

Path Planning for Self-Driving Cars
We’re now at the Path Planning step in which our car uses its knowledge of the environment and its position to plan trajectories.
This article follows :
- Introduction to Computer Vision for Self-Driving Cars
- Sensor Fusion - LiDARs & RADARs in Self-Driving Cars
- Self-Driving Cars & Localization
In our initial drawing, we're now at the Path Planning step.
In Planning, we now make decisions. This subject is one of the most difficult of all, it’s about implementing the brain of an autonomous vehicle.
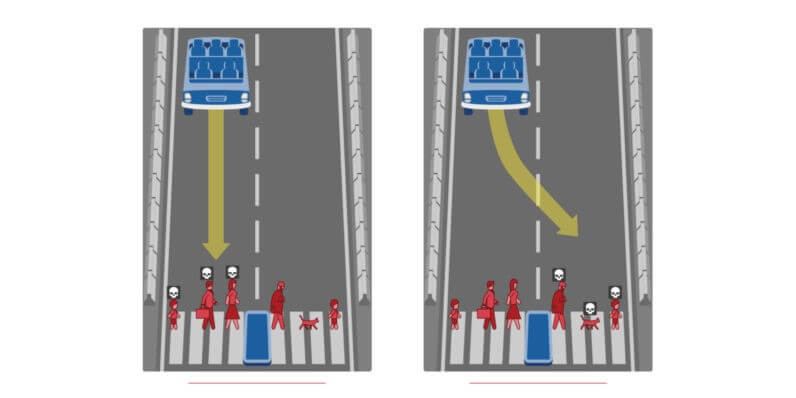
This image is a popular moral problem where we must choose who to sacrifice if we have no brakes. Although unlikely, this topic makes us wonder how a self-driving car would do if it had to take its own decisions.
📩Bonus: Get the Self-Driving Car Engineer MindMap and learn how Planning fits in Self-Driving Cars, along with the other modules.
Predictions
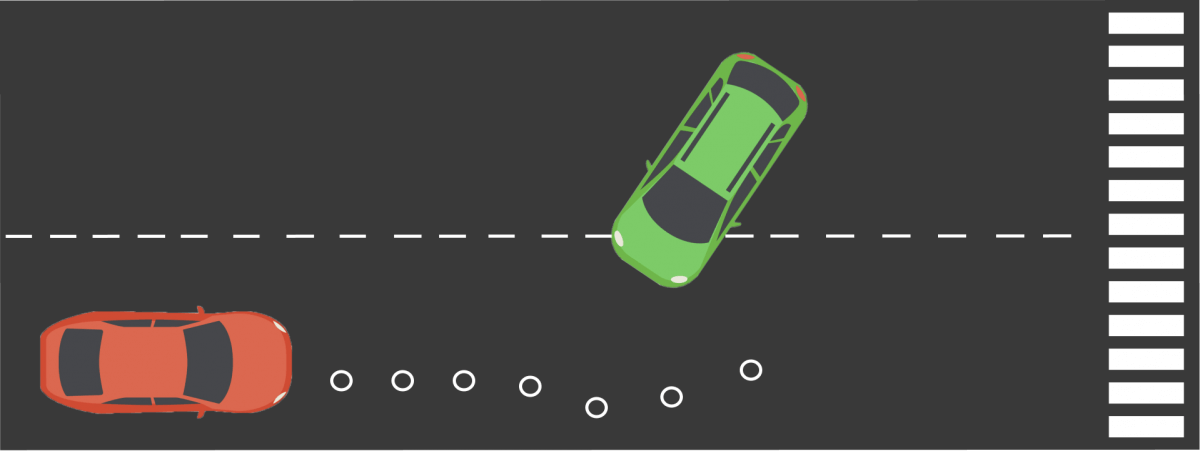
The detected vehicle can do several things:
- Stay in its lane, which means :
- Speed Up,
- Slow Down, to let us pass in front of him,
- Stay at constant speed, and ignore us - Change lane, which would make it easier for us.
So we have four possible situations to define for a motorway insertion.
Our sensors work in real time so it is possible to decide whether a vehicle changes gears or lanes simply by calculating its position and speed at every moment.
