Introduction to Computer Vision for Self-Driving Cars
In this article, we're going to explore for the first time what is Computer Vision, and how it's implemented in Self-Driving Cars!
Self-Driving Cars will soon become an everyday thing, and we're only at the beginning. If we are to understand how to create these futuristic engines, we must understand the most relevant techniques that made it all possible: Computer Vision.Computer Vision is everywhere in self-driving cars, and especially in the perception of the environment.
How to perceive an environment with a camera? What is Computer Vision in Self-Driving Cars? The image below shows four main steps in the operation of an autonomous vehicle.
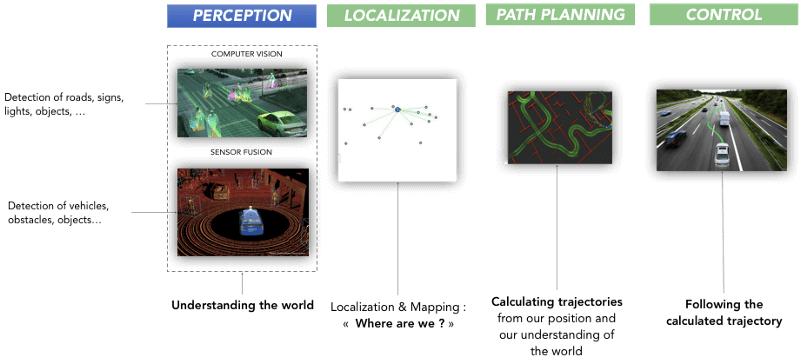
- Computer Vision and Sensor Fusion are called Perception.
It’s about understanding the environment. Computer Vision uses a camera. This allows to identify cars, pedestrians, roads, … Sensor Fusion uses and merges data from other sensors such as a Radar and a Lidar to complement those obtained by the camera.
This makes it possible to estimate the positions and speeds of the objects identified by the camera. - Localization is the step that can locate a car more precisely than a GPS would.
- Path Planning implements the brain of an autonomous vehicle.
A Path Planner uses the data from the first two steps to predict what vehicles, pedestrians, objects around them will do to generate trajectories from point A to point B. - Control uses controllers to actuate the vehicle.
As you can see, Computer Vision is the first and biggest priority we're going to learn. Other articles will then cover the other modules.
Computer Vision
Computer Vision is a discipline that allows a computer equipped with a camera to understand its environment.
Computer vision techniques are used in autonomous vehicles to detect pedestrians or other objects, but can also be used to diagnose cancers by looking for abnormalities in images .
They can go from the detection of lines and colors in a very classic way to artificial intelligence.
Computer vision started in the 50s, when transcribing the shapes of certain objects. The end of the century led us to the development of techniques such as Canny-edge detection which allows us to distinguish the evolution of the color in an image.

In 2001, the Viola-Jones algorithm demonstrated the ability of a computer to recognize a face.

In the following years Machine Learning became popular for object detection with the widespread use of Histogram of Oriented Gradients (HOG) and classifiers. The goal is to train a model to recognize the shapes of an object by recognizing its different orientations (gradients). The histograms of oriented gradients retain the shapes and directions of each pixel; then average over a wider area.
Deep Learning then became very popular for its performance, due to the arrival of powerful GPUs (Graphical Processor Units allowing parallel operations, not one after another) and the accumulation of data. Before GPUs, Deep Learning algorithms did not work on our machines.
Computer vision can be done by three approaches:
- Without artificial intelligence , by analyzing shapes and colors
- In Machine Learning, learning from features
- In Deep Learning, learning alone.
Machine Learning
Machine Learning is a discipline used in Computer Vision to learn how to identify shapes.
There are two types of learning:
- Supervised learning allows us to create rules automatically from a learning database.
We distinguish : - Classification : Predict whether a data belongs to one class or another. (example: dog or cat).
- Regression : Predict one data based on another. (example: The price of a house from its size or zip code)
- Unsupervised learning means that similar data are automatically grouped together.
There are four steps in the process of supervised learning for car detection.
