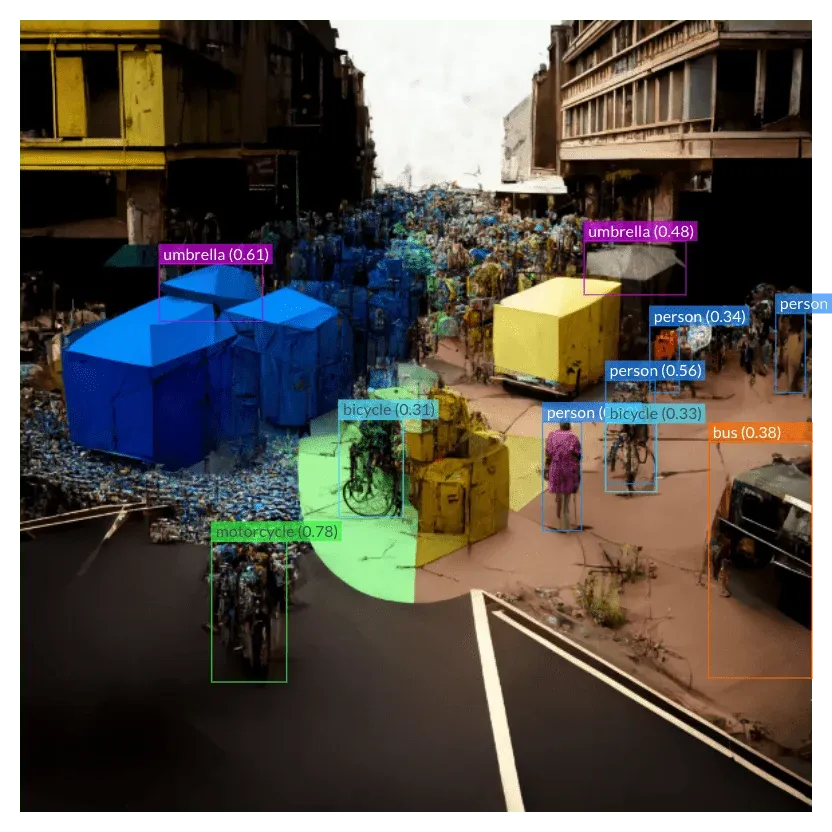
Instance Segmentation: How adding Masks improves Object Detection
It was late, and I was going back from the office to get home to my newborn baby, when I saw a post on my LinkedIn feed: "YOLOv7 Instance segmentation & Pose Estimation running at 30 FPS!".
"What is this guy talking about?" I thought. "YOLO" isn't a segmentation algorithm! And it's even less a pose estimation algorithm! What is he talking about!"
I couldn't help but open the video, to see how much this post was wrong, but then I saw it: The Instance Segmentation model made from YOLO!
When I looked at the output, I noticed something: Not only was the algorithm predicting the objects and the segmentation masks, but it also assigned a specific color for each of the individual objects.
I was amazed. Because at this moment, I realized that with an object detector like YOLO, we could do multiple tasks. And we again entered a new era!
The Era of Multi-Task Learning everywhere!
In this post, I want to explore the different ways to do instance segmentation. I want to us to understand better the main idea behind it, but also the "how" it's done. We'll see the real-world applications, and how it's in reality, just a strong multi-task learning algorithm.
What is instance segmentation, and why is it needed?
A few years ago, if you need to run 2 tasks such as object detection and image segmentation in parallel, you needed 2 models. With two models, came two different training pipelines, two loss functions to deal with, two datasets to label, and of course, twice the computing power needed.
But then came Instance Segmentation, which is the fusion of semantic segmentation and object detection, and was doable with just one model!
Rather than building one network for each task, you have a network that builds both — or as I often call these types of networks, you have a Hydranet!