In our case, we are updating four possible scenarios, and thus have a multimodal distribution. This means that each scenario has a probability that changes with the observations we do.
This technique implements the feasibility of a trajectory, and therefore eliminates impossible behaviors. It only focuses on what is possible and not on what has been done in the past.
Data-driven (Machine Learning) approach
This approach is very different.
Like every Machine Learning algorithm, we define two stages, a training phase and a prediction phase.
The training phase gathers massive data on the history of vehicles and learns from these data. We can have hundreds of vehicles that have done hundreds of different behaviors in an intersection.
We perform unsupervised learning. Clustering algorithms help us to define, for the current observation, which trajectory group the vehicle is approaching. As a reminder, clustering is a technique where we define a number of clusters (trajectories) and where we ask an algorithm to indicate which data are similar.
Each cluster is actually a typical trajectory that a vehicle can follow. The advantage of this technique is to rely on data and therefore on past scenarios. The more we drive and collect data, the more precise we will be in estimating behavior.
These two approaches are very different and actually reflect the reality of the autonomous vehicle industry. While some rely on deterministic cases with mathematical prediction, others rely on statistics using artificial intelligence. This choice of companies is more broadly extended to many issues such as the perception using LiDAR against the perception using cameras.
Decision-Making

Once we have an estimate of the future of the environment, we can make a decision. How to brake if a pedestrian is detected? How to accelerate or change lanes?
The first thing we have to do is environment classification. The choices are not the same whether we are driving on a highway or in a parking lot. Several criteria are taken into account when generating a trajectory, in particular safety, feasibility, efficiency and legality. Other variables can also be taken into account such as passenger’s comfort.
Finite-State Machine
The first decision-making method that can be used is a finite state machine . The principle is to define, according to the situations, the possible states of a car. On a highway, the state of a car may be to stay in a lane, change lanes to the left, or change lanes to the right. Depending on the traffic conditions, we change state to, for example, overtake a car.
The choice of states is usually made using cost functions. For each possible scenario, we calculate independent costs (distance to obstacles, legality, …), and add them up. The lowest cost scenario wins.
Here we define what is important. We cannot do an impossible or dangerous maneuver.
Total_Cost = Feasibility_Cost * 5+ Security_Cost * 4 + Legality_Cost * 3+ Comfort_Cost * 2 + Speed_Cost * 1
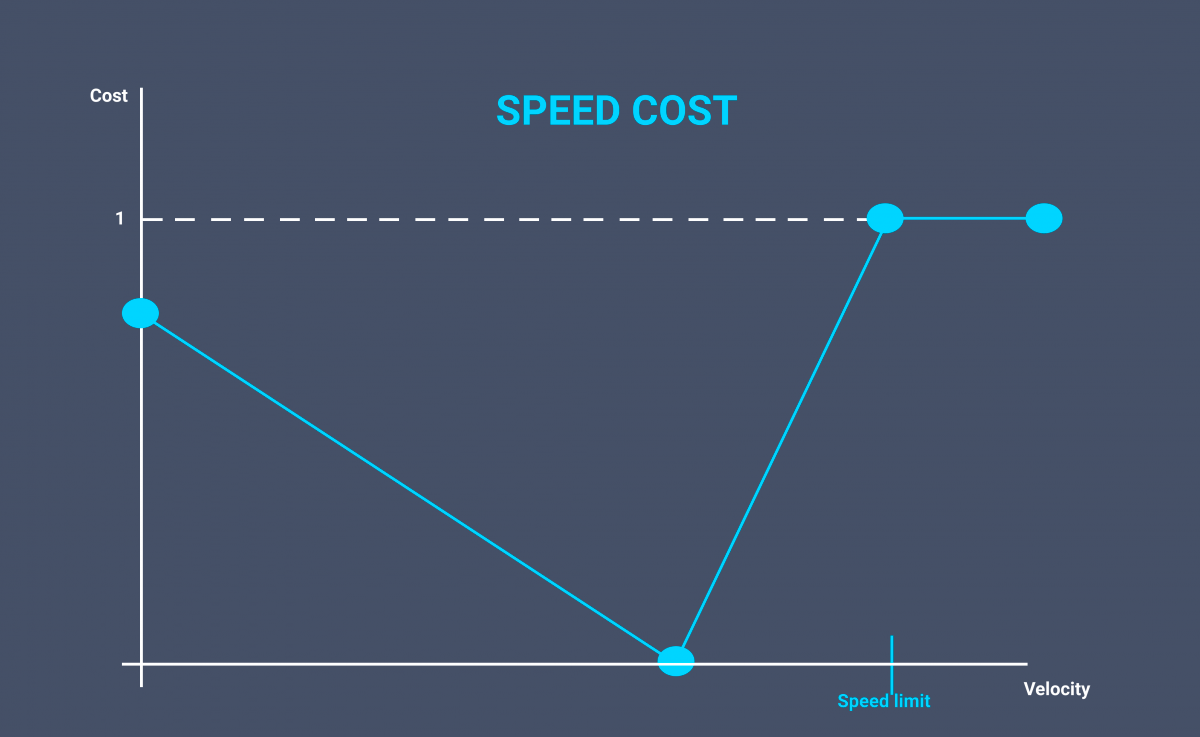
In the cost function for speed, we do not want our vehicle to be too slow or exceed the maximum speed allowed. We therefore define a decreasing cost according to the speed then maximum after the speed limit.