- The first one is the creation of a database of images of cars and road. Supervised learning involves indicating which image corresponds to a car and which image represents the background. This is called labeling.
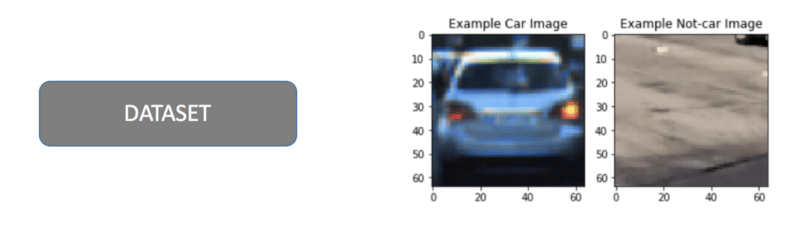
2. To see which features belong to a car, we try our image with different color spaces. We get the form using HOG features. The image is transformed into feature vectors.

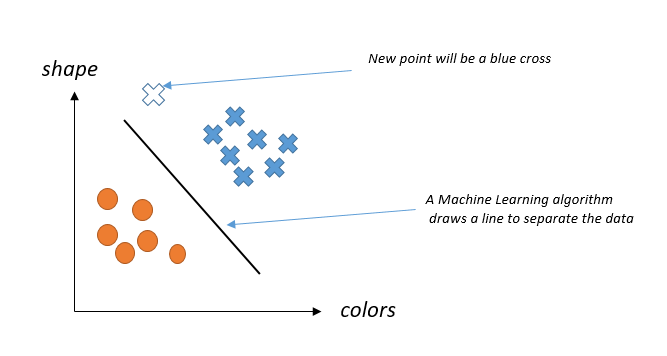
3. These vectors are concatenated and used as a training base. In the graph below, the shapes and colors are indicated on the vertical and horizontal axes.
Our classes are our blue points (car) and oranges one (non car). We must also choose a classifier.A machine learning algorithm is meant to draw a line separating two classes according to features. The new points (white cross) are then predicted according to their positions relative to the line. The more training data we have , the more accurate the prediction will be.
4. The last step is prediction. It implements an algorithm that goes through the image and converts it into a vector with the same features used for training. Each part of the image is analyzed and passed to the classifier who draws bounding boxes around the cars.

Machine Learning’s algorithms allow to choose which features are used for training.These algorithms are today used more in data manipulation than in image recognition because of the arrival of Deep Learning and neural networks. Moreover, the detection is slow and generates a lot of false positives. To eliminate them, we need a lot of background images (roads, streets, …).
Neural Networks
Neural networks use a Machine Learning algorithm to take input images and return the number of cars and their position. The algorithm simulates the functioning of the human brain by interconnecting artificial neurons.
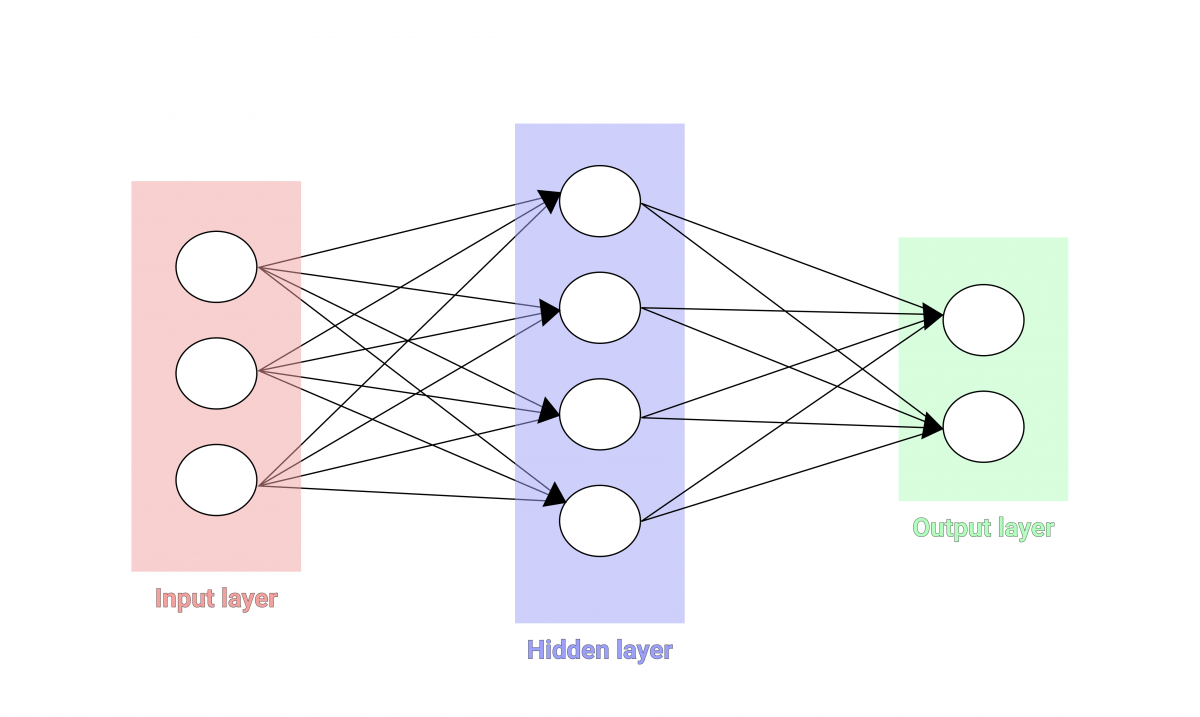
In the diagram above, each circle is the representation of a neuron, called Perceptron. The entries on the left are sent to a layer of neurons in the center. Eachconnection between the neurons has a weight W(the importance given to a parameter). The goal of an algorithm is to optimize these weights. Operations take place in each neuron in the central layer to predict a class. Each class is represented by an output neuron.
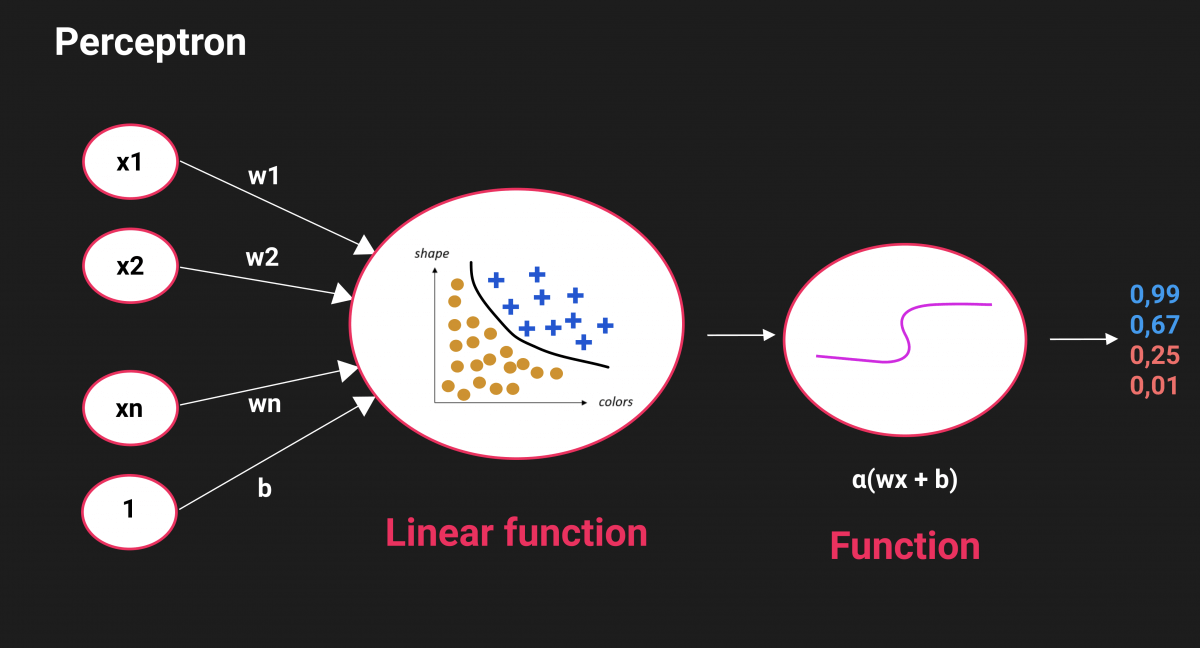
In each neuron, there is an algorithm that classifies data according to features. When training a model with a lot of data, the network learns which weight has been more important than another. The goal is to achieve a perfect separation of classes.
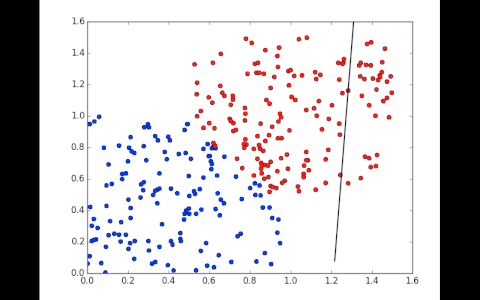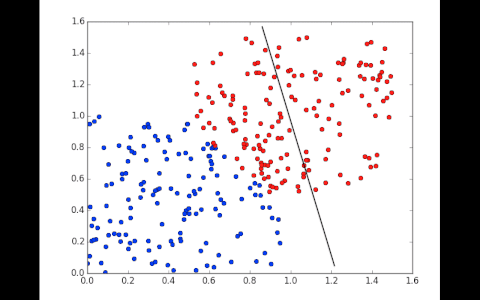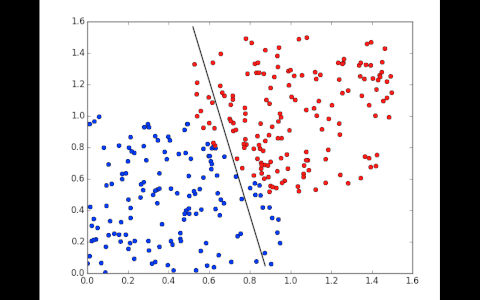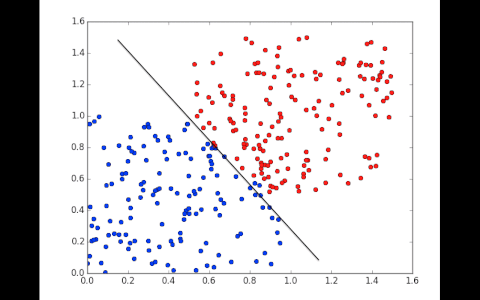
To train, the network will first set weights randomly and see if the points are classified correctly. Part of the points won’t be, it then adjusts the weights very slightly in one direction and looks if the error, calculated by a function, decreases. It repeats the operation hundreds of times until it has a line that correctly classifies the training data.
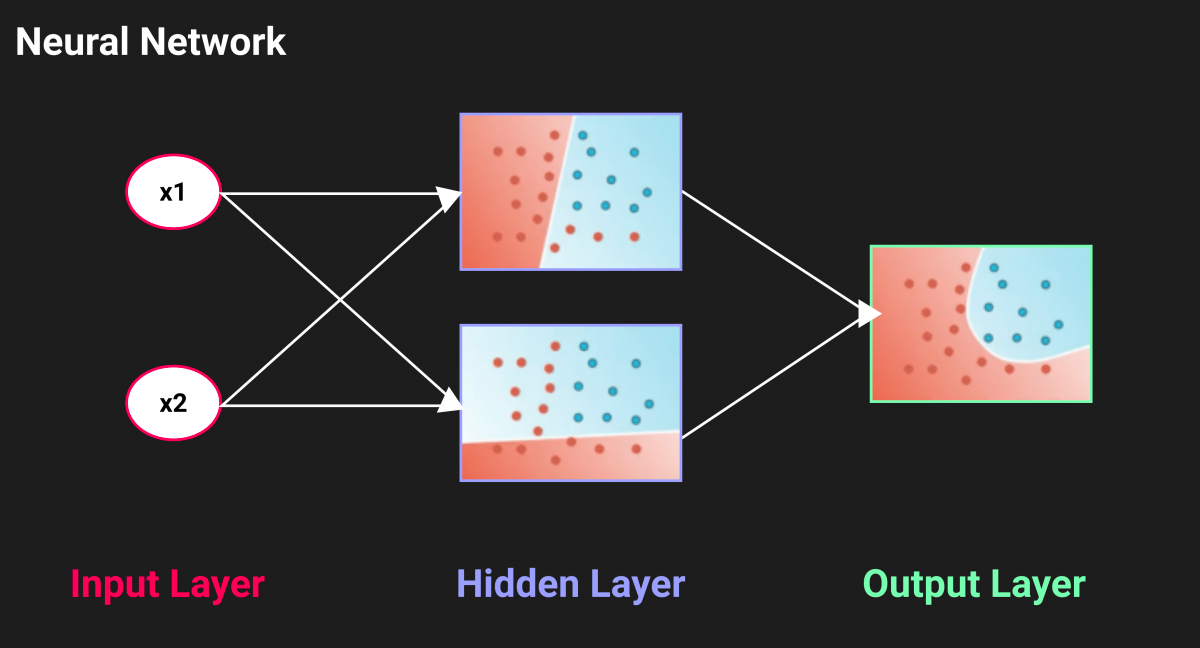
To process nonlinear data, a neural network computes a sum of two linear models and combines them. This is because the classifier used is different from the classical machine learning classifiers, it uses a process called gradient descent .
If neural networks are outperforming conventional algorithms, they have the disadvantage of being a black box because we do not choose characteristics or weights.The algorithm guesses them alone according to our data and our labeling.
What is Deep Learning ?
Neural Networks outperform other Machine Learning algorithms.What is Deep Learning and why is it so popular ?
Deep Learning is the implementation of the Machine Learning “Neural Networks” with more than one layer in the middle.
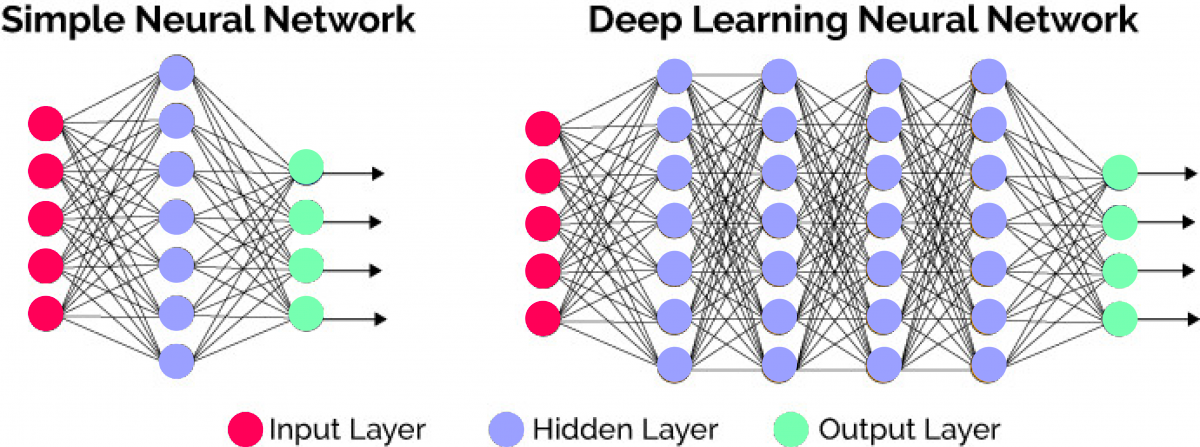
Multiple layers in a neural network give better results on more complex operations than a single layer. With more models taken into account, there are fewer badly classified points because of less linearity.
The more parameters and difficult data, the more useful and effective a deep neural network will be.
Above all, there is the advantage of being multi-layered: the output of a neuron (probability of being a class) is used at the input of the next neuron : This is called feed-forward.
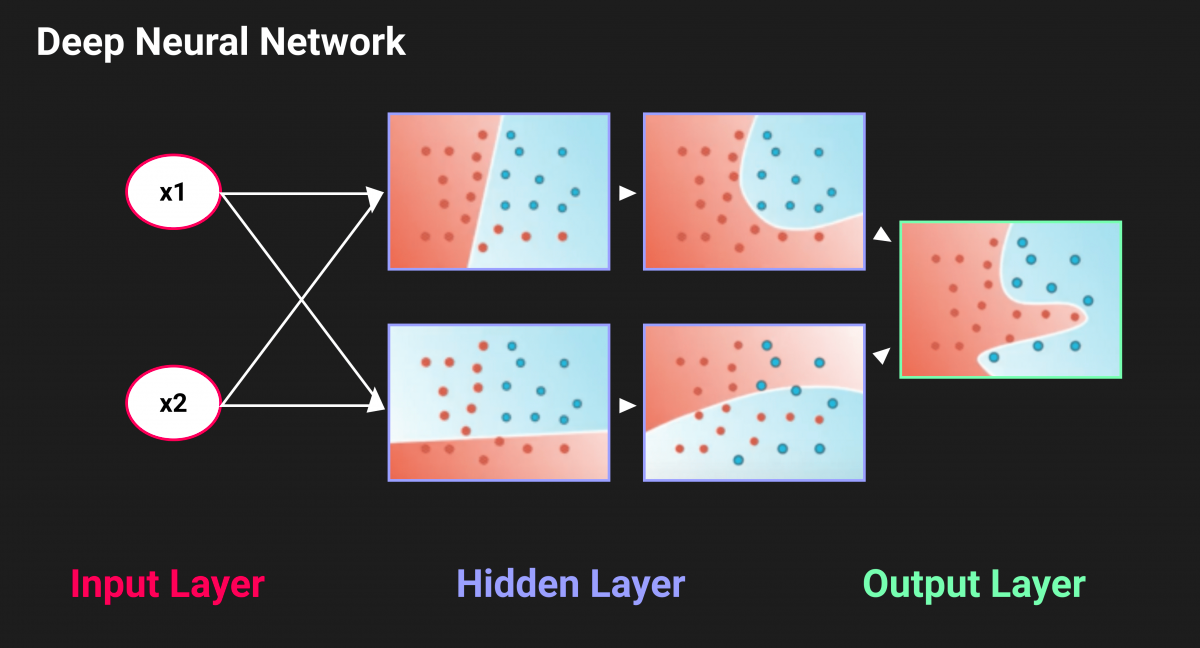
Deep Neural Networks (DNNs) are very effective and are used today for most complex problems such as voice assist, image analysis, … This sub-part of Machine Learning performs better than any other algorithm on a very wide range of domains.
Deep Learning and Image recognition : CNNs
Deep Learning makes it possible to perform better than many Machine Learning algorithms. Beyond simple linear operations, it can be adapted to particular problems, such as image analysis.
In image analysis, we generally speak of Deep Learning under the term CNN : Convolutional Neural Networks or ConvNets. CNNs are neural networks that share their weight in the network .
This is handled by operations called convolutions. These operations pass a small part of the image through a neural network, and then browse the entire image by retaining only the shapes of the object we want to learn . We extract the characteristics of the object at each operation. The weight of this object is then shared throughout the network and is optimized for each new image.In several images, we recognize the forms of our object that are recurrent and we train our network on these forms.
