

Modular vs End To End: How to pick an autonomous vehicle architecture
In 2018, TV producer Jon Favreau, known for his role as "Happy" in the movie Iron Man, embarked on an ambitious project to produce the highly anticipated TV show, The Mandalorian, set to premiere on Disney+.
Everything was supposed to go smoothly, until the team encountered a significant issue on Day 1 of visual production. Indeed, they realized that The Mandalorian will be wearing a beskar armor, which contains a high level of reflections. Therefore, shooting the movie using green screens, which were the de-facto technique in filmmaking, would compromise realism, and show green reflections everywhere on the helmet.
This setback prompted Favreau and his team to seek an alternative solution: Virtual Sets; circular rooms where every wall and ceiling is made of a rotating LED screen. This innovative approach not only ensures that the projected scene contained the true colors and reflections but also proved to be a cost-effective and actor-friendly solution.

With the implementation of Virtual Sets, Favreau and his team created one of the best TV show in the Star Wars Universe, and popularized a new production technique that would be reused in other shows like Obi-Wan Kenobi. Today, it's said that LED screens are going to replace green screens in filmmaking. They provide a better immersion for the actors, but also give better lightning, realism, while being significantly cheaper.
Self-Driving Cars are very similar to filmmaking. They have the very traditional and universally approved 'green screen' technique. I call it the "4 Pillar" architecture — and a relatively new and 'LED screen' type of architecture called "End-To-End".
Over the years, we've seen companies debating over which architecture should be used, some claiming that End-To-End could replace the 4 Pillar architectures. In this article, I'm going to describe the two ways of building an autonomous vehicle system architecture, and give my opinion on the future of self-driving car software.
The 4 Pillars of Self-Driving Cars
If you have taken my course "THE SELF-DRIVING CAR ENGINEER SYSTEM", you know that this course introduces you to one type of architecture I call the 4 Pillars.
Here's how it works, at a simple level:
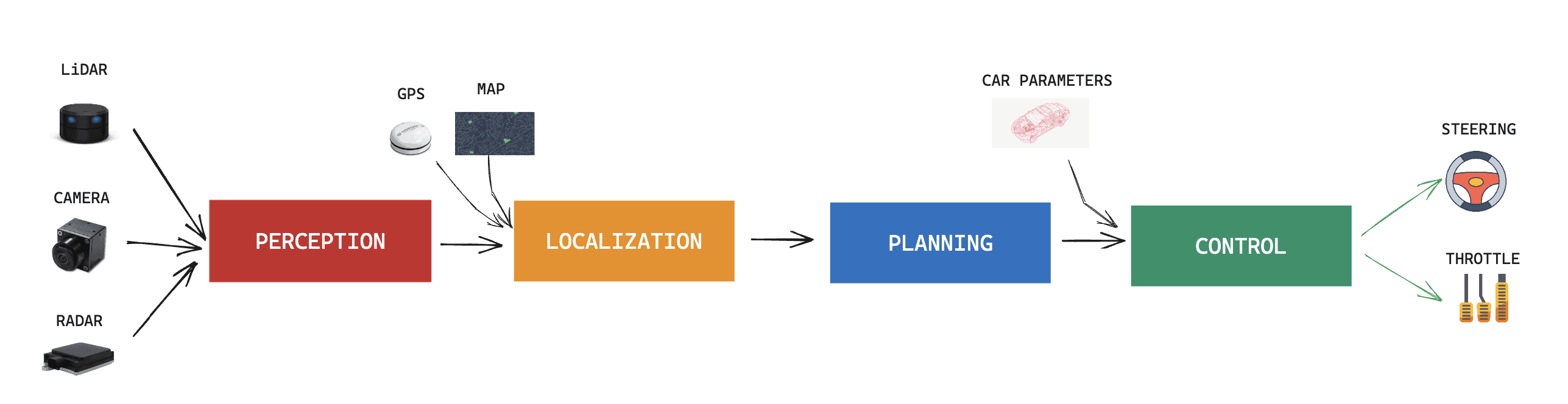
So it's all very linear, and we have the output of one being the input of the next one. This architecture is probably the most universally known, accepted, and used for an autonomous driving system.
The 4 Pillars are:
- Perception: We use a set of vehicle sensors, such as cameras, LiDARs, RADARs, ultrasonics, and more... and we perceive the world.