Decision making is a very delicate subject when talking about autonomous driving. We must take into account the current situation and decide on everything that can be done from this point. Then we must weigh the pros and cons of each possibility and finally choose the best solution.
Trajectory Generation

The final step is trajectory generation.
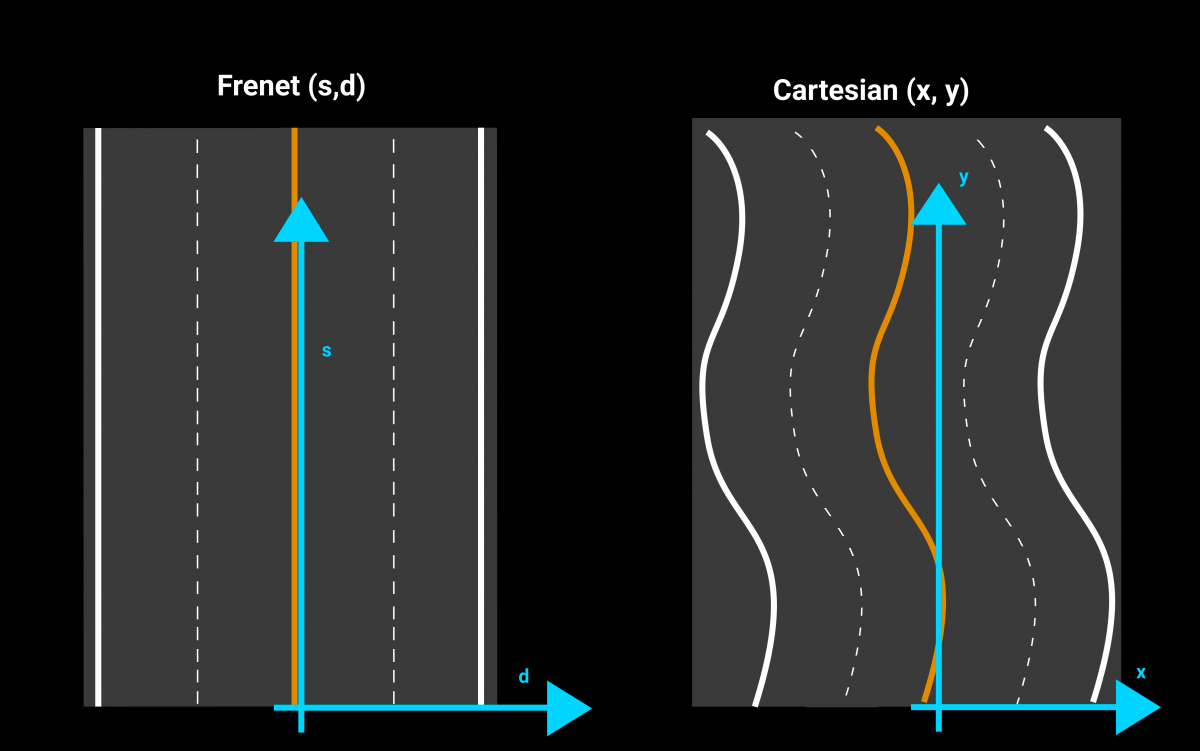
In this step, it is necessary to use a different coordinate system than the Cartesian coordinate system. For good reason, the cartesian coordinate system takes into account the dimension (x; y) but does not make sense if we want to find one’s bearings in relation to the road. The Frenet coordinates contains two axes, an s axis indicating the advance relative to the track and a d axis indicating the distance to the center of the lane. This marker is the one on which we base ourselves to estimate if our trajectory deviates from the center of the lane or if a vehicle is ahead of us or behind us.
