

How Aurora uses Deep Learning for Sensor Fusion and Motion Prediction
In the self-driving car game, every company has its champion. Google has Waymo, GM has Cruise, Intel has mobileye, Aptiv has nuTonomy, and Amazon has Zoox and Aurora.Every acquisition is strategically filling positions and solving needs, such as autonomous delivery, trucking, highway driving, elderly transportation, last mile delivery, and more.Aurora is playing 3 different games at the same time:
- Trucking
- Delivery
- Robotaxis
Let's take a brief look at what their products look like:

In this article, I'd like to take a look at Amazon's unicorn Aurora. In particular, we'll study the technology behind it, and how it solves the robotaxi problem. For that, we'll focus on two key aspects: Sensor Fusion and Motion Planning. Sensor Fusion is how companies collect data using sensors, and fuse them into a specific output. Motion Prediction is how the vehicle use that output to predict trajectories of the vehicles in time. What you'll see is that Aurora is before everything a Deep Learning startup, and doesn't hesitate to include Neural Networks everywhere; including in these two tasks.
Aurora's Sensor Fusion Module
Most of the companies doing sensor fusion are using either an early fusion approach, fusing raw data coming from different sensors, or a late fusion approach, fusing objects at a later time with a Kalman Filter.
Aurora is using the Early Sensor Fusion approach. It fuses LiDAR point clouds with camera images and RADAR point clouds. Then, it performs detection and other operations on the fused result.All using Deep Learning.
Considering this, I have a question for you: How would YOU do Sensor Fusion if you were to use Deep Learning?
What are the exact steps you'd take? How would you fuse LiDAR point clouds with camera images using a Neural Network? Take a minute, think about it, and note your answers somewhere.
In Aurora's approach, data is coming from the 3 sensors I mentioned, plus an HD Map.

Before we consider fusing anything, let's list the coordinate frames of each sensor data:
- The HD Map is in 3D Map Frame.
- The RADAR Point Clouds are in a 3D RADAR Frame.
- The LiDAR Point Clouds are in the 3D LiDAR Frame, and that can be projected to 2D
- The Cameras are producing 2D images, but we have images from multiple cameras that can be combined.
We therefore know that LiDAR can be projected in 2D, and therefore fused with the 2D cameras. We also know that images can be projected to 3D and fused with LiDARs and RADARs.
Let's begin by implementing these steps.
Step 1 — Raw Data ProjectionsHere's how the first step works:
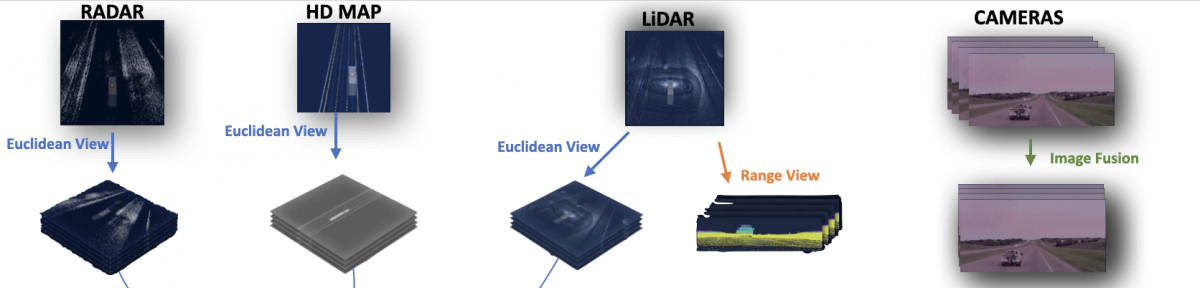
As you can see, LiDAR, HD Map, and RADAR are all projected into something called an Euclidean View. That view is nothing more than a 3D representation of the data. On the right, the camera images are all fused together into an Image View, while the LiDAR is also projected in a 2D Range View.
This step is also called Sensor To Tensor, because we convert all the data into a format that will be common, and since we'll process these into CNNs, it's called a Tensor.Now are now ready to fuse the results and extract features.
Step 2 — Feature Extraction
Next, we are going to run Convolutional Neural Networks on these 3 spaces.
