Finally understand Anchor Boxes in Object Detection (2D/ 3D)
Have you ever tried to study an object detection algorithm? Like going really in-depth about it? If so, you might have stumble across a concept called anchor boxes!
A few years ago, I was trying to understand the YOLO algorithm, which is a One-Stage 2D Object Detection algorithm, and I came across this idea of "anchor boxes". I started by reading some blog posts, but even after reading nearly all of them, I couldn't really "get it". Today, I would like to explain it in an easy, and somewhat more complete way.
We'll see what are anchor boxes in object detection, why and when we need them in a network, and we'll also explore drawbacks and new alternatives. This article won't reexplain object detection, it assumes you know most of it, but are stuck at anchor boxes.
Let's get started:
What is an anchor box in object detection?
Intuitively, how would you predict a bounding box? The first, most obvious technique, is the sliding window. You define a window of arbitrary size, and "slide" it through the image. At each step, you classify whether the window contains your object of interest.
This is what you thought about, right? Well, an anchor box will be the "Deep Learning" version of it. It's faster, and also more precise. Take this image, and see how the sliding window doesn't help us being precise enough.

You get the point, do you? Some windows should be incredibly small, and others should be bigger. Similarly, some boxes should be vertical, like those of pedestrians, and others should be horizontal, like buses.
This is where the concept of anchor boxes comes into play, using an anchor box, we're going to predefine a set of plausible boxes for the classes we want to detect, and then predict them.
So let's imagine an example of what an anchor box can be:

See? It's better than the sliding window, because we're pre-setting some shapes.
Why an anchor box is different than a bounding box
There is a concept we however must understand:
An Anchor Box is not a Bounding Box!
You want to predict a bounding box, and for this, you'll use an anchor box as a helper. So let me show you how.
First, we will take one anchor box, and put it everywhere on the image, just like for sliding windows:

But notice how none of these anchor boxes can be our final bounding box. And with that, we only have one shape of anchor boxes. As a result, none of these approaches work!
So let's step back:
When you're looking at the architecture that allows for box generation, you have something like this:
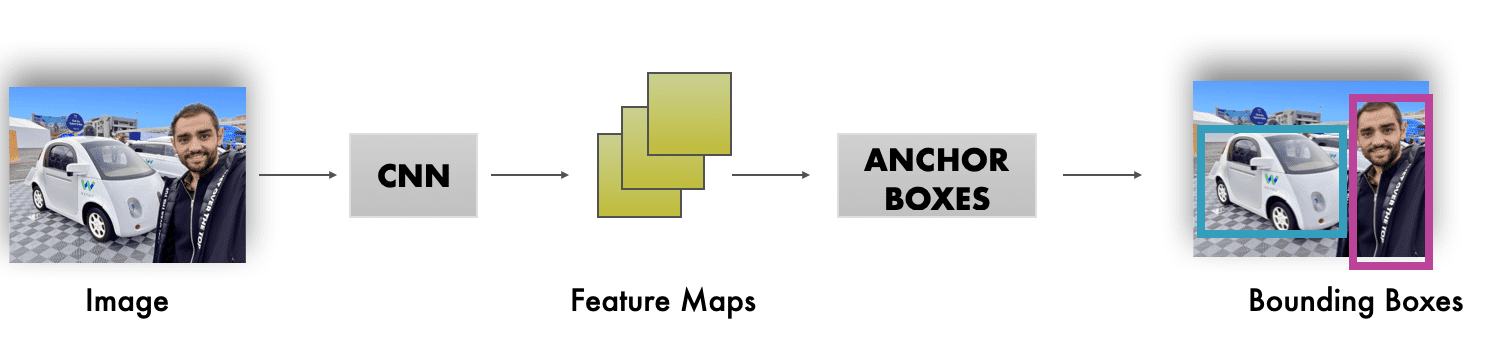
Which means that:
- Anchor Boxes are used on top of feature maps, not on images
- Anchor Boxes are used to generate bounding boxes, but they aren't the bounding boxes
So how does that really work? Let's find out.
How does a network generate anchor boxes?
So we know that you use anchor boxes on feature maps instead of images. Which means you'll start by extracting features, and that you'll then define a set of anchor boxes on these features.