- Localization: We take the output of Perception, a GPS, and a map, and localize ourselves in the world
- Planning: From the obstacles around, and from our position, we plan a trajectory from A to B
- Control: Using the trajectory information, and the vehicle parameters (weight, tire size, etc...), the control system generates a steering angle, and acceleration value.
This is how 99% of self-driving cars and autonomous robots drive. Is it not? The automotive industry has adopted this architecture, and when adding more details, it can look like this:
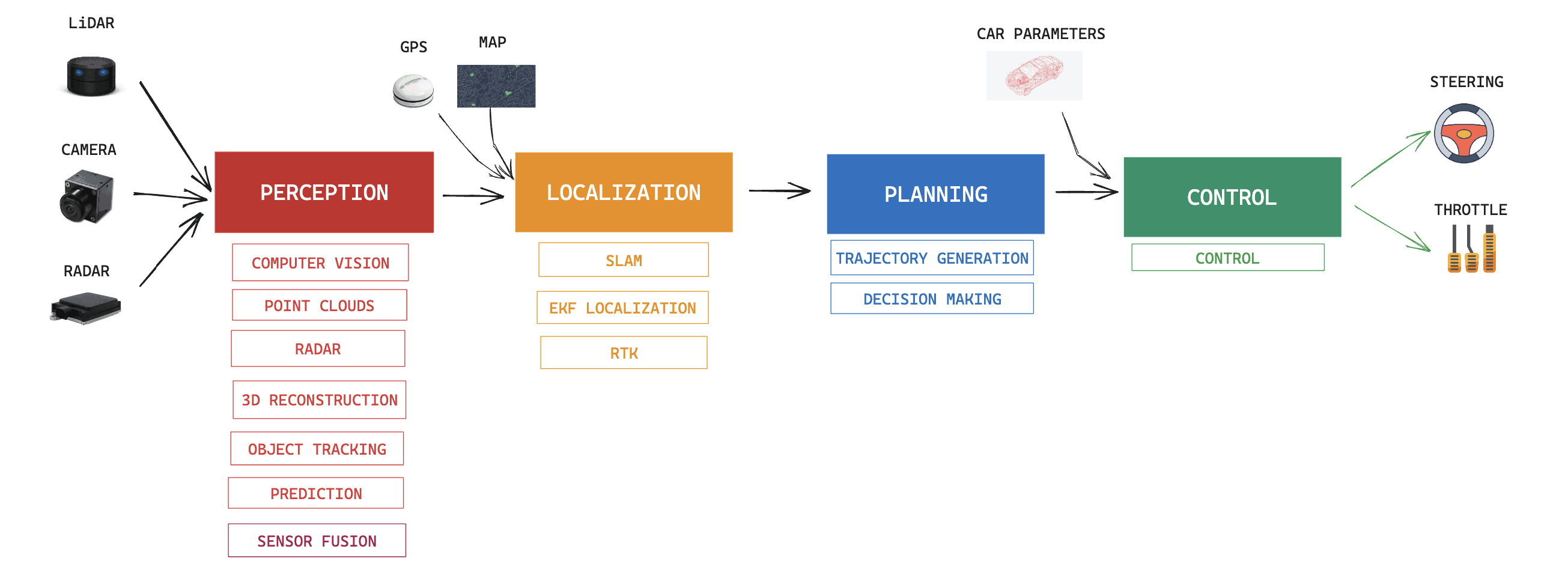
And this is just the tip of the iceberg. When you "zoom in" again, you can see Computer Vision broken down to pedestrian detection, traffic lights, data management, ... and planning broken down to path planning, trajectory generation, etc...
Yet, you may have learned these 4 pillars in a different order, or with different names. The first time I learned about the 4 pillars, prediction was part of the "planning" step. But then, when I learned it from other sources, it belonged to Perception. So I placed it in Perception, because it made sense to me. I sometimes learned about 3 pillars, where "localization" belonged to Perception too, and sometimes, there was no "control".
So which one is right or wrong? I guess we'll never know. And it also depends on what companies want to implement. The only, real, always here, two steps are Perception (see the world) and Planning (plan a trajectory).
So, let's see some examples.
Examples of 4 Pillars Architectures
To begin, a warning.
The 4 Pillars aren't exactly the same to all autonomous vehicles. In fact, every company has developed its own "4 Pillars", and there's a lot of variation. I sometimes learned about 3 pillars, where "localization" belonged to Perception, and sometimes, there was no "control".