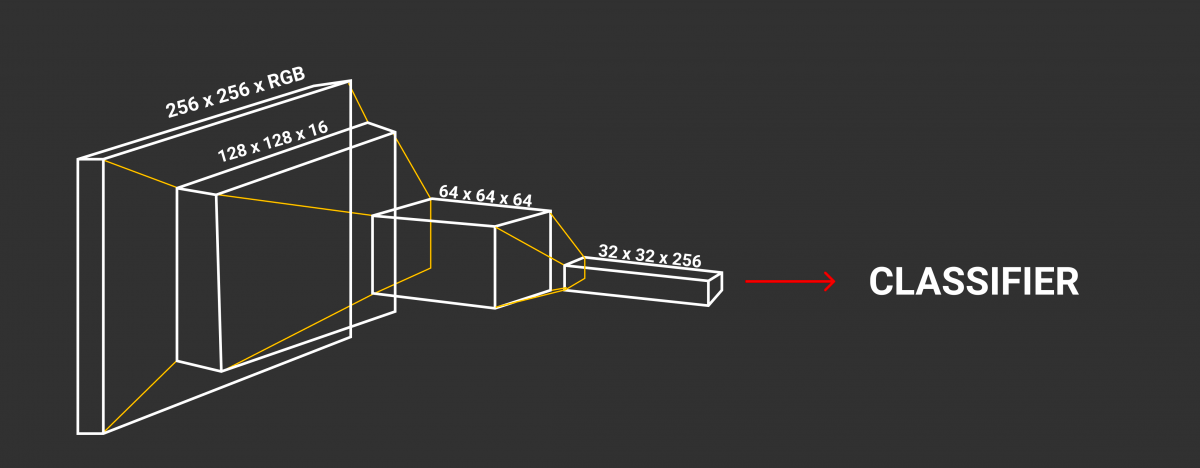
To recognize an object, CNNs make different layers learn according to levels of complexity.
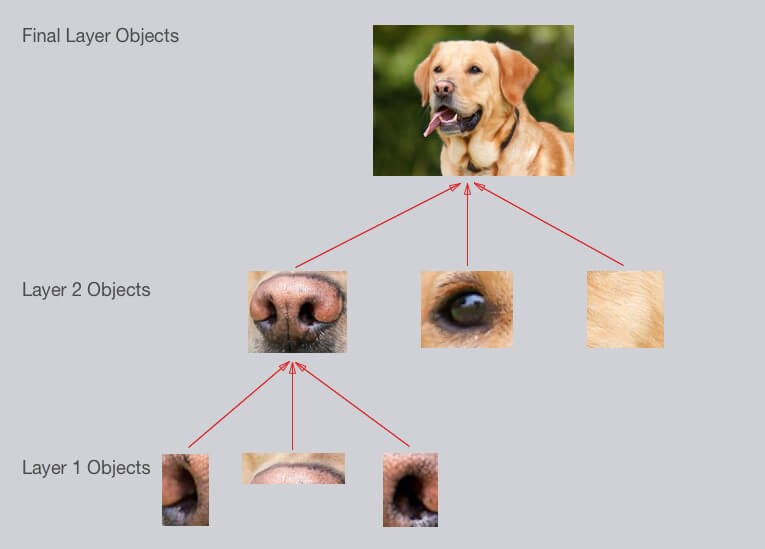
In our example, the first layer will learn simple shapes like circles and lines while the next one will learn slightly more complex shapes, until we learn what our object looks like in its totality.Unlike Machine Learning, where we choose features manually, a CNN learns only which features to choose here, and which shapes to retain. Unlike a simple neural network, we can handle complex operations such as image analysis. Training is much longer than Machine Learning, it can take up to several days. The detection is on the other hand very fast and much more reliable.
Results
My projects with Udacity made me test computer vision with three approaches: the first is set to identify lines on a road, the second is to detect vehicles. The last project uses Deep Learning to predict which angle to adopt depending on the situation.



Conclusion
Deep Learning is a part of Machine Learning, since it is the implementation of one of its algorithms with several layers instead of one. This algorithm called Neural Networks is quite different from the others because it guesses the relevant features while the other algorithms of Machine Learning are nourished by features that we give to it.
📩 If you'd like to go further in Computer Vision and Self-Driving Cars; I invite you to receive my daily emails that will teach you how to become a self-driving car engineer! With that, you'll receive the Self-Driving Car Engineer MindMap! It's all here!