Our anchor boxes will be applied on features, but we still need to "assume" the shape of our boxes. Will they all be vertical rectangles? Will some of them be squares? What will their smallest size be? Or biggest size? We need to play with different options, if we want to catch small and far objects, or big and nearby ones.
How? You usually do some of it manually, and some of it by looking at your dataset and using a clustering algorithm like K-Means. After all, this kind of algorithm can tell you what are the typical anchor boxes used.
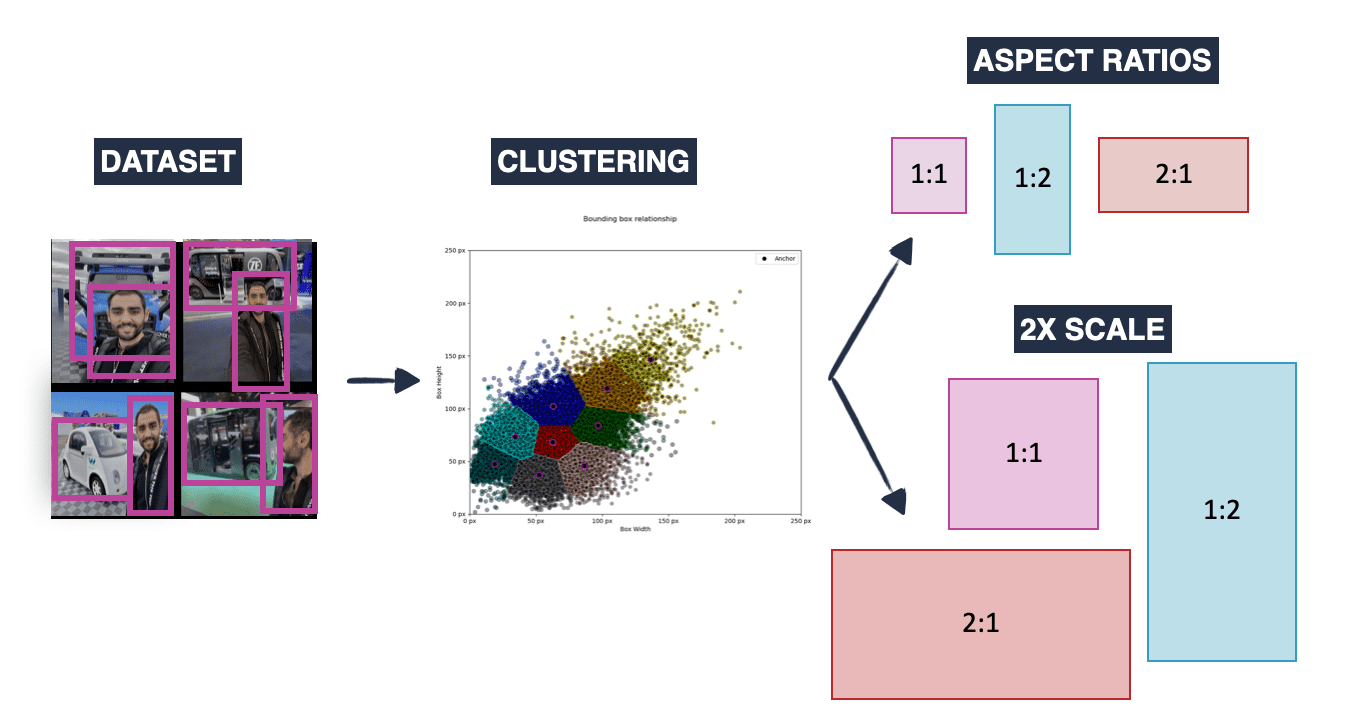
Once you have these, you'll generate multiple anchor boxes of a certain size (16,32), (32,32), (32, 16), and then have variations of these both in aspect ratio and scale (2x, 3x, 3x, ...). You end up with lots of possible boxes!
Now, practically, how do you generate these anchor boxes once in the network doing inference? For that, we must first get into the object detection algorithm we're using.
- For example, if we're using Faster-RCNN, we're going to start using a Region Proposal Network (RPN), and this network is going to generate a set of possible locations for our objects. At these locations, we can regress our anchor boxes.
