning exist: Self-Supervised Learning.
Self-Supervised Learning
The idea of self-supervised learning is as follows: 99% of the data available is unlabeled, and we're not using it at all. But can't we get something out of it?
The idea of self-supervised learning is to learn "something" from the unlabeled data (by creating our own problem), and then finetune the model that learned on samples with labels.
It looks like this:
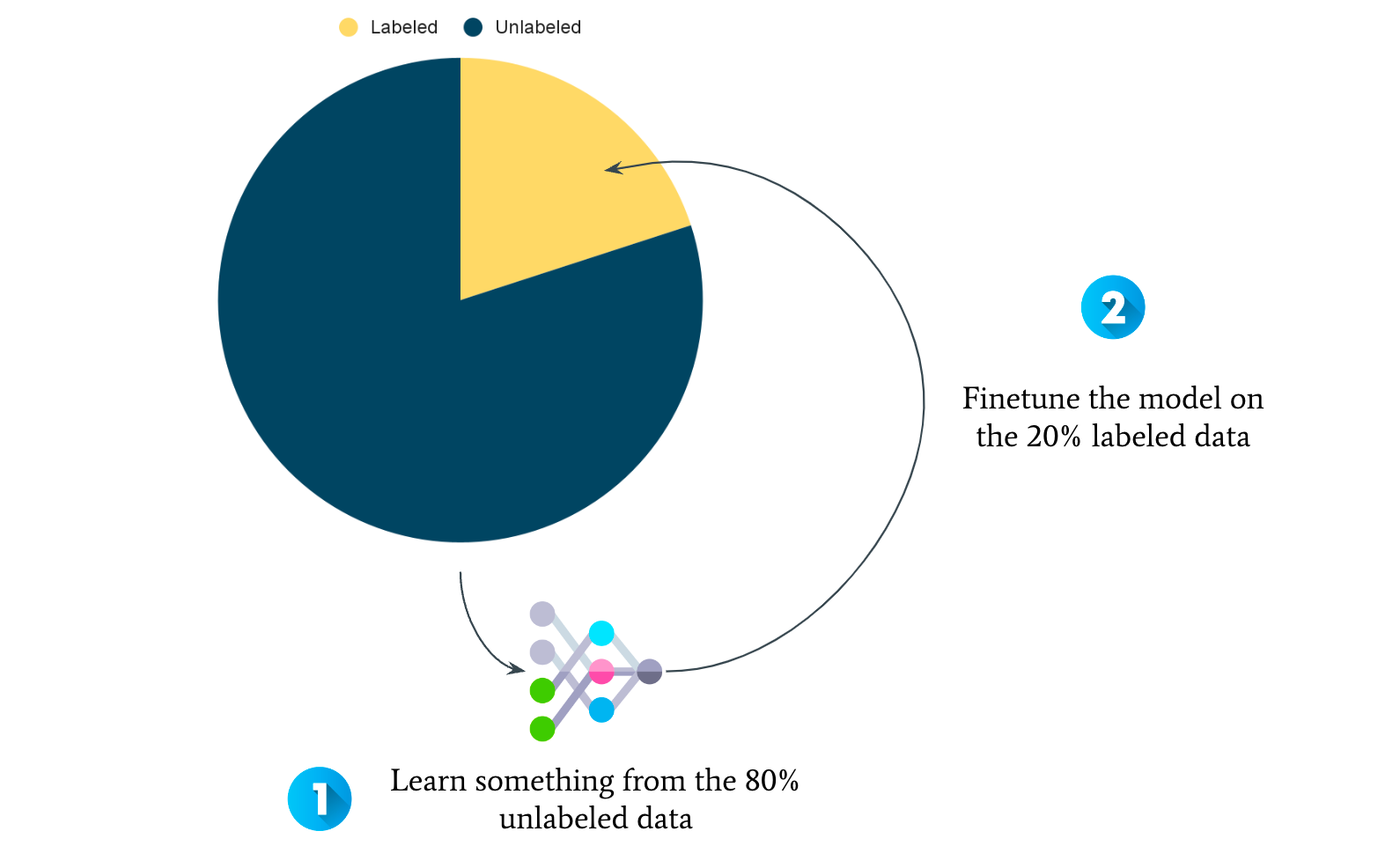
But how do we learn from an unlabeled dataset? By creating a pretext task.