So here is my network at first:
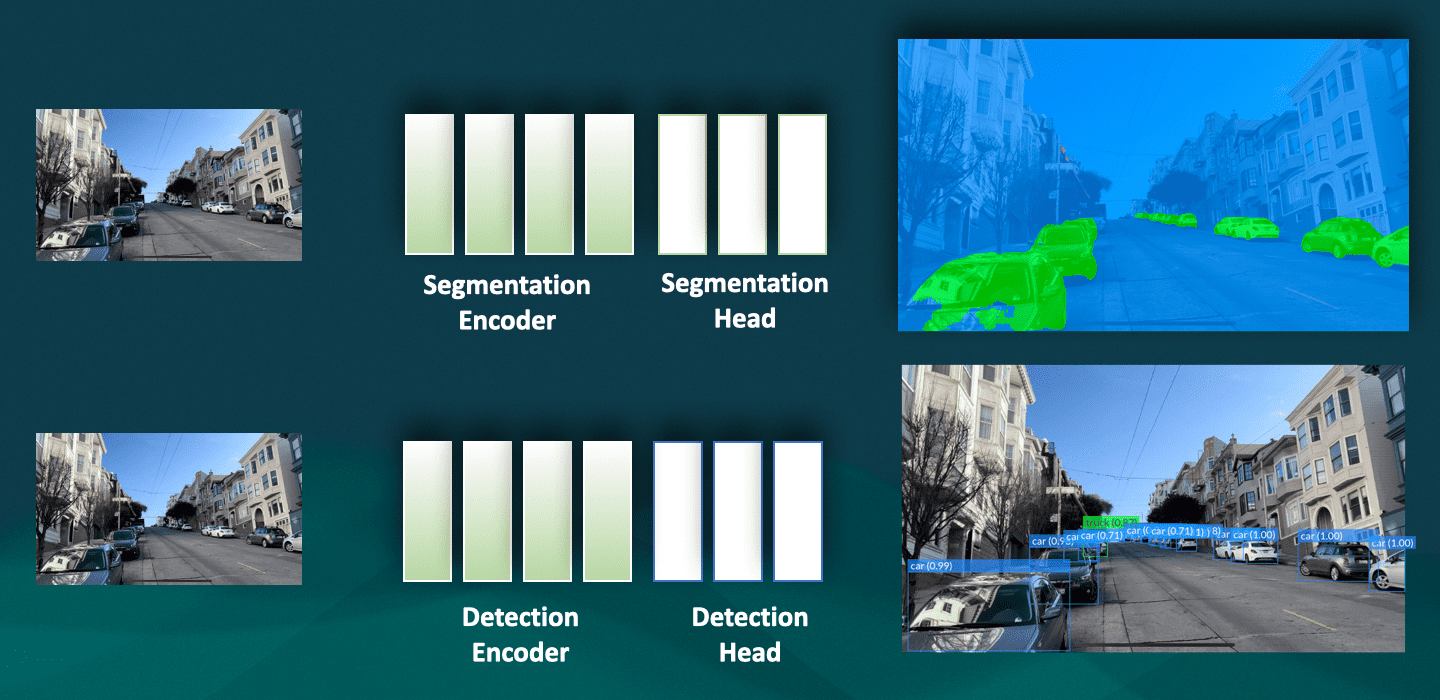
But we don't need to have two networks. This is the main idea behind multi-task learning, and I have an entire course about it; because encoders are essentially the same and have the same purposes (to learn features), we can use the same encoder, and then add heads to the network.
Like this:
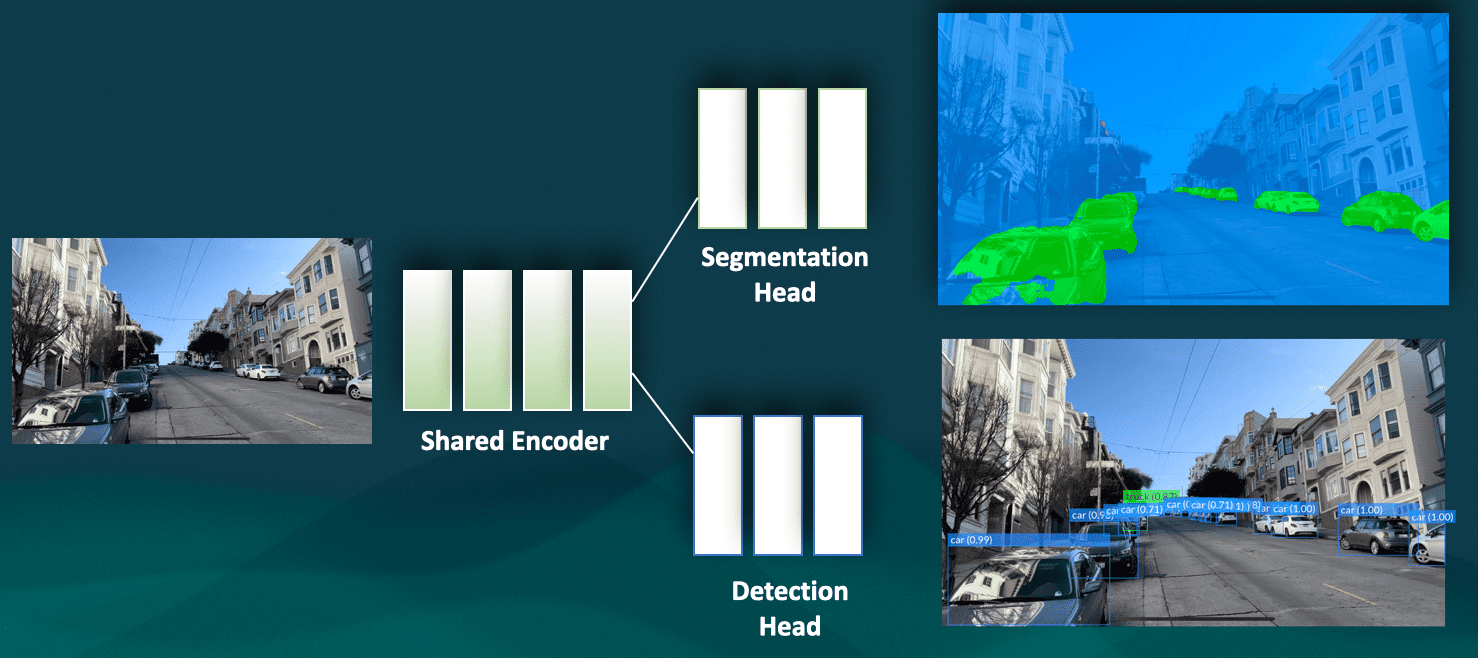
Instance Segmentation is doing exactly this. Rather than doing simple image segmentation or object detection, it's about doing both tasks at once.