Example, we can decide that we want an anchor box of size 16x16, with two types of aspect ratio: 1:1, 1:2, and 2:1, and with 2 types of scale: x1, and x2. Which means we end up with 6 anchor boxes per region:
- 16x16 - the 1:1 box of scale 1
- 16x32 - The 1:2 box of scale 1
- 32x16 - The 2:1 box of scale 1
- 32x32 - The 1:1 box of scale 2
- 32x64 - The 1:2 box of scale 2
- 64x32 - The 2:1 box of scale 2
The advantage of this is that you use all the anchor boxes to cover multiple shapes (square, wide, long), and multiple sizes (32x32 would be for small objects, and 512x512 for big ones).
So imagine we want to do face detection, we'll have something like this:
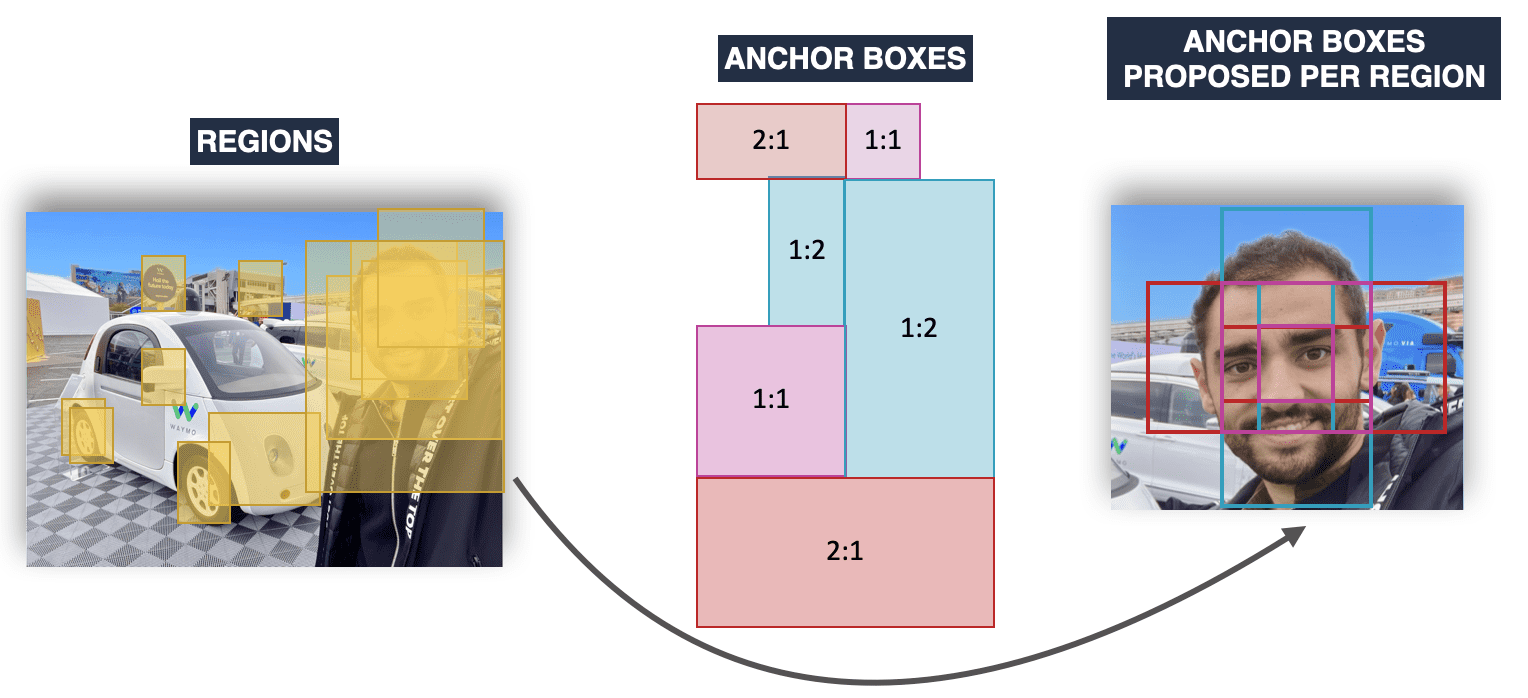
So using RPN, or YOLO, you have "plausible" boxes, but it's not yet our final bounding box.