Take a look at the following picture:
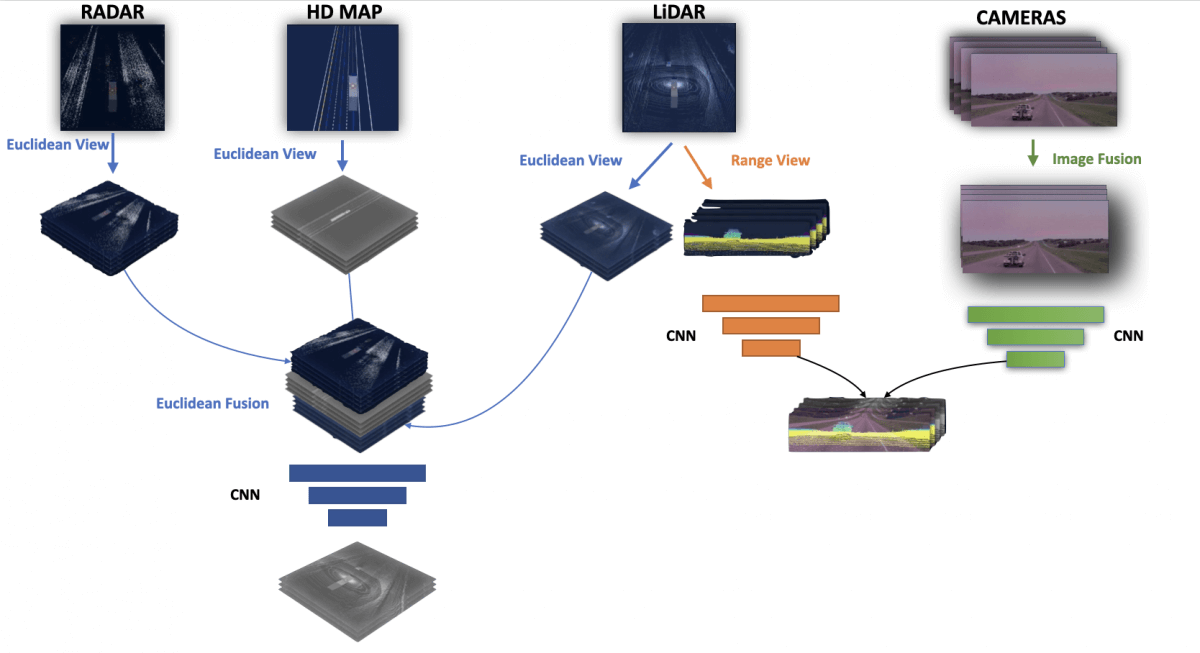
- On the left part of the image, you can see that all euclidean views have been fused and then processed by a neural network.
- On the right part of the image, you can see that we ran neural nets on the 2D LiDAR View (range view) and the Fused Image View, and then we fused the outputs (to do some sort of LiDAR/Camera fusion).
👉 By the way, every time I say fused, you can understand "concatenate".
So this is how Fusion happens on the 3 layers; the fusion is done by concatenating whatever we want to fuse that is in the same coordinate frame, and the extraction is done by running a few convolutional layers.
We now have features on the euclidean, range, and image views. Now, try to take a second and answer the following question: What information does each of the two outputs provide?Here's how Aurora explains it:
- On the left part (euclidean view), we have extracted the 3D position from the LiDAR, the velocity from the RADAR, and an adjustment with the HD Maps.
- On the right part (range/image view), we have fused pixels with point clouds, so we have the depth of each pixel!
Step 3 — Final Fusion
We are now ready to fuse these 2 parts. The only problem is that the left part (all 3) are in 3D while the right part (LiDAR/Camera) is in 2D. We'll therefore need to project the 2D Space in the 3D Euclidean View, and finally combine everything again and run a few convolutions to finish.

Et voilà!
In the process, we have projected data in specific frames, and then used CNNs to extract the features. This is a learned approach, so the CNNs are trainable.