Let's first see Waymo, who popularized the 4 pillars in autonomous vehicles.
Waymo and the absence of Localization
A first example we could look at is Waymo. This company is one of the pioneers of self-driving cars, it's highly "classical" and traditional; and yet, it doesn't follow the 4 pillars (that they invented).
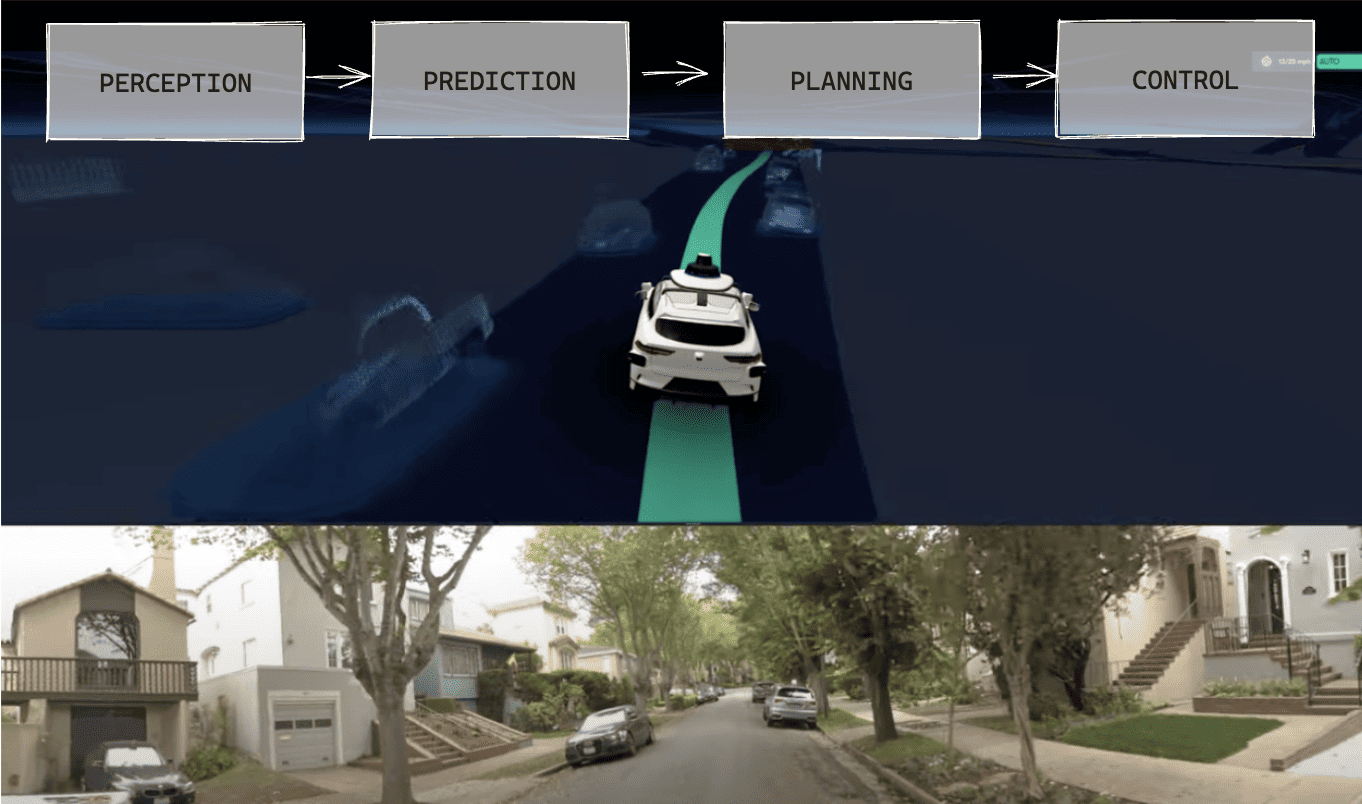
This is because Waymo evolved their development process significantly around "prediction", with many research papers being published since CVPR 2020 around this topic. In fact, at CVPR 2023, one of the 5 papers Waymo published was called MoDAR (Motion Forecasting for LiDAR), and another was was called Motion Diffuser (which involves using Diffusion to predict motion).