How do you get the final bounding box?
From Anchor Boxes to Bounding Boxes with Anchor Box Offsets
Think about this: After you've proposed regions or cells, you generate thousands of anchor boxes. But most of them aren't going to be perfect. In many cases, not even ONE anchor box becomes the ground truth bounding box.
This is why we need to understand that a neural network doesn't predict a bounding box, it predicts an offset with reality.
How much in phase are you with reality? Have you ever been called irresponsible? Or did you ever meet people who were not in line with reality? Well, anchor boxes have the same problem. We want them to be perfect, but they aren't.
Which is why after we've generated our anchor boxes, we're going to look the center of these boxes, and we're going to look at the ground truth bounding box, and we're going to analyze the difference between the center and the ground truth bounding boxes.
Example:
Still on face detection, we've generated lots of boxes. Now let's only keep the most likely 1:1 anchor box. We're going to predict our anchor boxes, then keep the one that has the highest Intersection over union (IOU) with the ground truth box, and finally refine it.
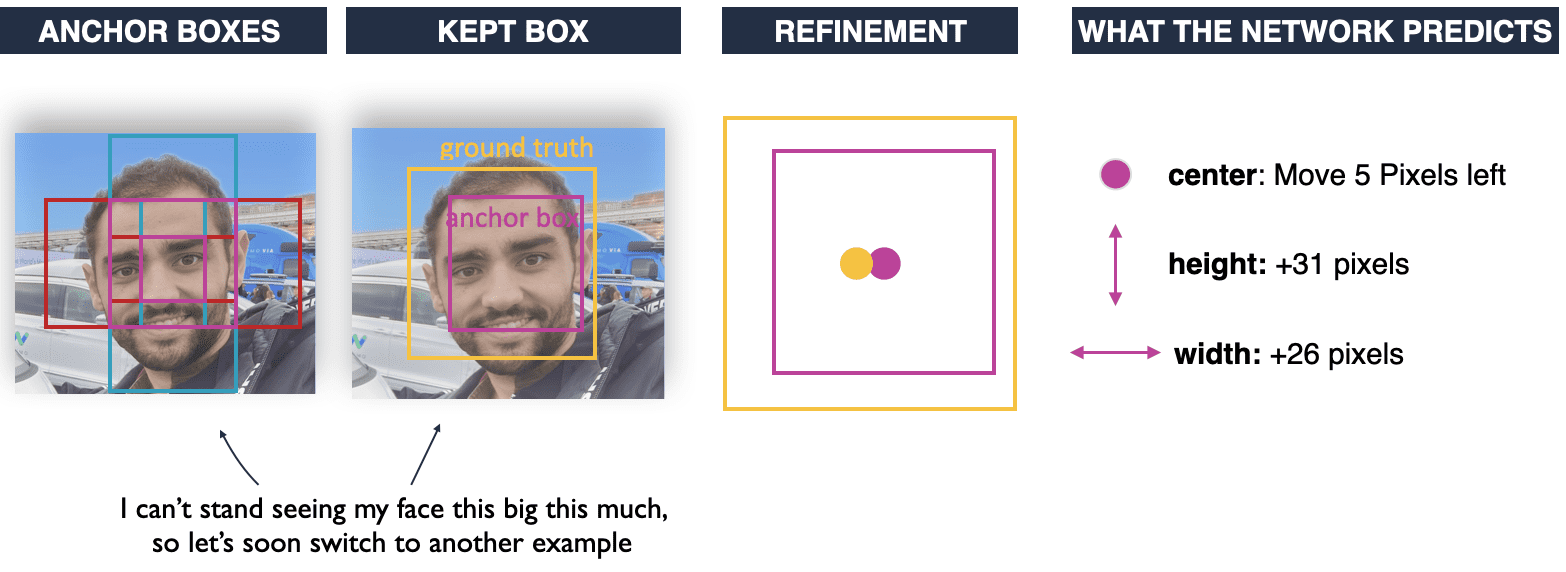
Let me repeat it:
A bounding box is a refined anchor box!
