

Introduction to Video Processing
Computer vision, at its core, is about understanding images. The field has seen rapid growth over the last few years, especially due to deep learning and the ability to detect obstacles, segment images, or extract relevant context from a given scene.
Using computer vision, we can build autonomous cars, smart buildings, fashion recommender systems, augmented reality tools…the possibilities are endless.
One area in particular is starting to garner more attention: Video. Most applications of computer vision today center on images, with less focus on sequences of images (i.e. video frames).
Video allows for deeper situational understanding, because sequences of images provide new information about action. For example, we can track an obstacle through a sequence of images and understand its behavior to predict the next move. We can track a human pose, and understand the action taken with action classification.
When analyzing videos, we create new use cases and move from “this image contains 3 people” to “this image contains 3 people playing X”.
📩 Before we start, I invite you to join the mailing list by leaving you email! This is the most efficient way to understand autonomous tech in depth and join the industry faster than anyone else.
Obstacle tracking & video analysis — An active area of research
Whether for surveillance camera systems or football analysis, the next generation of computer vision algorithms will include time.
The task of video surveillance involves two kind of algorithms:
- Object tracking
- Action classification
Let’s have a look at both. At the end of this article, you’ll have a more complete picture of video analysis systems.
1. Object Tracking
A video is a set of frames. When studying a video, we can either study a video stream (live image feed) or a video sequence (fixed-length video).
- In a video stream, we consider the current image and the previous ones.
- In a video sequence, we have access to the full video, from the first image to the last.
Videos take up a lot of storage space and are usually not already using AI. This means that, with video, we simply have raw image data to work with.
But there is a key difference. Specifically, motion. Motion is the only difference between an image and a video. It’s a powerful thing to track and can lead to action understanding, pose estimation, or movement tracking.
Optical Flow
In video analysis, this key problem is called optical flow estimation. Optical flow is the idea of computing a pixel shift between two frames. This is handled as a correspondence problem, as illustrated in the following image:

The output optical flow is a vector of movement between frame 1 and frame 2. It looks like this:

A lot of existing datasets address the optical flow problem, such as KITTI Vision Benchmark Suite or MPI Sintel . They both contain ground truth optical flow data, which is generally hard to get from more popular datasets.
To solve the optical flow problem, convolutional neural networks can help.
FlowNet is an example of a CNN designed for optical flow tasks, and it can output the optical flow from two frames.
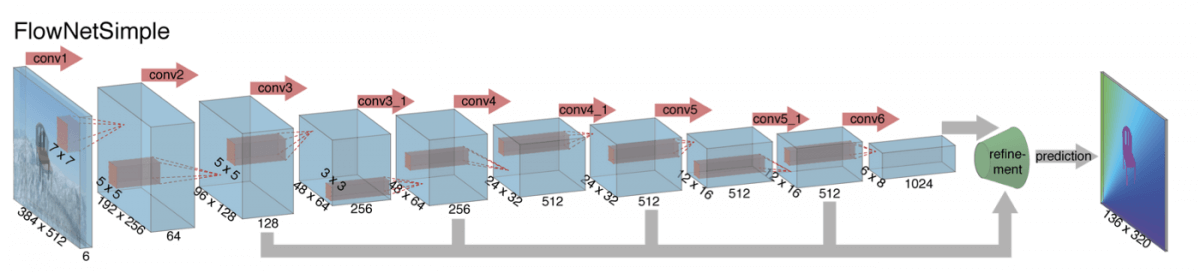
The input of the network is a set of two RGB images; thus it has a depth of 6.
Optical flow is often represented by colors.
The first problem we want to solve is understanding the movement of pixels from one frame to another. Optical flow estimations can be done in a video stream or a video sequence. A classification of the output vectors can then be inferred to understand movement.
Visual Object Tracking (VOT)
First, we can simply track objects. Visual Object Tracking (VOT) is the science of tracking an object given its position in frame 1. We are not using a detection algorithm here—thus, we’re model free. In other words, we don’t know what we are tracking. We are simply given a starter bounding box and are asked to keep track of this object all along.
Tracking is performed by computing the similarity between frames 0 and 1. We check what’s in the bounding box and try to retrieve it in the next frame.
We can then move the bounding box a bit and track our obstacles.
Other features, such as color, can also be used to track the objects. Here, we compute the color of the given object and then compute the background that represents the closest color to the object. Then we remove it from our original image to track it.