Here's the final image:
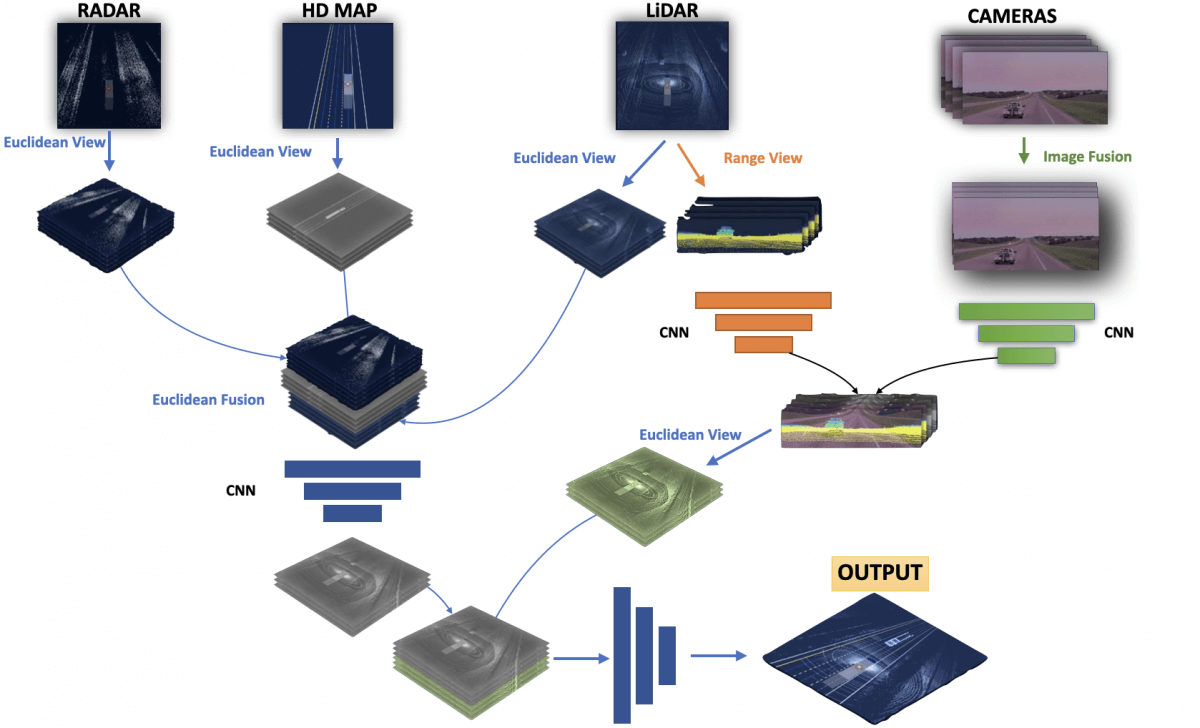
I hope that... well that you understood it!
Let's take a look at the result!

👉 If you'd like to learn more about Sensor Fusion, how the actual projections are done, and how to build skills in 3D, I have a dedicated course on it here. Next, let's see how Motion Prediction works.
BONUS : If you're interested in Deep Learning for Self-Driving Cars, I have created a Deep Learning MindMap that will explain to you every use of Deep Learning in every step of the implementation. The point is, there is much more than Sensor Fusion and Prediction.
📩 To download the mindmap , I invite you to join the daily emails and receive my cutting-edge content on Self-Driving Cars and Deep Learning! Here
Motion Prediction with Deep Learning
Next, let's talk about Prediction. In particular about how Aurora, a self-driving car startup, is doing forecasting using Graph Neural Netwoks.
Are you ready?
A quick intro — What is Prediction?
Prediction belongs to the Planning step, which is one of the 4 pillars of autonomous driving, along with Perception, Localization, and Control.

The Sensor Fusion module we've just seen was included in the Perception step. Some very precise GPS called RTK GPS give us the localization step. The Planning step is implementing the brain of an autonomous vehicle, deciding on the trajectory from A to B. Finally, the control step will be in charge of making the vehicle follow the trajectory.
This step includes High Level Planning (what Google Maps or Waze is doing on a big map) and Low-Level Planning (Decision-Making, Prediction/Forecasting of objects, Trajectory Generation, ...).Prediction is therefore on low-level planning.
Generally, these steps happen after:
- We've detected all our obstacles and positioned them in a 3D Map.
- We've estimated our position in this same map.Since we know how the Perception step works, and since we assume we have a correct localization system, we can directly study Aurora's Motion Prediction system!