This type of application is needed everywhere where both semantic segmentation and object detection are needed, for example in scene understanding for robotics or autonomous driving.
So let's get to the 1,000,000 $ question:
How does instance segmentation work?
How to turn an object detection algorithm like YOLO into an instance segmentation model? Is this a process where we fuse two neural networks? Do we really just "add a segmentation head" and that's it? What does it mean for training? Is there one loss? Two losses?
If we are to understand how to add a segmentation head to an algorithm like Faster-RCNN, we must first understand how these models work.
Take an object detector like Faster-RCNN (2015), the general architecture looks like this:
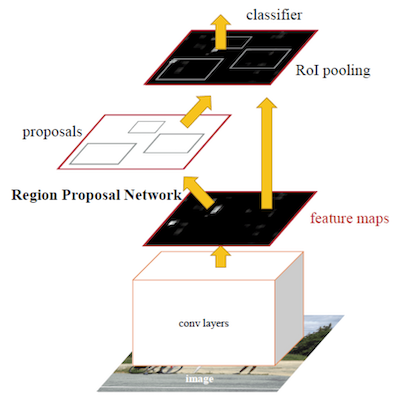
The way I explain it in my MASTER OBSTACLE TRACKING course is through this image:
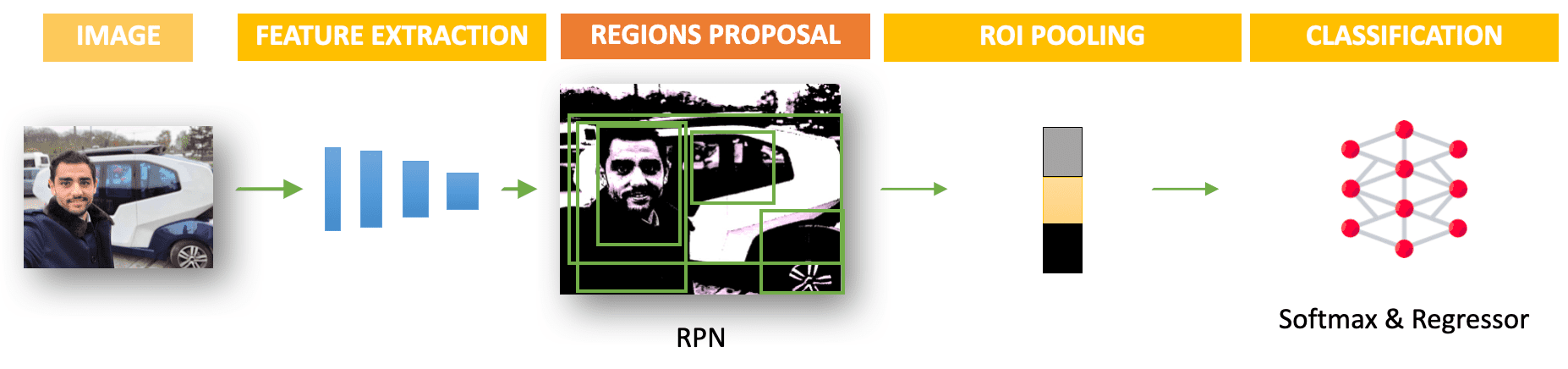
In short, we have two-stages:
- Bounding Box Proposal: A stage made of the Encoder or Feature Extraction, the RPN (Region Proposal Network), that proposes Bounding Boxes, and the ROI Pooling that extracts a fixed-length feature vector from the proposed regions.
- Box Classification: For each proposed box, we have extracted a vector — and we now classify this vector using some fully-connected layers. This is done for every box and the classification allows to predict between multiple categories.