Let's say you want to identify the age of someone from a picture; and you only have the age of 20% of your dataset.
How to learn from the 80%? By creating a pretext problem.
In the example below, I'm grabbing an unlabeled image, and create two labels from it: rotate +90° and rotate -90°:

We can now do that on the entire dataset, and train a model to classify the rotation of an image. By doing so, we're "learning" from the 80% of unlabeled data.
Once we have a model that can predict between two classes, we can feed it with pictures of me labeled, and finetune this model with labels (for example, to predict my age).
Reinforcement Learning
I'll skip it for this article, next time pal.
Summary of the Types of Supervision
Classification #2: Moment of Learning
So what are these moments of learning? I found that there are 2: online and offline.
Offline Learning
Offline Learning is when you're training your model once, on a fixed dataset. It's how most of the Machine Learning algorithms are trained.
The other way would be Online Learning.
Online Learning
Here, we have two types:
- Incremental Learning
- Federated Learning
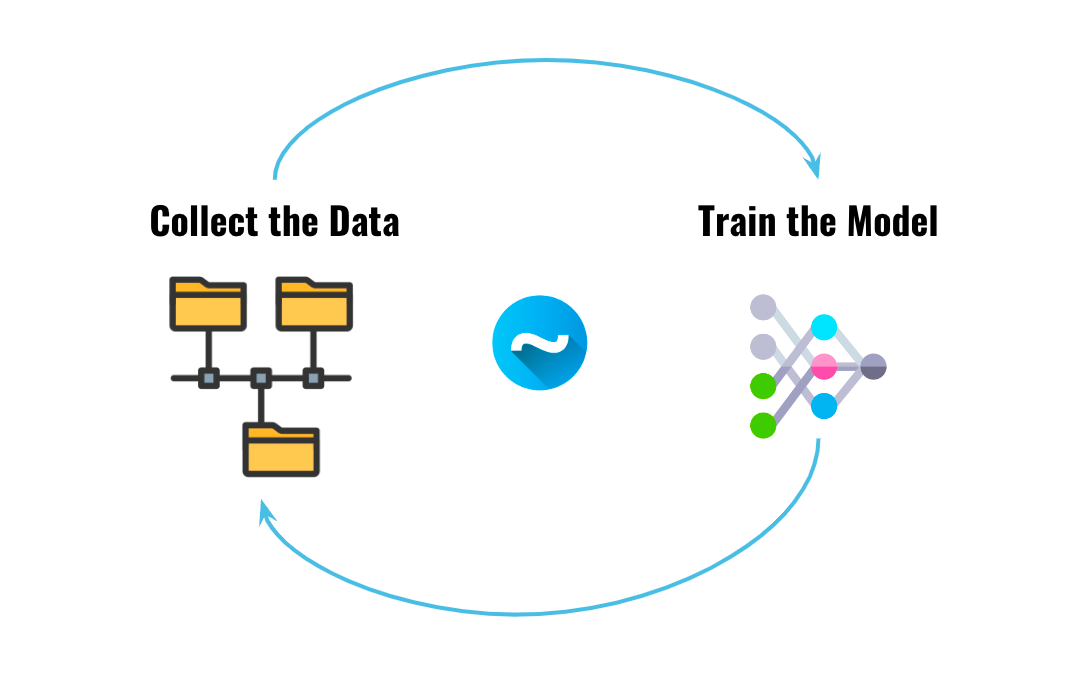
Incremental / Lifelong / Continual Learning
The first type is as follows, we're always training the model and pushing to production. The data stream is continuous, learning never stops.
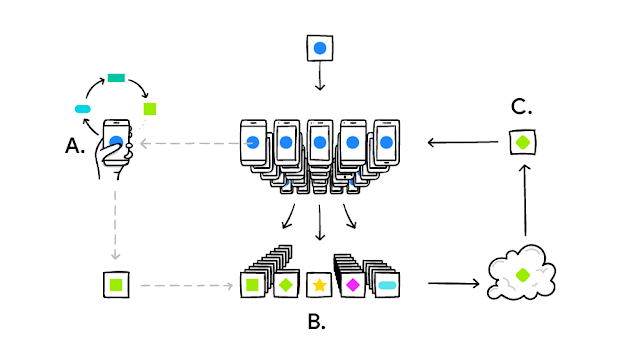
Federated Learning
On the other hand, Federated Learning is about training a model across several devices.