Apollo White and the 7 Pillars
In China, there's a company named Baidu that released an open source software named Apollo. The idea is, if you use the exact sensor configuration they give you, you can download their software components, and have access to fully autonomous vehicle.
Because it's all open source, so is their architecture. Here it is:

Notice how they have the 4 main pillars, but 3 others:
- Map Engine
- Prediction
- HMI (Human Machine Interface)
They also have their own "ROS" middleware, called Cyber RT.
What's interesting is that this is version 8.0, but version 1.0 worked very differently: it used ROS, and didn't even have a Perception system. It was a simple... GPS Waypoint Following for parking lots!

Does naming matters?
You can see how Waymo is focused so much on Prediction that it even squeezes the idea of localization. Companies like Zoox follow this pattern. Some other companies like Cruise or Aurora will be super focus on Sensor Fusion, and therefore, they might have one of their pillar named after it.
In reality, this doesn't really matter. What matters is that the 4 Pillar architecture (or 3, or 5, or alternate 4), is implementing the modules block by block. A team is working on Perception, another on Localization, another on Planning, another on Controls, etc... as if they were independent systems.
On the other hand, there are companies who do it all-in-one. You have the sensor, then one algorithm, and you have your output. These are called the End-To-End drivers...
End-To-End Architectures
End-To-End architectures work differently: the main idea is to feed all your inputs to a single algorithm, that directly outputs the driving policy. So let's see what it looks like:
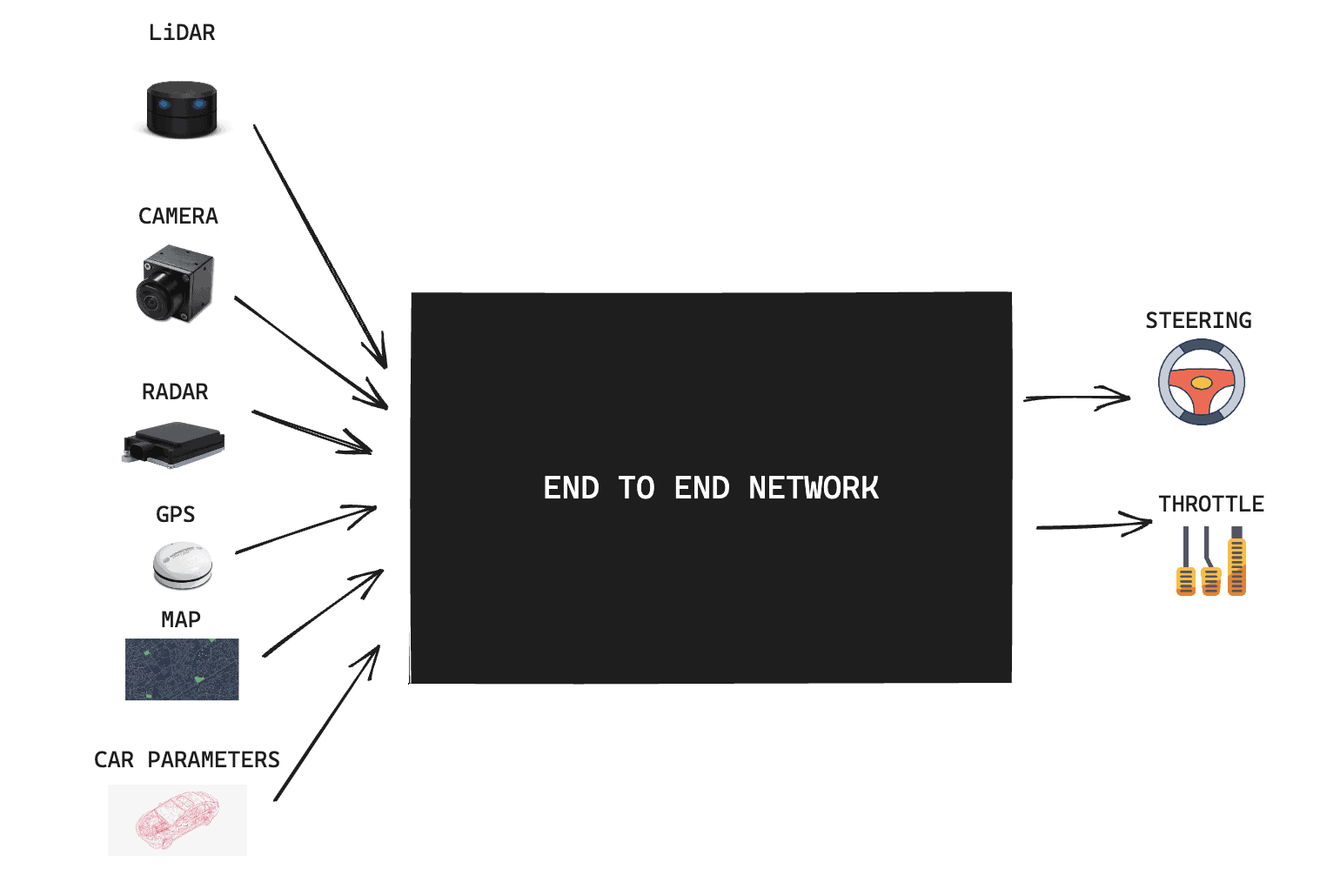
Of course, millions of questions raise immediately. What's inside that box? Does it really work? Is it really all Deep Learning??? Shouldn't the output be a bit different?
