Image Segmentation: Use Cases for 2D and 3D Computer Vision
If you're a Computer Vision Engineer, you probably know by know that the process of image segmentation is to assign a class to every pixel of an image. When I first learned it, I learned that it was the most granular level:
"First, there is image classification; it's when you classify an entire image. Then, there is object detection; it's when you localize and classify parts of an image with bounding boxes. And finally, there is semantic segmentation; it's when you assign each single pixel of an image to a target class."
Later in my career, I started to need to use image segmentation, for use cases such as lane line detection in autonomous shuttles. We needed image segmentation, but we didn't really need the segmentation maps that were pitched to be a bit earlier.
For example, when you're finding lane lines using image segmentation, you don't want an image with lane lines drawn on it, you want lane line equations!

And this is when I started to wonder:
"How do we use image segmentation?"
In some industries, such as healthcare, it's crystal clear: the segmentation algorithm does what the radiologist or doctor should do. But in other industries, such as robotics, the exact "how to" these algorithms are used is more obscure.
In this article, I'd like to share with you some ways to make use of image segmentation in Computer Vision — and we'll explore 2D and 3D techniques, some of them used in autonomous driving".
So let's get started:
What is image segmentation? A short introduction
The problem with object detection is that, in some cases, it makes zero sense to use it. For example, if you want to see buildings, or the sky, or the road; you don't want bounding boxes for that. Instead, you want a segmentation map.

So we know we want to produce segmentation maps, and in fact, I often recommend every Computer Vision Engineer to learn how to build these kinds of maps in my daily emails.
But there isn't just one type of segmentation map, you probably heard of instance, semantic, and panoptic segmentation.
Let's see them:
Semantic vs Instance vs Panoptic Segmentation
When looking at the following image, you can clearly see all 3 types of image segmentation algorithms.
- Semantic Segmentation involves labeling each pixel in an image with a class label, such as "person," "car," or "road."
- Instance segmentation is similar to semantic segmentation, but it also distinguishes between different instances of the same object class (one color per object)
- Panoptic segmentation is combining instance and semantic segmentation, so that every pixel in an image is assigned a class label and an instance ID.
If we just pause here, you'll notice that each of these can have a specific set of use cases. Just like it's not always image segmentation over object detection, it's not always panoptic segmentation over semantic segmentation either.
If we're just concerned about finding lane lines, we might go with semantic segmentation, but if we're looking for a complex scene understanding with objects, we'll explore instance and panoptic ideas.
From there, we understand that based on the level of granularity, we'll have a different way to pick a segmentation algorithm.
Another way to understand the different use cases is through the industry applications.
Real-World Use Cases of Image Segmentation
Every day, hundreds of industries use image segmentation. From background removal, to the movie industry, to autonomous robots, to healthcare. You can pretty much consider that if there is a scene to analyze and understand, there will be a segmentation algorithm.
Let me show you a few ways to do this:
Aerial Segmentation & Satellite Imaging
First, if we mount a camera on a drone, satellite, or plane, we could then analyze the buildings, lands, streets, etc... This has various use cases, from agriculture (where we study what to water and what to let dry), to the army, to flood monitoring.
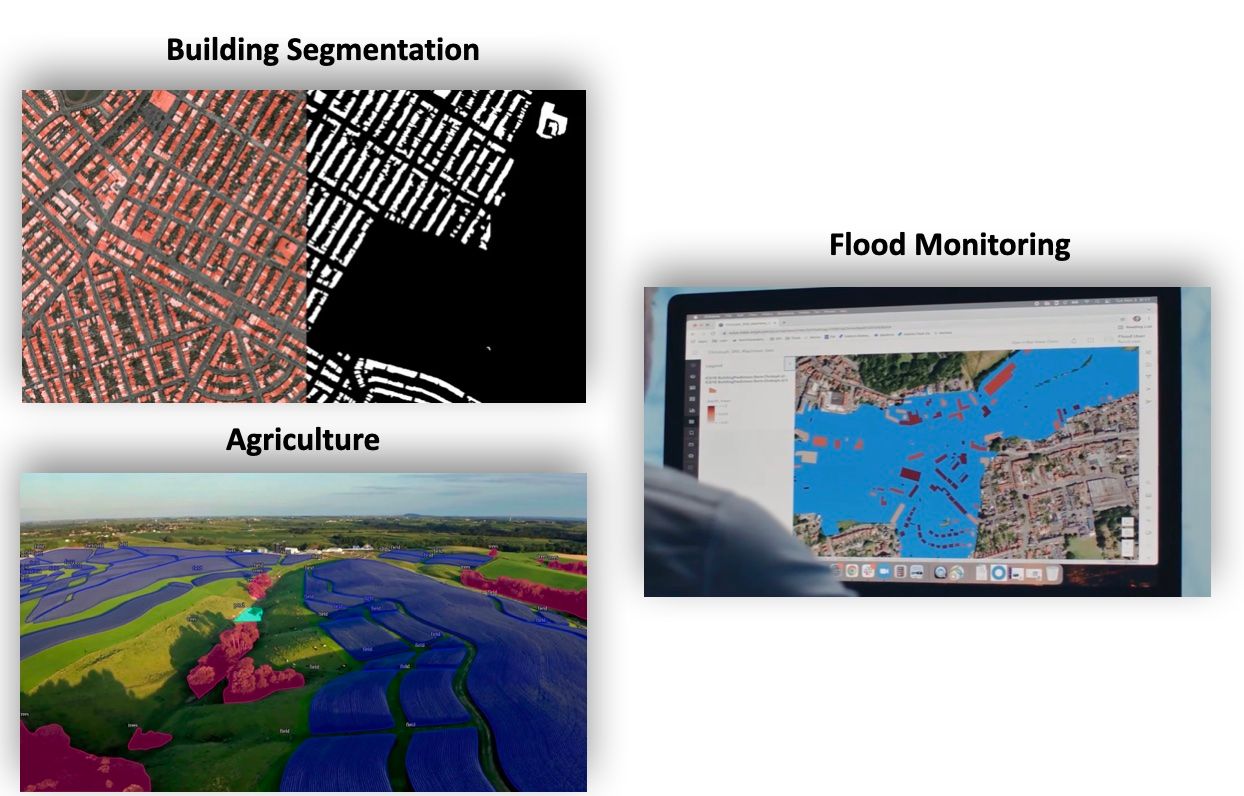
These images have been taken from startups Deepsense.ai (building), Iceye (flood monitoring), and the channel Keymakr (agriculture).
So now let's imagine we're not in the air, but driving a robot.
Robot Image Segmentation
If we're inside a robot, the situation is now different: we must detect drivable surfaces, lane lines, objects, and so many other things. We also have the dimensionality: 2D vs 3D image segmentation, Cartesian vs Bird-Eye View, and we even have "camera" vs "point cloud" image segmentation, depending on where the data is from.
So let's see these applications:
- All the different applications in an image
- Cartesian vs Bird Eye View
- 2D vs 3D Image Segmentation
- Camera vs Point Clouds
Applications in an image

But we're really just scratching the surface here, because if we're zooming on the "drivable area" use case, we then have things such as freespace vs road curves:

But then a question gets asked: How do you make use of the segmentation mask? After all, the information that pixel (100, 100) on camera 2 is a road isn't directly helping, we must convert that to 3D or something similar.
One very effective way is through the Bird Eye View conversion.
Bird Eye View
Bird Eye View is about converting the output to a 2D Bird Eye View, but the difference is you can actually use this result. Freespace for freespace isn't useful, but BEV Freespace leads to the Smart Summon feature from Tesla; because you can combine the 2D Bird Eye View with a 2D Map.
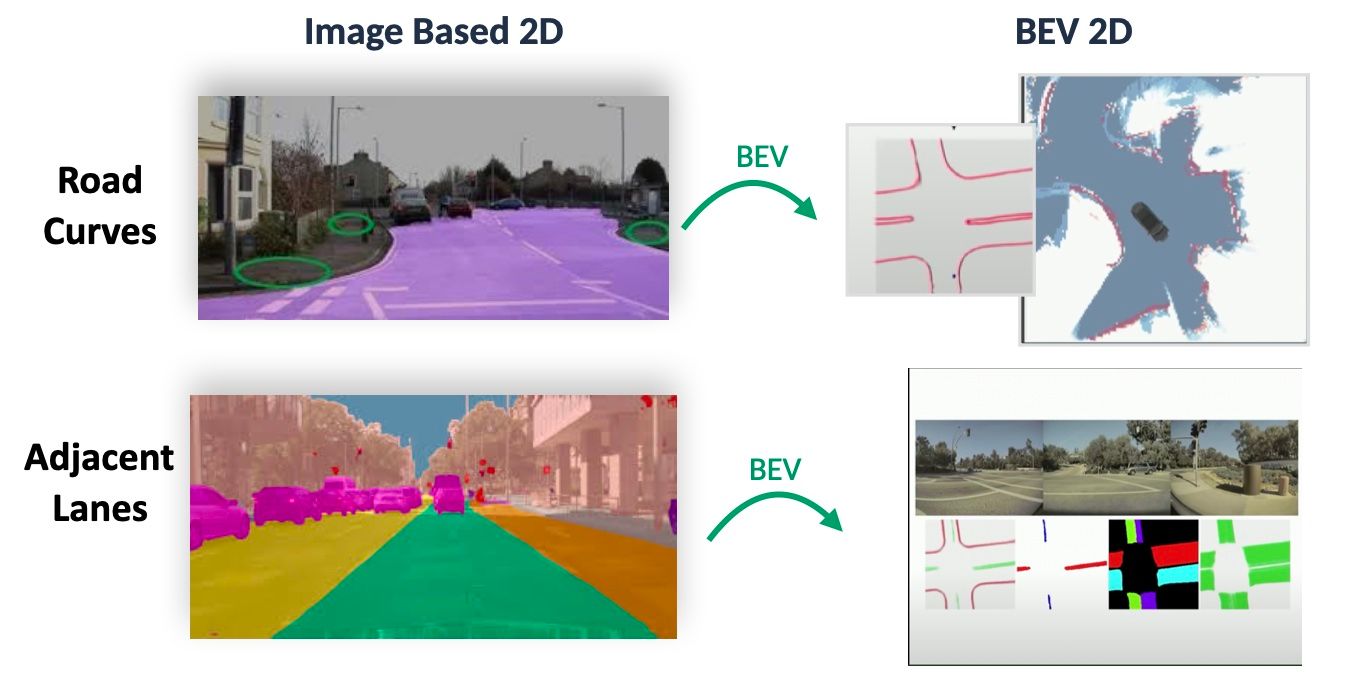
The use of Bird-Eye View can be better understood in the video below, where we fuse Panoptic Segmentation with Bird-Eye-View Networks, in a CVPR 2022 Algorithm called Panoptic BEV:

Lastly (but not final), robots also use segmentation on Point Clouds rather than images. Instead of working on cameras, we work with LiDARs.
Point Clouds & 3D Segmentation
The concept of "image segmentation" means we process images. But what if we weren't? In Robotics, LiDAR Sensors are extensively used to generate a point cloud of the environment, that gives us the distance of any object at centimeter level accuracy.
Algorithms such as RANSAC (Random Sample Consensus) or PointNet++ are the pillars in this category.

If we go just a tiny bit further, it means we can also convert images to 3D, using 3D Computer Vision principles, and fuse that with image segmentation maps. We would therefore have a 3D Segmentation output:
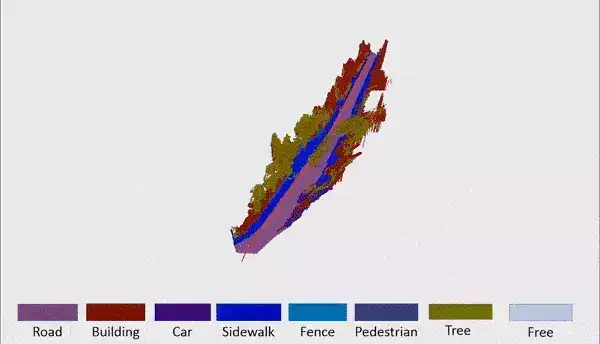
In Robotics, 3D Computer Vision has much more use than 2D Computer Vision; and it's natural that we combine segmentation maps with 3D structures to augment them.
Next:
Healthcare
Ever heard to the Chest-X-Ray dataset? It's a very popular dataset for image segmentation to identify chest problems. And in fact, image segmentation is probably one of the most used algorithm in AI for healthcare today. Again, it's not "just" semantic segmentation.
But let me show you a cool picture of Dental X-Ray Imaging:
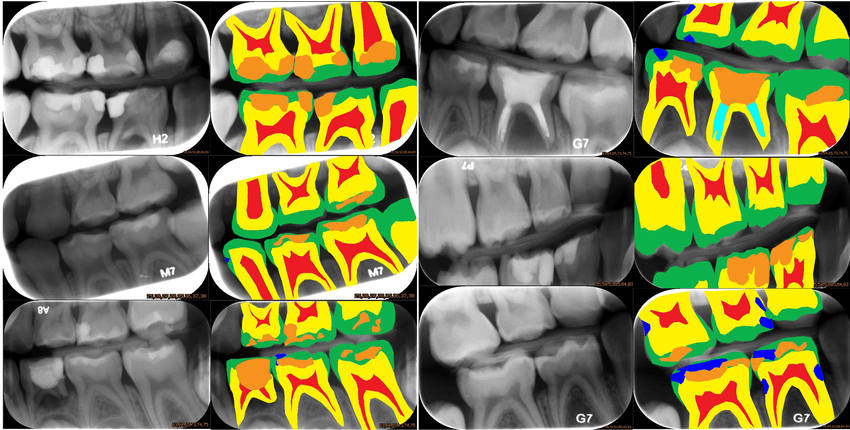
Yes, dentists can also use image segmentation. Just like oncologists (the people who find cancers) and radiologists. In healthcare, image segmentation has known a revolution in the past few years, and I've personally noticed the explosion of AI radiology startups in Paris.
It really doesn't stop here, image segmentation is what Google, Apple, and many imaging software use to remove the background of a picture. It's what's used in augmented and virtual reality
Augmented & Virtual Reality
One way image segmentation can be used in AR and VR is to segment the real world into different regions, and then overlay virtual objects onto the real world. This is what Snapchat has used a lot in the past to add virtual objects to your living room.

Image segmentation can also be used in Virtual Reality to create more immersive and interactive experiences. For example, image segmentation can be used to identify different objects in a virtual environment and allow users to interact with them in a natural and intuitive way. This could involve using image segmentation to identify and track the movements of a user's hands, and using this information to control the virtual environment or objects within it.
Summary
Other than this, image segmentation can be used in many industries, such as factories (for inspections), geology, fashion, marketing, traffic monitoring, and more.
So this calls for a brief summary:
- Image Segmentation is the most "granular" use of Computer Vision, because it operates at the pixel level.
- We have 3 types of image segmentation algorithms: semantic segmentation (1 class = 1 color), instance segmentation (1 object = 1 color), and panoptic segmentation (both)
- A single segmentation map isn't necessarily useful in robotics, but we can extend it to 3D, or convert it to a Bird-Eye View. What's important to understand is that sometimes, finding the segmentation map is just the first step of a long suite of algorithms.
- Image Segmentation is massively used in robotics, healthcare, and phones; and it also has applications in lots of other industries.
Finally, and most important point:
- I am teaching a course on Modern Image Segmentation — and it teaches you how to build Deep Learning Architectures for image segmentation, such as UNet, DeepLab, or even SegFormers (image segmentation algorithms based on Transformer Networks). It's advanced, but also has some refreshers for beginners.
You should check it out: https://courses.thinkautonomous.ai/image-segmentation