See what the network learns: a displacement between the anchor boxes needed to get from the original anchor box position to the ground truth. It learns the anchor box offsets! We take the anchor boxes centered around the potential final bounding box, and we end up refining the process by learning a shift.
The rest is classical — Our algorithm will draw multiple bounding boxes, and we will use Non-Maxima Suppression to remove some of the boxes based on IOU, only to keep a few remaining anchor boxes per class. This will work when we have multiple objects, including when they overlap.
What if we don't want to use anchor boxes?
Anchor boxes have been an amazing boost in object detection; yet they aren't perfect. And you may already get the reason: if we consider all our objects to be squares or rectangles, what happens to the objects that aren't fitting this shape?
Another issue is the number of boxes needed to get one final box. If we want to detect small objects, we'll need to generate thousands of small anchor boxes we'll probably never use, just for this one time a small object appears.
An example here of just a sample of the anchor boxes generated for one region:

Because of this issue, there have been some anchor free object detection approaches, such as:
- CenterNet: This approach defines keypoints or landmark points on objects and trains the network to predict the location of these keypoints. This allows the network to better localize the object without relying on generated anchor boxes.
- YOLO: YOLO is a grid-based algorithm. It does use anchor boxes, but it doesn't generate millions of them. Each grid cell is responsible to predict a few anchor boxes. So it's fewer anchor boxes, and in some versions of YOLO, it's no anchor box at all!
- Cascade R-CNN: This approach uses a series of detectors to refine the bounding boxes of objects. The first detector generates coarse proposals, and subsequent detectors refine the proposals, allowing the network to accurately localize objects without relying on predefined anchor boxes.
Okay, now let's see examples of anchor boxes in 2D and 3D!
Example 1: Anchor Boxes in Faster-RCNN
The Faster-RCNN architecture is one of the most popular approach for 2D Object Detection. It's a 2-Stage algorithm: the first stage generates multiple bounding boxes using a Region Proposal Network (RPN), and the second stage will classify and refine them.
How does the RPN work? If you look at the paper, you'll see how we start with several anchor boxes, and then get them refined:
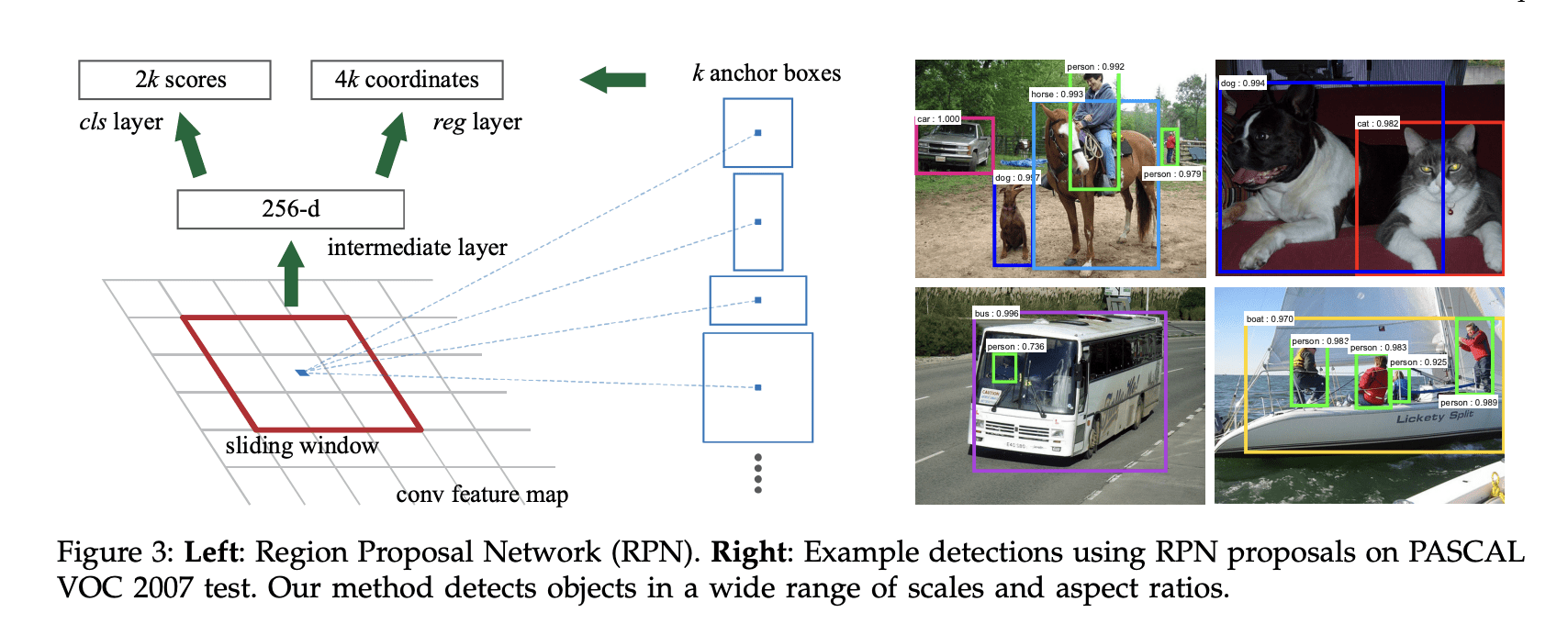
If I copy paste the author's explanation, we get:
At each sliding-window location, we simultaneously predict multiple region proposals, where the number of maximum possible proposals for each location is denoted as k. So the reg layer has 4k outputs encoding the coordinates of k boxes, and the cls layer outputs 2k scores that estimate probability of object or not object for each proposal4 . The k proposals are parameterized relative to k reference boxes, which we call anchors. An anchor is centered at the sliding window in question, and is associated with a scale and aspect ratio (Figure 3, left). By default we use 3 scales and 3 aspect ratios, yielding k = 9 anchors at each sliding position.