In this step, Aurora is doing 3 things to predict trajectories:
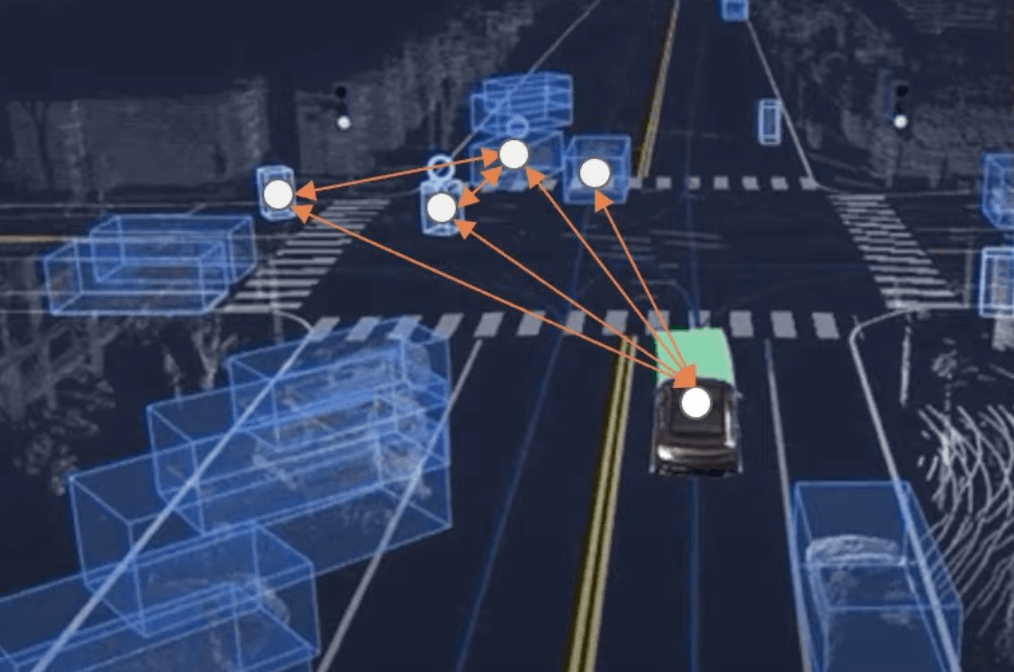
Step 1 —They consider that each obstacle is a node in a graph.
Take the following scene where obstacles have been detected. Notice how we include only the elements that directly impact our trajectory in the graph. We can also represent the connections between the obstacles.
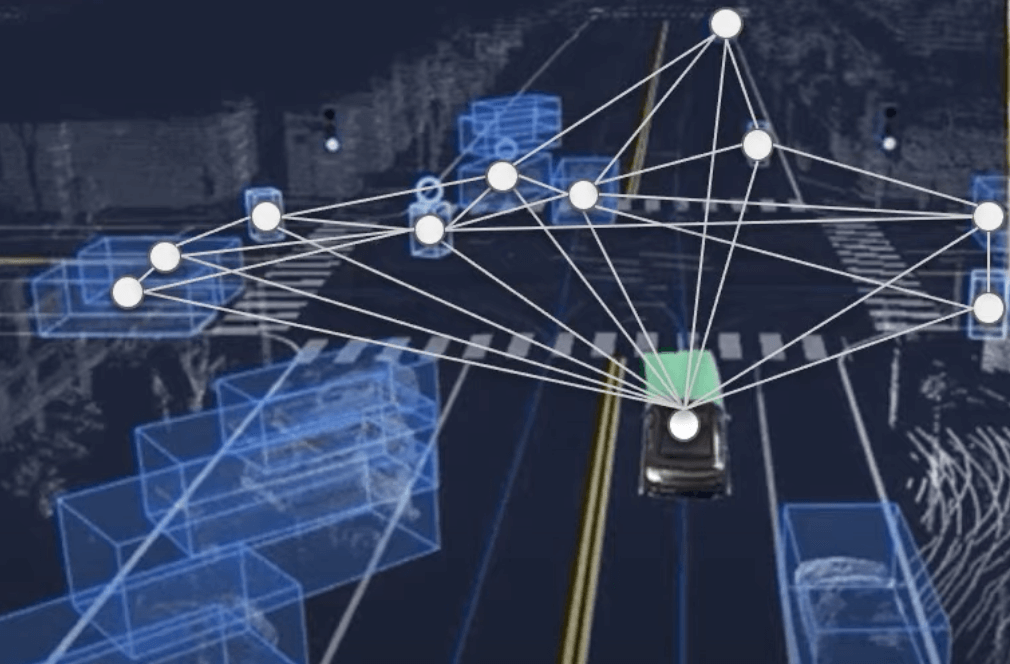
This gives us the complete Graph representation of the situation.
To understand why a graph is relevant, let's take this unprotected left turn example.