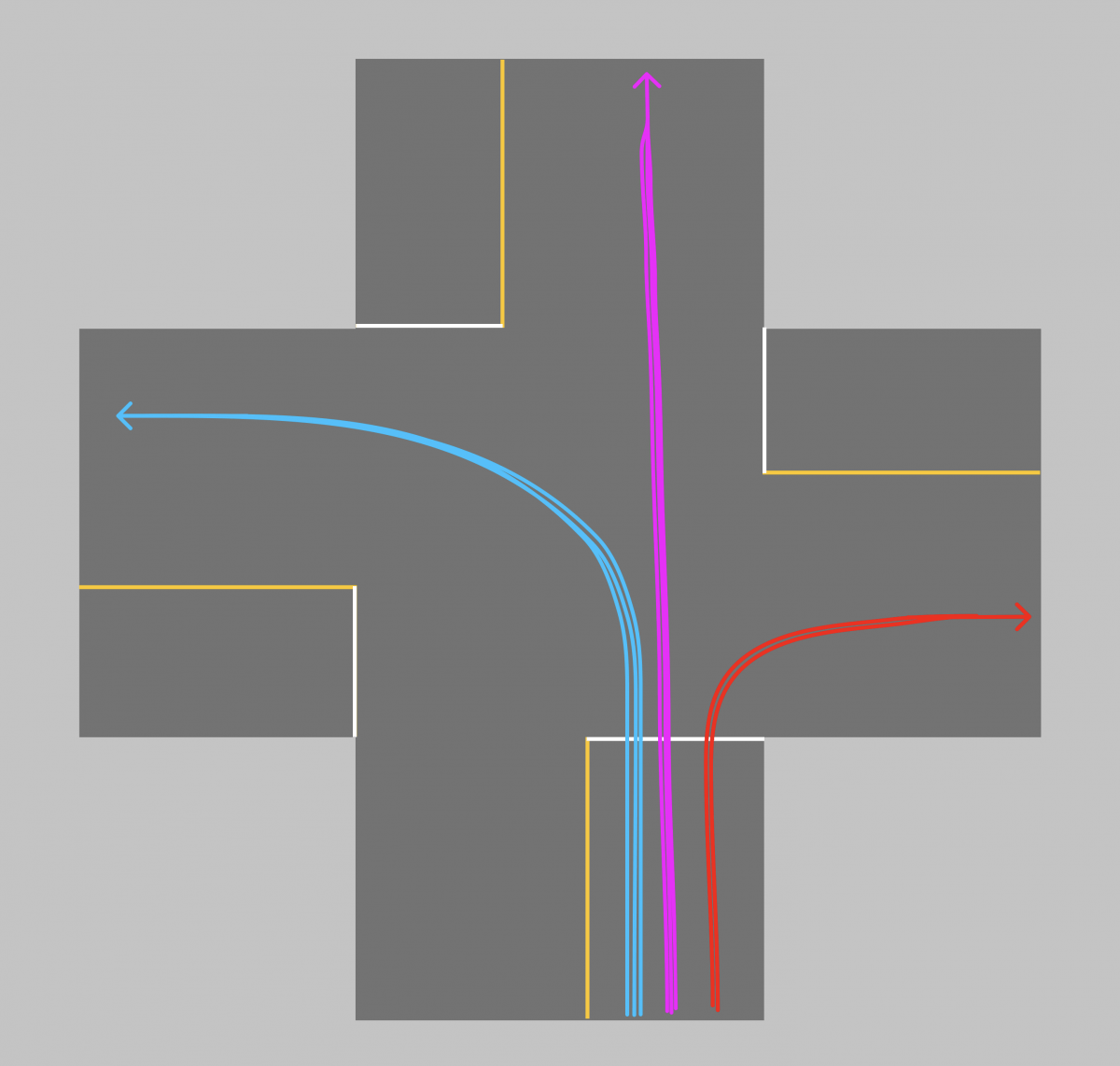
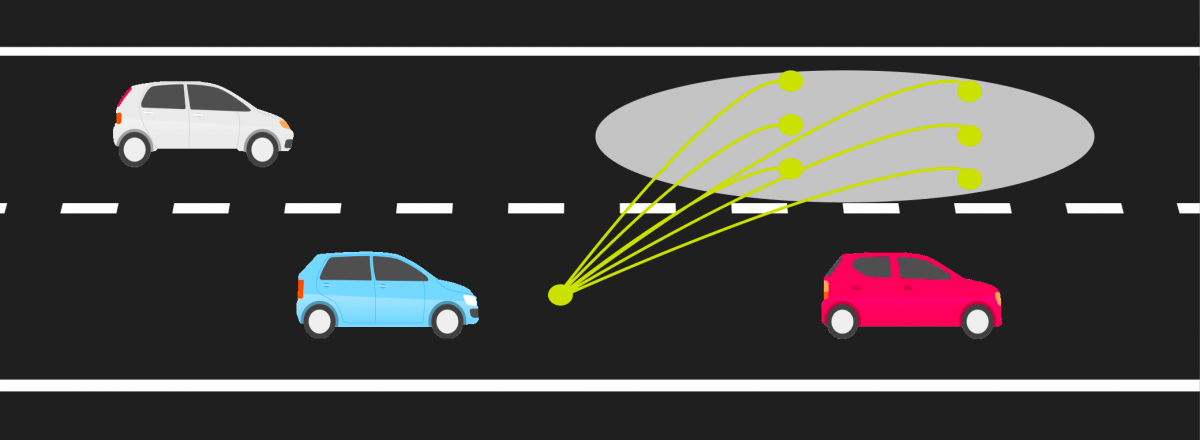
When we take the decision to overtake a vehicle, the algorithm generates several trajectories for a decision and chooses the best one according to the criteria of feasibility, safety, legality, efficiency, comfort, …
In this case of overtaking, the red / orange trajectories are dangerous, the yellows are acceptable but incomplete, the green is the most efficient and safe.
To generate this trajectory, we create a level five polynomial that passes through waypoints. Waypoints are points on the way that contain 3 dimensions :
S: The longitudinal distance
D: The lateral distance
T: The moment at which one must pass through this point; giving speed
A trajectory is a curve that goes through all these points. These points are positioned in space and time. They tell us when to move to a specific (x;y) position and how fast. If you want to brake at a pedestrian crossing, we create points up to the pedestrian crossing and set a decreasing velocity to the speeds of the points up to the stopping zone.
Path Planning
We have just studied the generation of low-level trajectories. What about higher level? How to decide which street to take?
What are other path planning algorithms ?
We have several families of algorithms to plan a path from a starting point to an end point. In these algorithms, we consider the world to be a grid containing obstacles, a starting point, and a goal.
Results
As part of my Nanodegree on autonomous vehicles, I realized a project on highway driving. I had to develop an algorithm that could drive 7.5 km among other vehicles on a highway. The Finite-State Machine introduced earlier is used to overtake a slow vehicle or slow down if overtaking is not possible.

Conclusion
Autonomous navigation is an exciting subject.
We drive with our intuition and our eyes respecting the rules of the road. To reproduce this in a computer, you have to go through all the steps that we have done.
We must see, position ourselves, predict the behavior of other vehicles, and finally make a decision by integrating constraints such as the law or the comfort of passengers.
Behind the machine, a human tells what are the actions we must privilege in certain situations. The machine only reproduces what it’s taught. This subject leaves room for a very large number of research and experimentation works.
It allows to reach the level 5 of autonomy and democratize permanently the arrival of self-driving vehicles.
📩 In this article, we’ve seen how Path Planning works for self-driving cars! I now invite you to Join my Daily Emails on Self-Driving Cars where you’ll learn tons of other use of AI, and receive the Self-Driving Car Engineer MindMap!