Let's first go back to the roots...
End-To-End Creed: Origins
The first time this type of architecture became popular, it was in 2016 when Nvidia released a paper called "End-To-End Deep Learning for self-driving cars". The paper was a 9 layer CNN that took one camera image as input, and output a steering angle and acceleration.
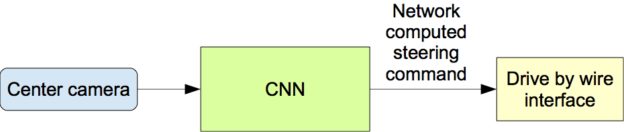
This type of project became insanely popular with students who all started their "self-driving car project" in the Udacity simulator; including me.
How the architecture evolved
Since the Nvidia paper, a few self-driving car startups (but just a few) have tried the end-to-end approach.
Comma.ai
Companies like Comma.ai started by claiming that the best thing to build was an end-to-end planner (e2e). In case you don't know them — comma.ai is selling a smartphone that can be plugged to your car and make it autonomous using the cameras. The approach is described here.
However, in their e2e planner, rather than outputting an angle and acceleration, they output a trajectory represented by x, y and z coordinates in meters — and this linked to a controller.

To be clear, this isn't the same End-To-End as I described earlier... it's a hybrid! We still have blocks communicating together, like vision and planning, but the overall thing is trained end-to-end; meaning without much "rules" in place. Most of the training is done in simulators, and the idea is to then scale the learning to any road.
Next, let's see another approach... the Wayve!
Wayve & End-To-End Reinforcement Learning
There's a company in London called "Wayve", and this company creates and end-to-end algorithm based on Reinforcement Learning. The idea is incredibly complex, yet it can be summarized in one picture.
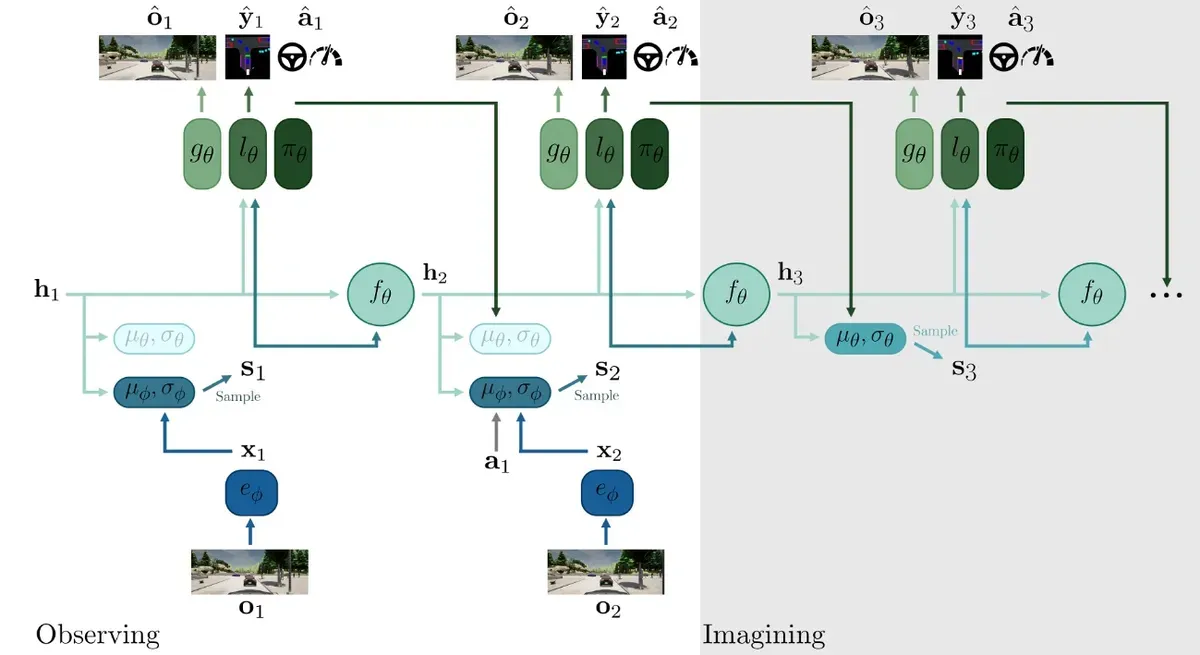
The architecture is called 'MILE' (Model-based Imitation LEarning), and here, you're looking at two observations o1 and o2, and an imagination o3 (which is a future prediction). Each observation is sent to an inference model e, which then goes to 3 models that do observation posterior, labels, and action.
I recommend to read the paper linked with the image, but the point is... when you train this whole thing on CARLA simulator, it generates this:
Incredible, isn't it?
Is End-to-End really End-To-End?
No. In fact, I would say besides the Nvidia model, they're all hybrid. They all, at some point, open the black box, include rules, break down blocks into smaller blocks, etc...
So this mean there are actually 3 categories:
- 4 Pillars
- Pure End-To-End
- Hybrid
Today, you will probably see most "pure end to end" approaches are research projects, self-racing cars, lane following robots, etc... But I suspect the goal of Hybrid E2E companies is to transition to pure E2E. On the other hand, any automated driving system, or robot, or something with multiple sensors will go 4 Pillars.
Conclusion: End-To-End vs 4 Pillars
Back when I started Think Autonomous, which teaches engineers how to build skills in self-driving cars and autonomous tech, I was told I should start a podcast. I was then told I should create a course on Udemy. I was also told to start a YouTube channel, to keep a self-driving car job, and to use TikTok.
I did none of those things. Instead, I started a daily newsletter, that is today read by over 10,000 people every day; and I later added a blog. I could easily have transitioned at the start, but I didn't. Instead, I made the email newsletter approach work.
You pick an approach, and you then make it work. Take for example Tesla and LiDARs. Originally, Tesla started by being against the use of LiDARs in autonomous driving. It was very hard to implement a Computer Vision only approach, but instead of going back, they "made it work".
How to know which one to pick? There are a few rules you can follow, such as:
- If you don't have access to big simulation, go with the 4 Pillars.
- If your products are made for environments where the clients want tons of robustness, safety, go with 4 pillars.
- If your team has more expertise in Sensor Fusion, LiDARs, and Traditional Controllers, go with 4 pillars.
- If your team doesn't involve many researchers, and it would be easier for you to use a predefined path, go with 4 pillars.
On the other hand, if you:
- Have access to abundant data, processing power, or simulation
- Have many Deep Learning researchers in the team
- Are a bit of a contrarian, and are looking for a way to stand out
Then you could always explore end to end approaches.
So, now let's do a summary.
Summary & Next Steps
- When building an self-driving car software architecture, there are usually two approaches to use: the 4 Pillars and End-To-End.
- The 4 Pillars of autonomous vehicles are Perception, Localization, Planning, and Control. It all starts with Perception, which is about "seeing", and the data is then passed to localization, to trajectory planning, and finally to controllers.
- Some vehicle manufacturers and startups will invent their own "4 Pillars" based on where they put their focus, like Waymo & Prediction. However, it's all the same idea, with blocks communicating with eachother.
- End-to-End Learning is about feeding input data to a model that directly outputs a driving policy (3D Trajectory, or a duo throttle/steering angle). The approach was pioneered by Nvidia in 2016.
- Companies like Wayve or Comma.ai work heavily on End-To-End Planning, and both approaches currently work — but being somewhat hybrid.
- If you're hesitating between which approach to build, go with 4 Pillars; if you know, you know.