Think "Hey Siri!" — You're training a model on the data on your phone. The data stays on your phone, but the trained model gets uploaded to iCloud. In parallel:, millions of phones are doing the same. An aggregated version of all the trained model is then pushed to your phone, and downloaded...
Summary of the Moments of Learning
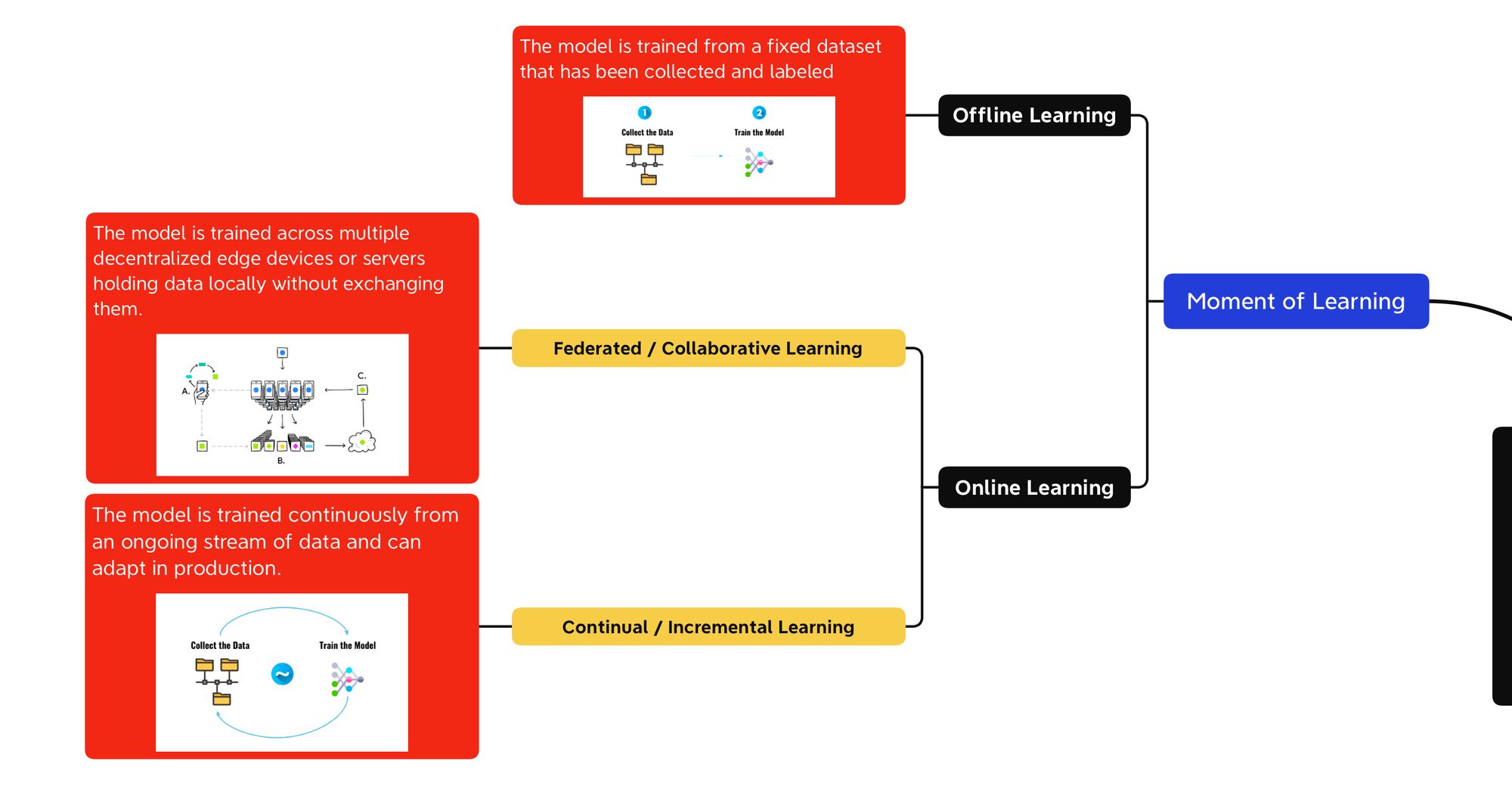
The nice thing about seeing Machine Learning this way is that an algorithm can be supervised and online or unsupervised and continual.