On the other hand, we also have One-Stage Networks, like YOLO or SSD. This time, the architecture is one stage, we directly learn the features, regress bounding boxes, and classify them:
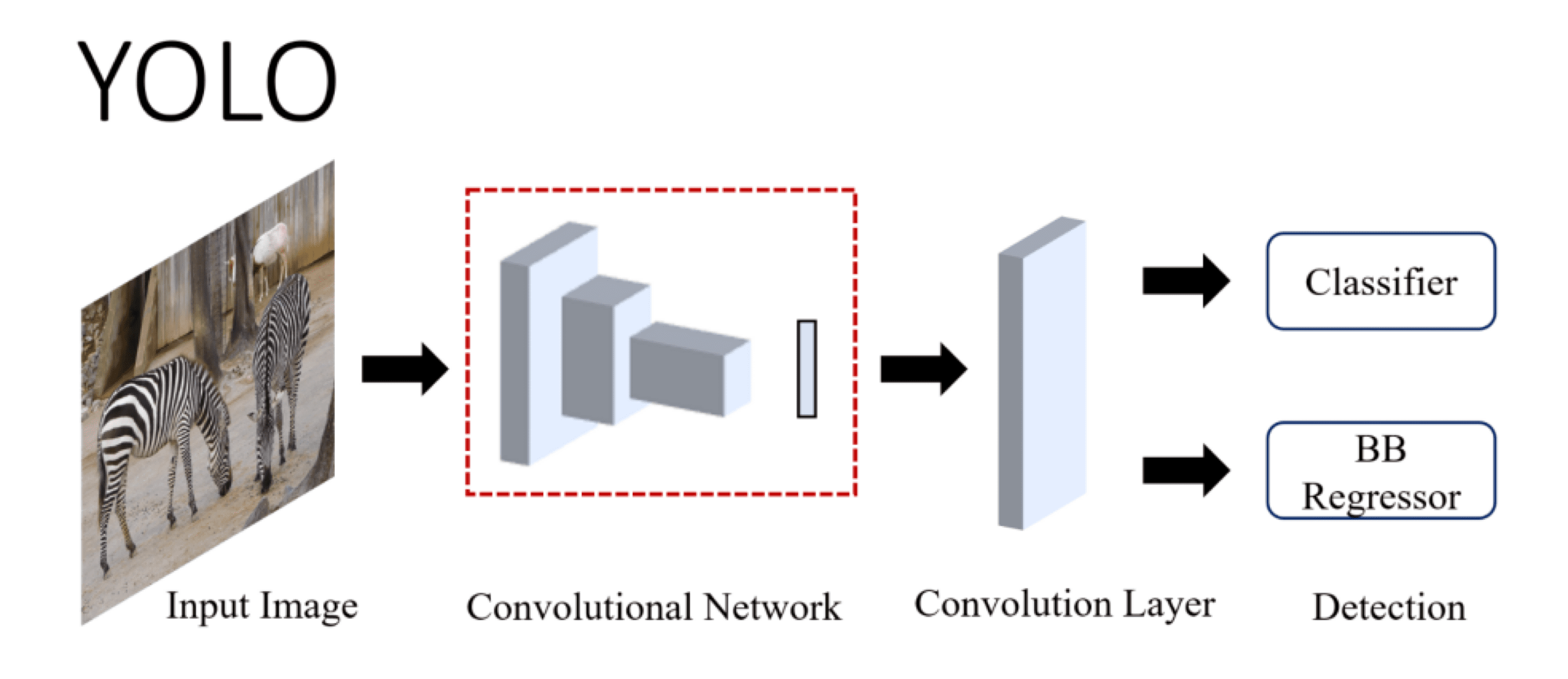
Whether it's Faster-RCNN or YOLO, the way to turn an object detector into an instance segmentation model is to add a mask prediction branch to the network. By the way, I invite you to read this article that explains the details of YOLOv4.
How to turn Faster-RCNN into Mask-RCNN?