This is a very powerful technique, and it only uses computer vision. We don’t need a single neural network to do this. To summarize this process:
- We receive the initial object to track using a bounding box
- We compute a color histogram of this object
- We compute the color of the background (near the object)
- We remove the object color from the total image
- We now have a color-based obstacle tracker
To find datasets for this task, check out votchallenge.net
The next step is to apply CNNs for this task
We must distinguish two main models here: MDNet and GOTURN.
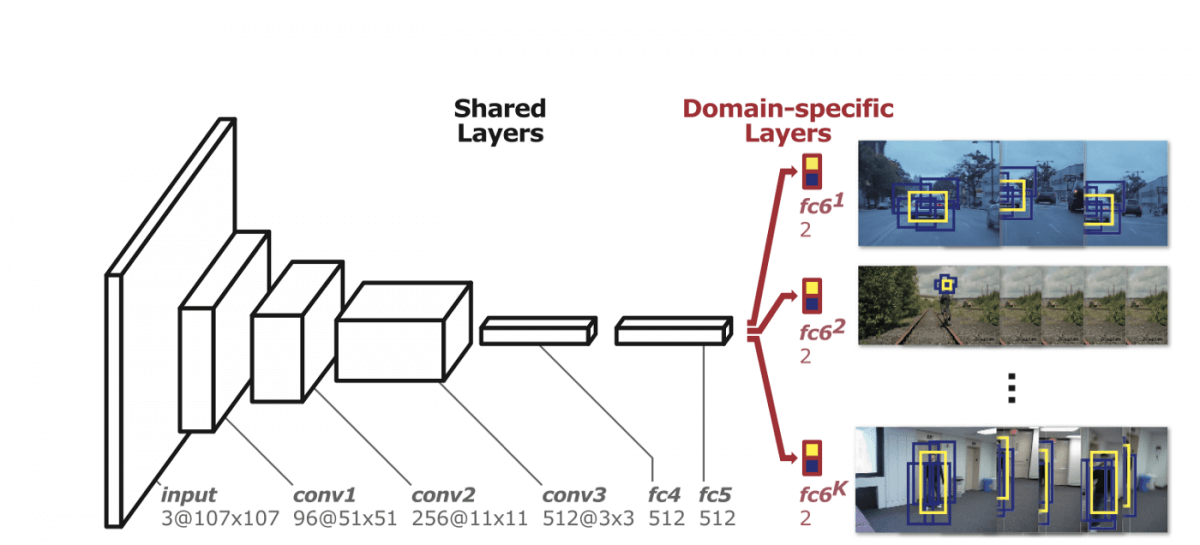
An MDNet (Multi-Domain Net) tracker trains a neural network to distinguish between an object and the background.
The architecture looks like a VGG model—in the end, we have domain-specific layers (object vs background classifier).
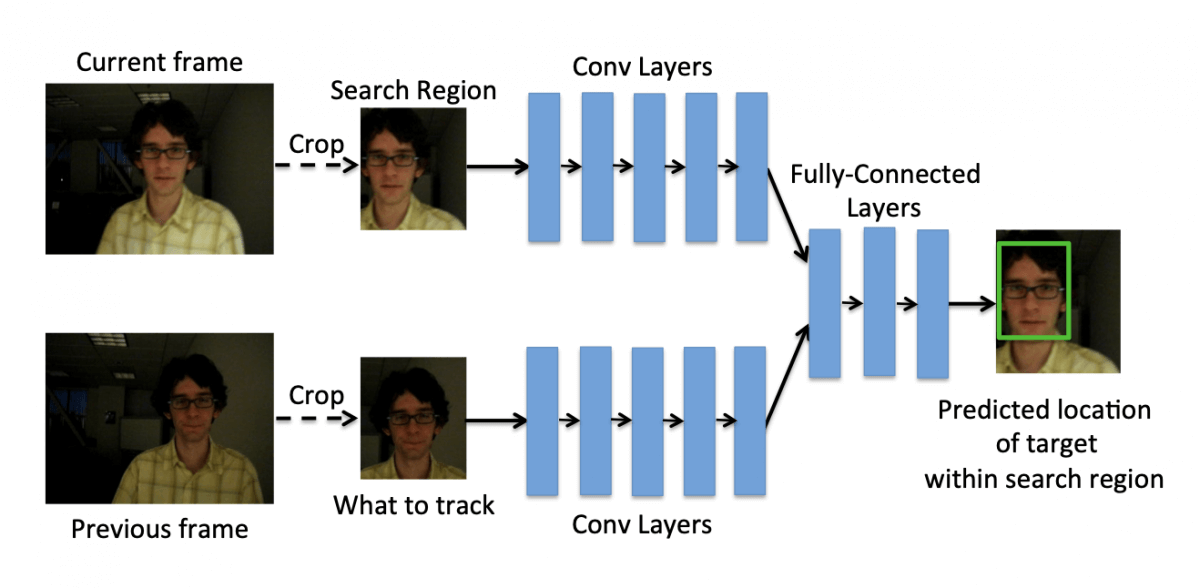
GOTURN (Generic Object Tracking Using Regression Networks) works by using two neural networks and specifying the region to search. It can work at over 100 FPS, which is amazing for the task of video tracking.
Multiple Object Tracking (MOT)
The last family of trackers is referred to as multiple object tracking. Here’s a look at MOT in practice:

Unlike the other family of trackers (VOT), MOT is more long-term.
We distinguish two variants:
- Detection-Based Tracking
- Detection-Free Tracking
Let’s consider Detection-Based Tracking. We have two tasks here:
- Object detection
- Object association
Object association means that we have to associate detections from time t to detections from time t+1. It relies heavily on the quality of the detector.
- A bad detector will render the tracker not functional.
- A good tracker should handle a few frames with no detections.

We can also distinguish between online and offline tracking. Online tracking means that we are on a live feed. Offline tracking is working on a full video, and we have future frames available.
For online tracking, we’re tracking the bounding boxes detected by the CNN. We can use:
- A CNN for the detection
- A Kalman Filter to predict the position at time t from the position at time t-1
- The Hungarian Algorithm for detection of frame association
The matching metric for the Hungarian algorithm can be IOU (Intersection Over Union) or deep convolutional features. Using deep convolutional features allows for re-identification after occlusion but slows down the tracker.
To find datasets for MOT tasks, check out motchallenge.net
Multi Object Tracking is adding possibilities to obstacle detection like Game Analysis or Behavioral Prediction.
For more on this, check out my article Computer Vision for Tracking !
I released an online course on Multi Object Tracking called LEARN OBSTACLE TRACKING — The Master Key to become a Self-Driving Car Professional .
It’s a course that doesn’t exist anywhere else, and where you’ll learn how to code this exact tracking system.
To summarize: The first family of video analysis systems is obstacle tracking.It includes optical flow estimation, visual object tracking, and multi-object tracking.
All these algorithms can be detection-free or detection-based and all include one idea: track an object in a video.
Next up, we’ll take a closer look at action classification.
2. Action Classification
Action classification is the second family of tasks involved in building computer vision-based surveillance systems. Once we know how many people we have in the store, and once we know what they’ve been doing, we must analyze their actions.
Action classification depends directly on object detection and tracking—this is because we first need to understand a given situation or scene. Once we have that understanding, we can classify the actions inside the bounding box.
First, we must choose the camera that sees them with the best angle. Some angles might be better than others. If we choose the correct camera every time—for example, the camera that shows a face—then we can be sure we have a workable image.
Actions can be really simple, like walking, running, clapping, or waving. They can also be more complex, like making a sandwich, which involves a series of multiple actions (cutting bred, washing tomatoes, etc).
Datasets
Labeling is much easier for classification than for tracking—we can simply assign a label to a set of images.
The KTH Actions Dataset is good for gathering videos and associated labels. The UCF Sport Actions is a dataset that’s sports-oriented, but it includes useful samples.
More recently, datasets like Hollywood2 for movies scenes, HMDB, or UCF 101 have been released.
Optical flow
Since optical flow is used to determine a vector between two frames. It can be used as an input for a classification neural network.
From the optical flow, we define actions and stack a neural network classifier.
Action Classification with Machine Learning (End-To-End)
The more recent and modern solution would be to use CNNs.
Action happens in a video, not an image. This means that we must send multiple frames to the CNN, which must then perform a classification task on what’s called a space-time volume.
With an image, it’s hard enough to do object detection or classification due to the image size, its rotation, etc. In a video, it’s even more difficult.
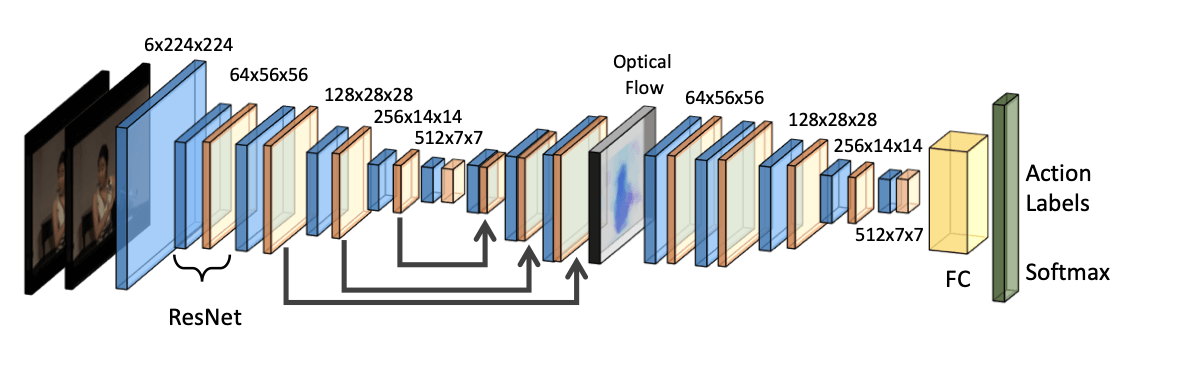
Here’s an example of a two-scale model working to classify actions from image streams.