Finally:
Classification #3: Tasks
Finally, we have the tasks. Yes, classification, regression, that. Back when I started learning Machine Learning, I only heard 3:
- Classification
- Regression
- Clustering
But Today? Today?
We have many more tasks — so here's what we'll see in this final part:
- Single-Task vs Multi-Task Learning
- Contrastive Learning
- Meta Learning
- Adversarial Learning
- N-Shot Learning
You feel like this is going to be really long? Don't worry, it won't.
Single Task vs Multi-Task Learning
One of my most popular online courses is called "Hydranets", and it's teaching how to create a neural network that have several heads (like a hydra). In practice, this can help solve tasks that require the same kind of feature extraction over and over again.
For example, rather than stacking similar models, like this:
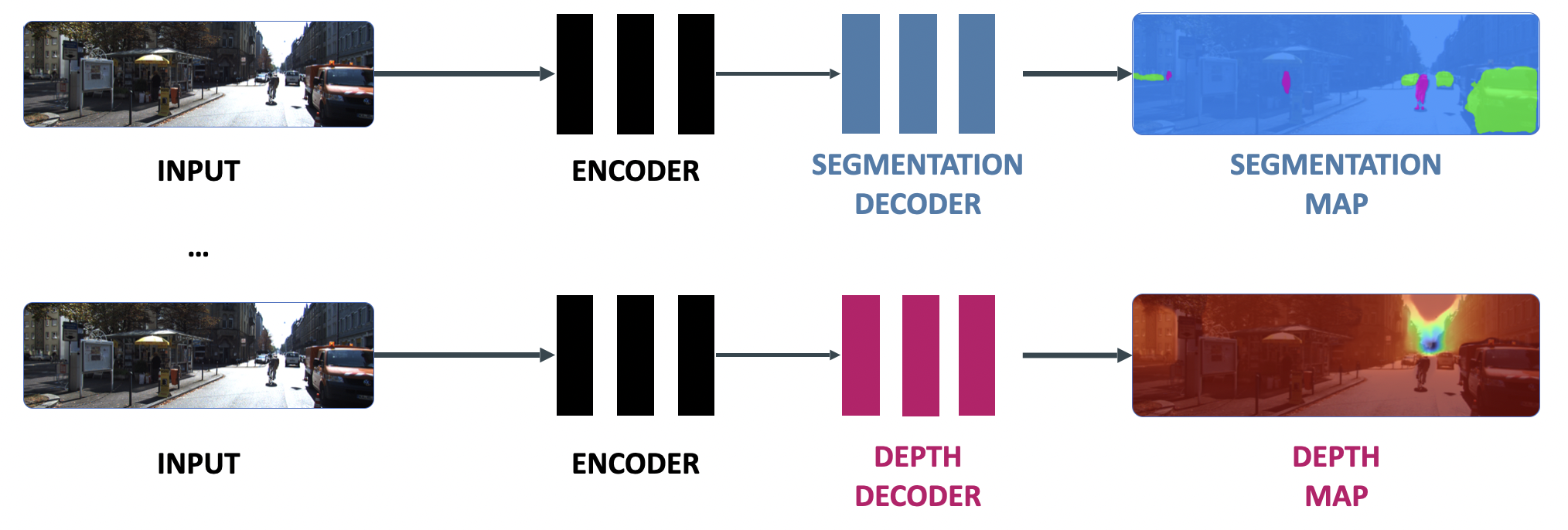
We're creating a single model that can do both tasks (or more):
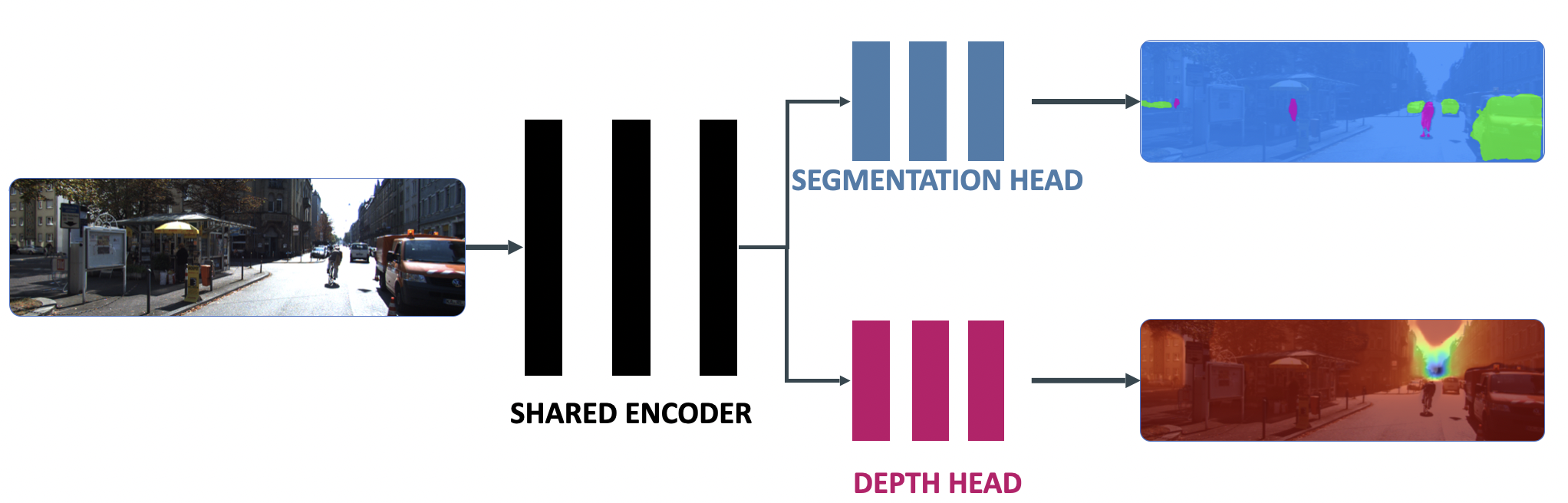
We're gaining a lot of inference time and memory by not repeating the encoder part. More info in my course.
Contrastive Learning
Do you remember when I talked about creating a pretext task just to learn something? What we were doing was actually pushing features in the embedding space.
Take a look at the following image:
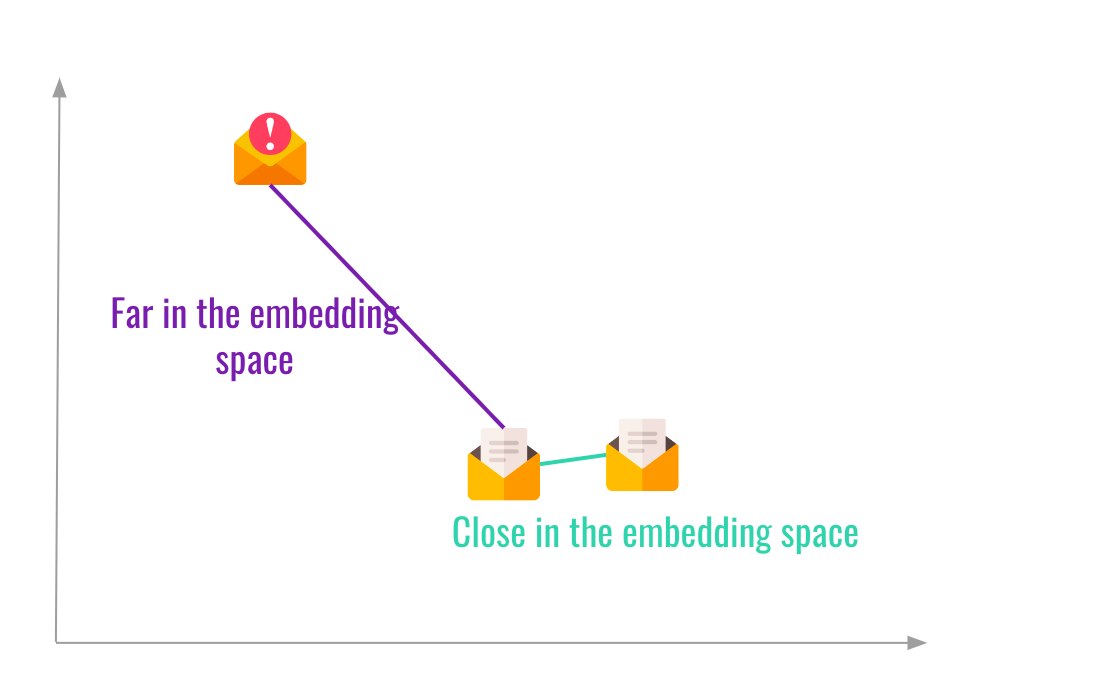
This is how all Machine Learning algorithms work! They learn from features, and the features are more or less distant.