Here is my simplification of the Mask-RCNN architecture that has been created to perform instance segmentation from Faster-RCNN:
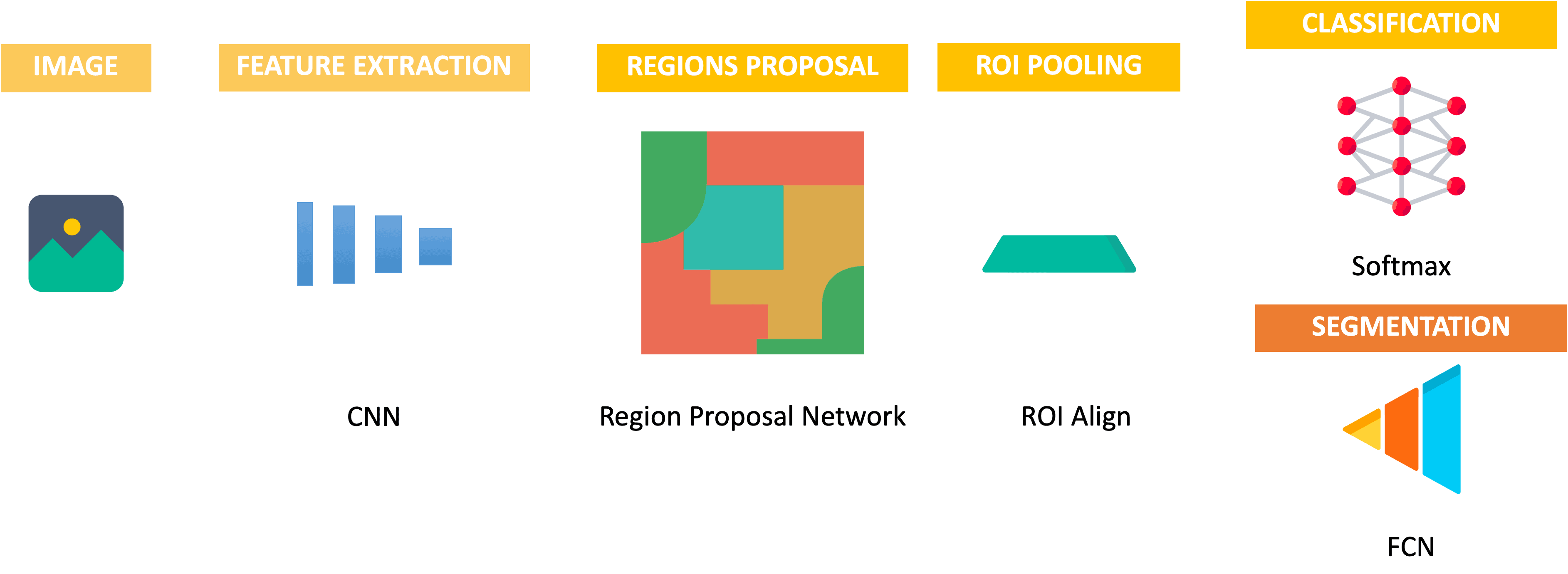
Once the boxes are "proposed", we can simply add a branch that will perform segmentation in parallel to the classification branch.
How? The output of the image segmentation branch is a set of binary masks, one for each object instance in the image.

How do we get these masks? The same way we do in any image segmentation task: we upsample the features learned for each ROI (proposed bounding box), and then build a decoder that classifies each pixel. For example, the Mask-RCNN model uses an FCN (Fully Convolutional Networks) — that is basically the first Deep Learning architecture for image segmentation.
YOLOv7 Mask and YOLOv7 Pose: How to turn YOLO into (almost) anything?
Why do I mention " YOLOv7"? Simply because this version from 2022 is the first to make multi-task directly possible. Mask-RCNN has for long been the go-to technique for instance segmentation. With YOLO, the architecture was different and harder to work on.
But in 2017, YOLOv7 shipped with new models heads, allowing for keypoints detection (pose estimation), instance segmentation, and object detection.
Semantic Segmentation Head
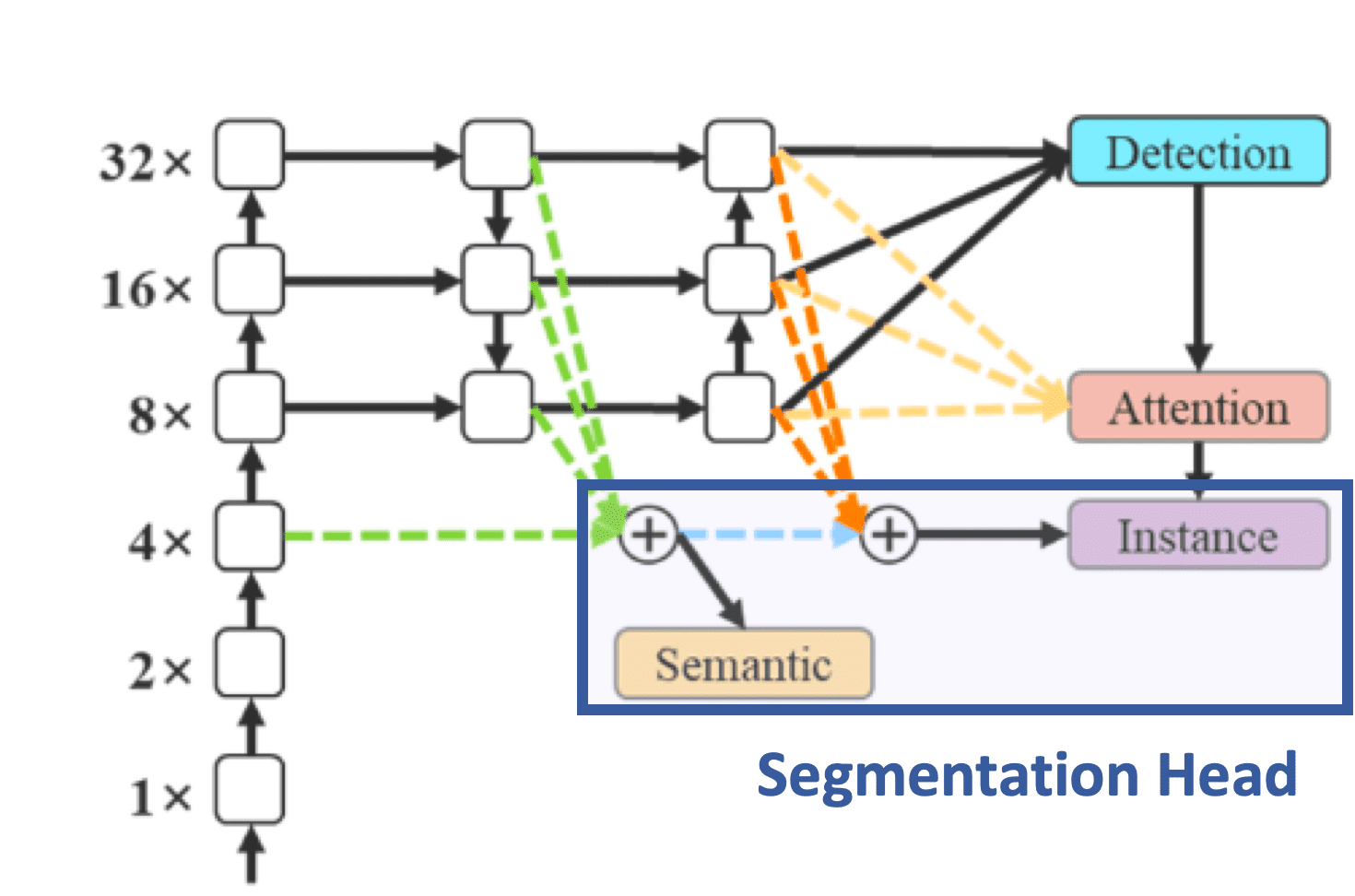