So again, this confirms that we have several anchor boxes, and that these are used to then become one bounding box.
You can find a complete explanation of the Faster-RCNN architecture and family (+ one shot approaches) in my course MASTER OBSTACLE TRACKING.
Example 2: Anchor Boxes in 3D
Some other object detection algorithms will use anchor boxes in 3D. For example, Point Clouds object detectors, or 3D Object Tracking systems. The process will be very similar, but we'll generate 3D anchor boxes rather than 2D anchor boxes, which means we'll need to predict a shift in an additional dimension (the depth), as well as the orientation of the boxes!
An example with a notebook that comes from the upcoming LiDAR Object Detection DLC, that will get released on Think Autonomous. The anchor boxes are generated at several scales, sizes, and aspect ratios, and then encapsulate the point clouds.

It looks cool, doesn't it? What I love with 3D is how we can take ideas from 2D and transpose these to the 3D world by just adding a few parameters.
It's now time to summarize what we've seen today:
Summary
Anchor Boxes are a key-player in object detection. They're the Messi or Argentina, and the Mbappé or France. Understanding how they work matters, because if you understand these concepts, you can then tune them, and thus get better results. You can learn to tweak the tradeoff between accuracy and speed just using this principle.
So let's recap what an anchor box is:
- In Object Detection, the concept of anchor box is crucial and used in almost every modern algorithm to predict the bounding box coordinates.
Generating anchor boxes is done using a clustering algorithm like K-Means on the dataset labels. We're looking at the overall size, shape, and aspect ratio of the bounding boxes, and we then define anchor boxes accordingly.
- We can also get an anchor box by manual tuning.
- We use anchor boxes to generate bounding boxes, the concepts are related but not exactly the same; an anchor box is the original, standard shape and size; a bounding box is a refined anchor box.
- When estimating bounding boxes, the object detector is responsible to regress the bounding boxes. In Faster-RCNN like approaches, we're using a Region Proposal Network to propose bounding boxes. In YOLO, we're using grid-cell division, and each cell predicts a set of anchor boxes.
- There are alternatives to anchor boxes, such as keypoints prediction, or grid-based detection, but anchor box prediction remains the standard in object detection.
- Anchor boxes also exist in 3D, and I'm talking about it in my upcoming Deep Point Clouds DLC.
This sums up our anchor box article!