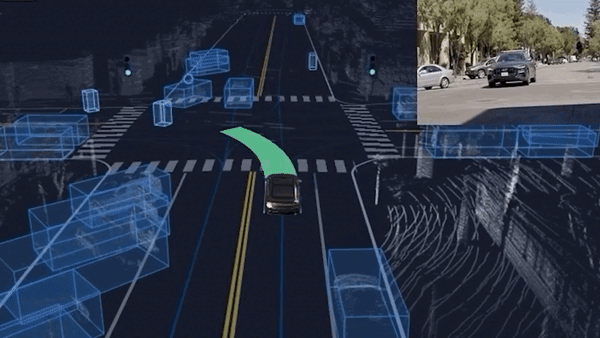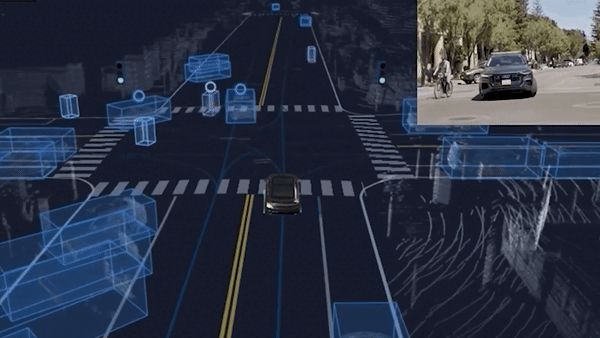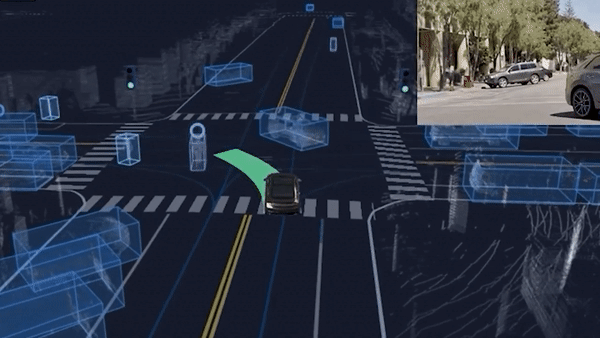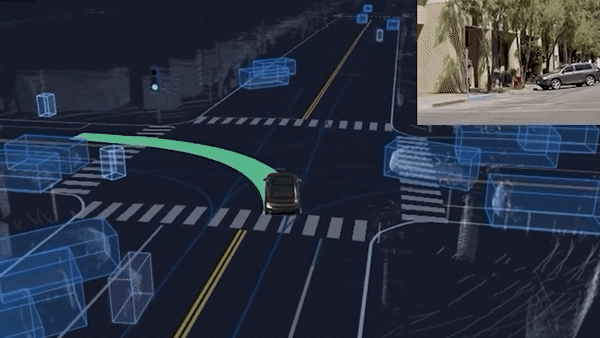
Do you realize how complex this scene is? The ego car is yielding to 3 or 4 obstacles; but these obstacles are themselves yielding to a pedestrian crossing and other obstacles! We are not only impacted by nearby obstacles, but also by the obstacles that are impactingt these obstacles!
This is what leads us to step 2.
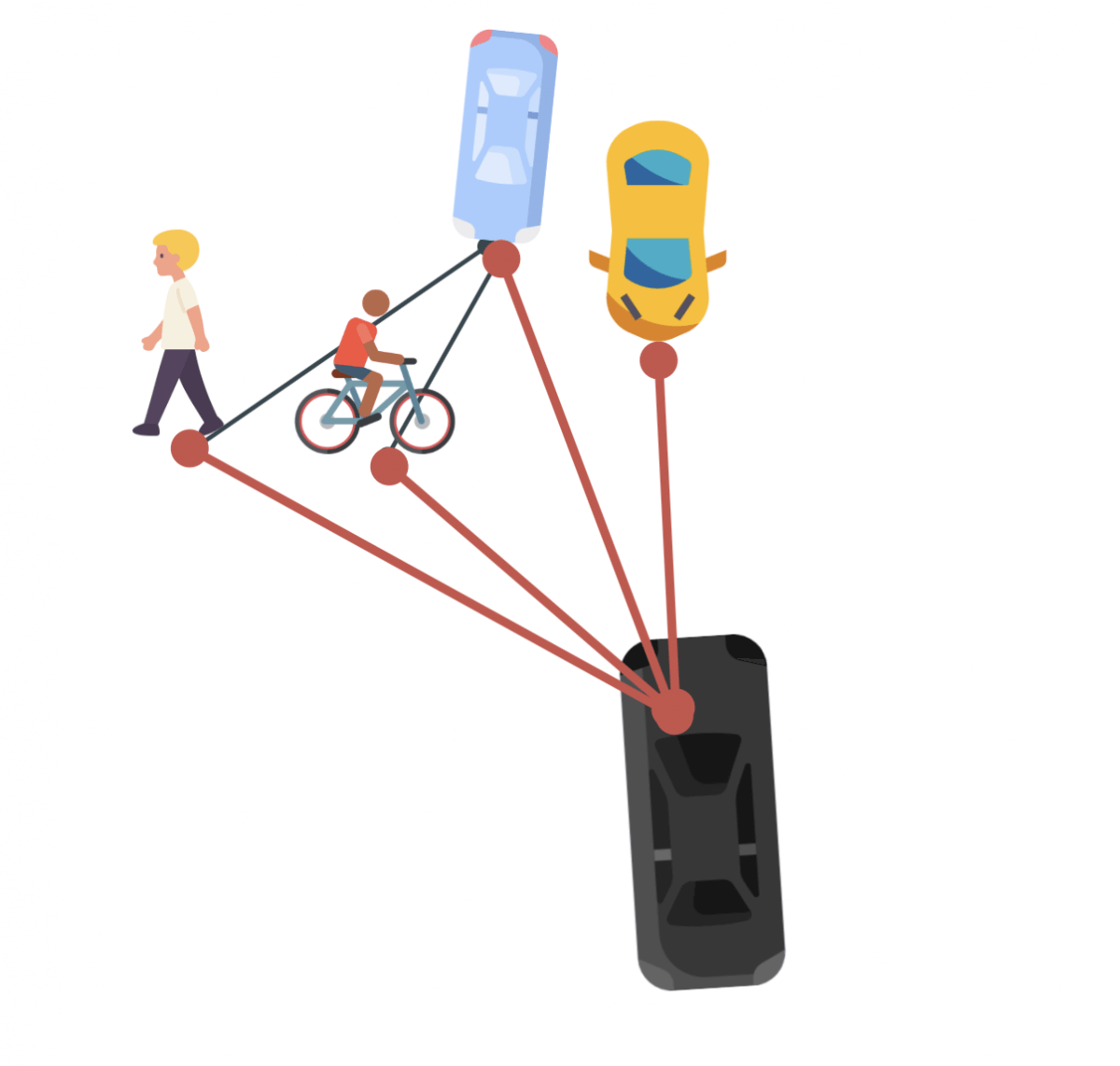
Step 2 — A Graph Convolutional Network defines which nodes impact us.
Once we have converted the scene into a graph, we can narrow it down to keep only what's directly and indirectly impacting us.
And here is what the graph becomes.
Notice how the edges are drawn between the vehicles that are connected to eachother, but not between the vehicles that aren't impacting eachother. This is the power of using GCN (Graph Convolutional Networks).
Finally, we must predict what each vehicle will do in the near future, and decide whether to stop or continue.
3 — A multi-agent tracker holds probabilities for every obstacle
Any planning system will hold probabilities for every agent. In this example, we know we're on a highway with 3 lanes, so we'll store that information in a table with probabilities for each agent/lane.
(source)
When we focus on the car highlighted in white, we can see that it corresponds to the bottom row. And this row is shifting its probabilities as soon as it detects that the car is changing lane, even if that move is forbidden by the solid line!