The way it works for semantic segmentation is by integrating a segmentation paper called BlendMask. BlendMask is a state-of-the-art instance segmentation algorithm that uses a multi-level feature fusion module to generate high-quality instance segmentation masks. What happens is YOLO is fine-tuned on the MS COCO instance segmentation dataset and trained for 30 epochs.
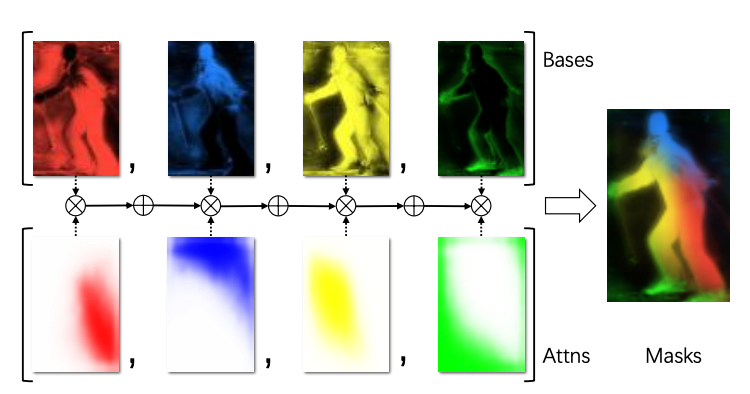
Blending
FYI, "blending" is the idea of fusing predicted bases from FPN (row 1) with attention masks (row 2):
Pose Estimation Head
Similarly, a model like YOLOv7 uses the YOLO-Pose algorithm that enhances YOLO by adding a keypoint detection output to each scale along the detections.
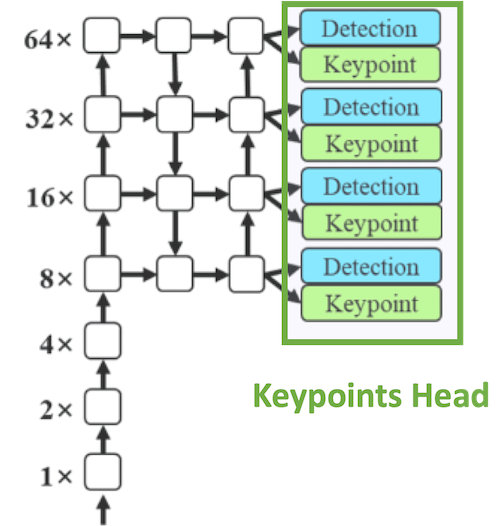
Notice how in both cases, the architecture is similar to a feature pyramid network, where we run predictions at different scales.
Which approach works better? Results show YOLOv7 is one of the state-of-the-art papers in instance segmentation, but to be fair, Mask-RCNN has been released in 2018, which is 4 years before YOLOv7.
Training, and all the mess that comes with it
One of the biggest problem in multi-task learning is training. Let's say you're training a model to classify whether a person is a man or a woman, and at the same time, you want to predict the age of that person.
The simplest implementation would take a classification loss such as Binary-Cross Entropy, but the regression model can use the L2 Loss, or L1 Loss. These outputs would not be at the same scale at all, and tasks like regression would be alone influencing the network's weights.