The idea of Contrastive Learning is at the foundation of face recognition, or tracking, where we're teaching models to get similar faces close together in the embedding space.
N-Shot Learning
Because we're on the topic of face recognition. Did you ever wonder how face recognition algorithms could recognize your face after just seeing one picture of you?
Don't you need thousands of examples? Well, no, because you're doing something called One-Shot Learning.
One Shot Learning
The idea is as follows: After pushing features in the embedding space, you want to get new data and tell how similar or dissimilar it is.
An example from my course MASTER OBSTACLE TRACKING, where I teach how Siamese Networks work:
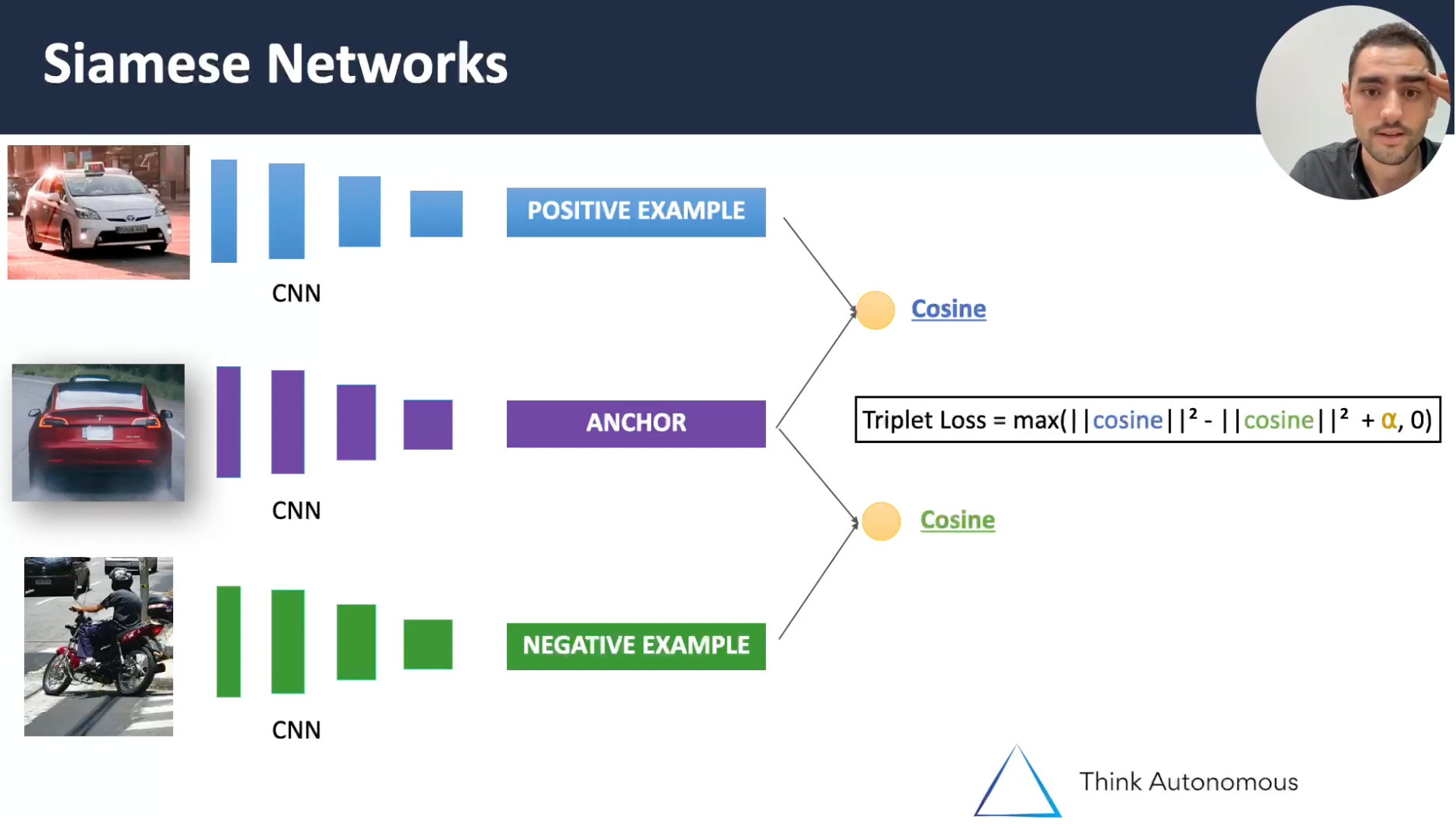
The main idea: for every new pair, we run it through a feature extractor, and check how far or close the features are from our target. We therefore only need to run the algorithm once.
Other examples of N-Shot Learning exists, such as Zero-Shot Learning, or Many-Shot Learning, and this is about never seeing a single example, or only seeing it a few times.
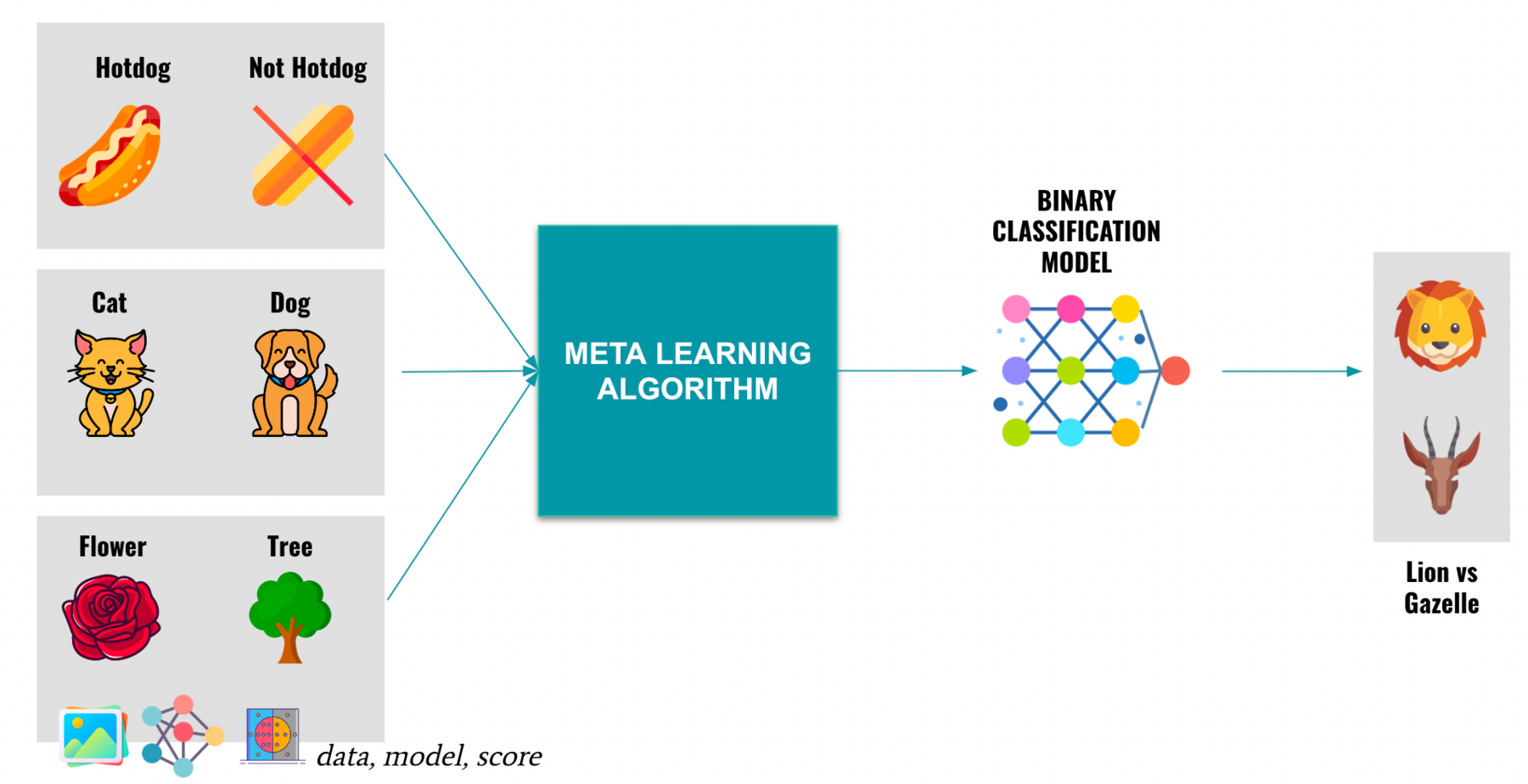
Meta Learning
Next, Meta Learning means learning about learning. I have an entire article about it here.