Thanks to these 3 elements, we can decide whether we keep driving or stop the car!
A note — The images for this second part have been taken from this video on Aurora's Youtube channel.
How far can Aurora get?
We've just seen that in the race to autonomous cars, Aurora is a serious player.
- First, they play in multiple games at once, doing robotaxis, trucking, and delivery robots.
- Second, they are super advanced Deep Learning players, using neural networks in Sensor Fusion and Path Planning, two areas where the majority of companies are sticking to traditional approaches.
Sensor Fusion is a process that happens by fusing LiDAR, Cameras and RADARs together with HD Maps, all using Deep Learning. For that, all 3 sensors are fused together in a 3D View, while LiDARs and Cameras are fused together in a 2D view, before being projected to 3D and re-fused.Motion Prediction is a process that generates obstacles trajectories autonomously. For that, Aurora is using Graph Convolutional Networks (GCNs) to understand how each obstacle interacts with the environment. Then, probabilities are estimated to estimate the future positions, and therefore decide on what to do.
👉🏼 If you'd read so far, you're probably interested to learn Sensor Fusion, Deep Learning, Computer Vision, and anything related to AI and Self-Driving Cars.
To get further, I invite you to receive my daily emails, sent everyday to thousands of aspiring cutting-edge engineers like you. There is a lot of new and advanced information on this entire field, every single day! To receive the emails, it's happening here.