Doing segmentation and detection in the same network brings similar problem. Many papers address the issue, often by applying an alpha coefficient to each loss. In my course on HydraNets, I discuss such issues and several techniques to solve them.
Examples of Instance Segmentation algorithms
Since we're talking about YOLO, MASK-RCNN and BlendMask, here are a summary of the most popular instance segmentation algorithms you can search for:
- Mask-RCNN (2018): An extension of the Faster-RCNN algorithm thanks to the addition of a segmentation branch.
- CenterMask (2020): An anchor-free instance segmentation model that is based on the CenterNet algorithm (that predicts object centers rather than bounding boxes, and thus can also do 3D object detection)
- BlendMask (2020): An algorithm that uses the attention mechanism and a feature pyramid network to dynamically combine features from different levels of a convolutional neural network, and achieves state-of-the-art performance on several benchmark datasets.
- YOLACT (2020): A real-time instance segmentation algorithm that combines the speed of object detection with the accuracy of instance segmentation by using a set of parallel convolutional layers to predict instance masks.
- SOLO (2020): A fully convolutional instance segmentation algorithm that assigns instance labels and predicts pixel-wise segmentation masks in a single forward pass.
- HTC (2020): A model that uses the cascade idea to combine predictions from multiple detections and segmentation streams.
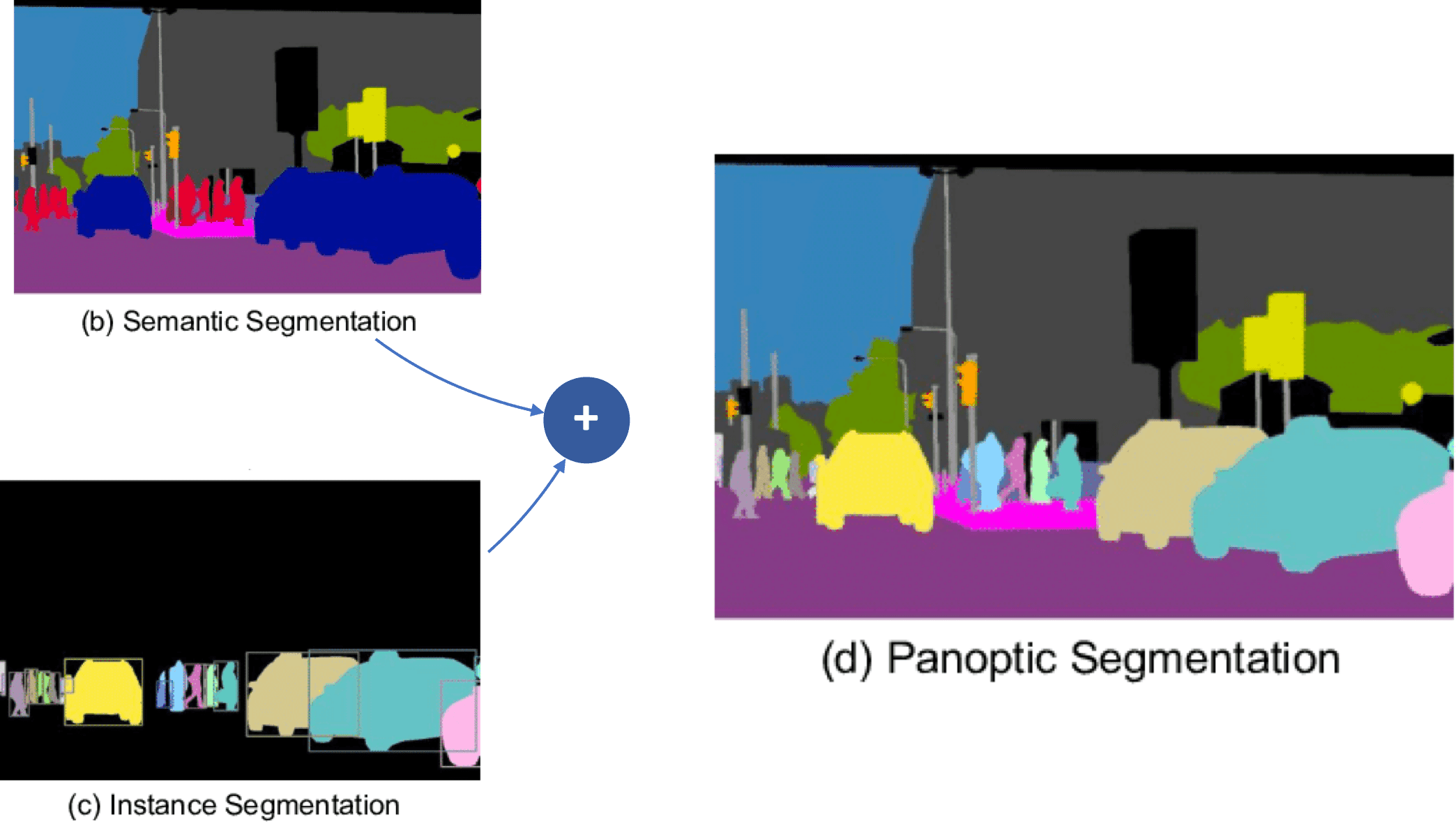
Panoptic, Semantic, and Instance Segmentation
The world of image segmentation is actually much bigger than these two ideas. Many years ago, one of the most asked question was "semantic segmentation vs instance segmentation: which one is best?". And of course, the need is different for them both.