These neural networks work on 2 inputs and output an action. The spatial stream is working on a single image ; it’s stacked with the temporal stream working on an input optical flow . A linear classifier is applied here.
There are a lot of action classification networks that already exist—it’s a hard problem to solve.
For a complete overview of action classification neural networks, I encourage you to read this blog post .
Pose Estimation
Finally, know that pose estimation is another deep learning technique used as a means for action classification.
The process of pose estimation includes:
- Detecting keypoints (similar to facial landmarks)
- Tracking these keypoints
- Classifying the keypoints's movement

Here is a complete overview of the algorithms.
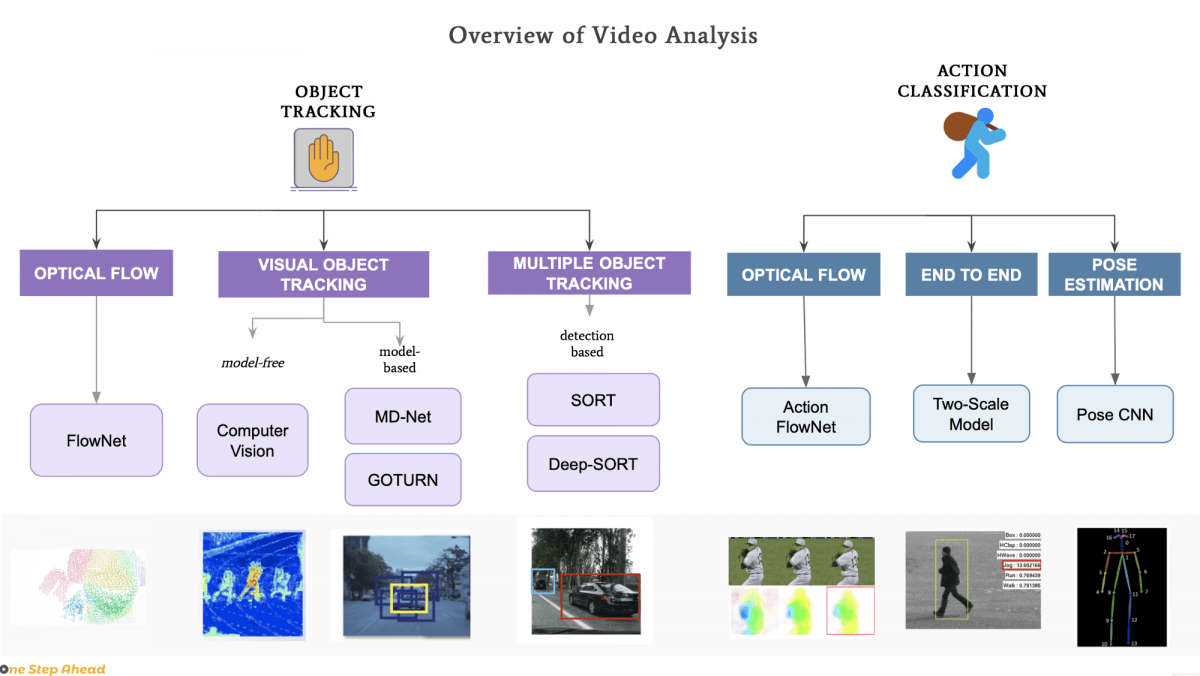
Video Analysis is the next step in Computer Vision. Our algorithms will now need to understand sequences of images, 6D inputs, and time related scenes.



{kind=link}