Here is a recap image, where we're using several examples to learn "Binary Classification" rather than learning a specific classification example.
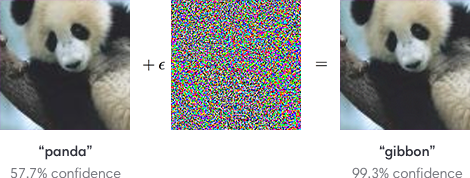
Adversarial Learning
Finally, adversarial learning is about learning to fool algorithms. We're designing systems to attack machine learning models, and we're designing models to defend against these attacks:
Summary — 19 Types of Machine Learning Algorithms
We have just seen lots of ways to classify Machine Learning in 2022. Let's do a short summary:
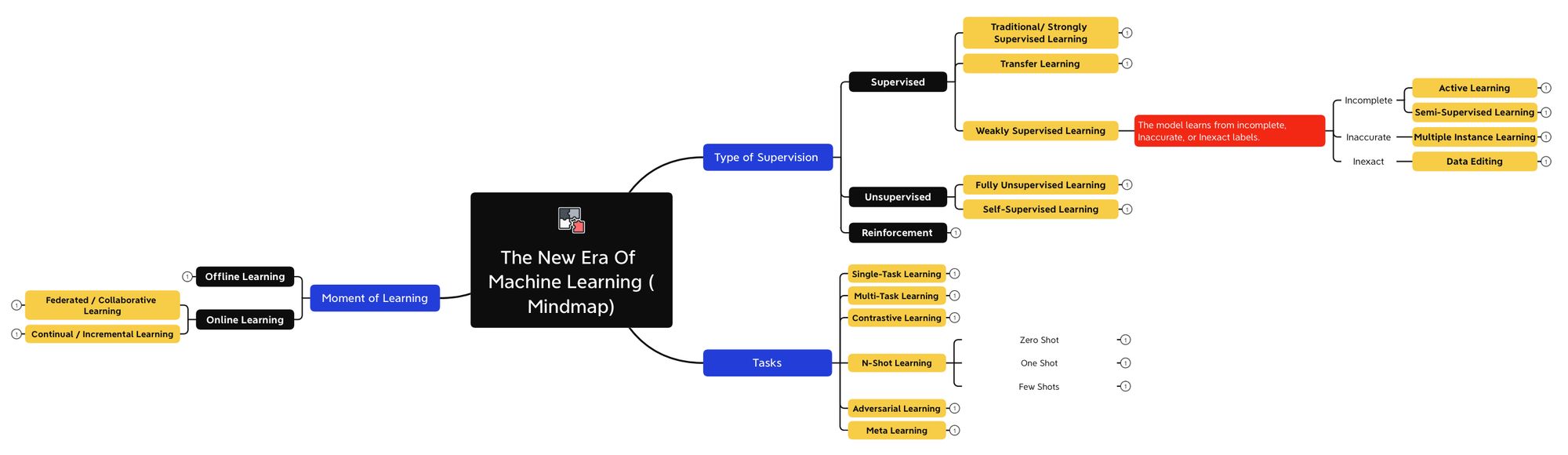
We've just learned about 19 Types of Machine Learning systems, while you started from 3!
Bonus Video
Here is a recap of the Mindmap via video:
⏬ Download the Mindmap here