When semantic segmentation is the task of classifying every pixel of an image, instance segmentation is the task of classifying every pixel of an object.
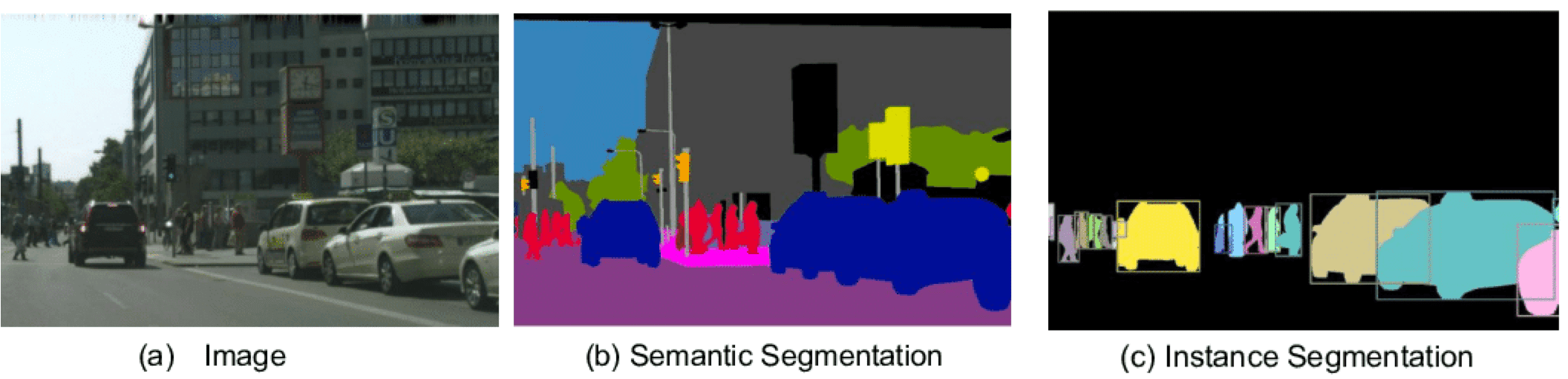
But semantic segmentation cannot tell the difference between two objects of the same class. If two objects with the same category "car" are detected, the colors stay the same. With instance segmentation methods, we are able to get a richer output format, and thus differentiate between the different instances. But we still don't get the full picture.
So semantic segmentation vs instance segmentation is a lost fight: The only way to do both is to perform something called Panoptic Segmentation.
We get the better of both world: We can assigns a single semantic label to each pixel in an image based on its class, like "road", "car", "building", etc... but we also get to differentiate between separate instances of the same category.
Summary, and learning Instance Segmentation
Here is a summary of what we've been through:
- Instance Segmentation is the idea of augmenting object detection by adding a segmentation task to it. It brings many benefits, such as richer context understanding, as well as inference speed gains.
- In Mask-RCNN, we simply add a segmentation head to the architecture, and this branch predicts binary masks using an FCN approach.
- In an approach like YOLOv7, the segmentation branch is done using BlendMask, which is a model that uses the attention mechanism and fuses several masks together to perform the task.
- There are many methods for instance segmentation, the most common are Mask-RCNN, YOLO-Seg, YOLOACT, BlendMask, HTC, SOLO, and more.
- When we fuse instance with semantic segmentation, we get panoptic segmentation, which brings the better of both worlds.
- We can use instance segmentation in many fields, from self-driving cars to robotics to satellite imagery.
There are many real-world applications of semantic segmentation, you can read my article about that here. Now if you also need to work at the object level, then there are additional use cases. One interesting example is the nuclei segmentation done for the 2018 data science bowl. When done right, it can also be integrated in surgery robots, as in this repo. Instance segmentation can be used with aerial images, target detection and tracking, agriculture, cinema, robotics, and many more...

As a computer vision engineer, learning instance segmentation is not only a nice way to get deeper in Computer Vision, it's before anything an excellent way to get started with Multi-Task Learning. Too many engineers still think of neural nets as "one task", but history has proven many times how neural networks can be used for more than one task. It's the case with the instance segmentation models, but also with object detection (the models do both regression and classification), as well as models purely built for multi-task.
An example from my Hydranets course, where the students learn build a network that can do both semantic segmentation and depth estimation: