Deep Learning in Self-Driving Cars
The very first self-driving car used Neural Networks to detect lane lines, segment the ground, and drive. It was called ALVINN and was created in 1989.

Great Scott! Neural Networks were already used back in 1989! The approach was End-To-End: you feed an image to a neural network that generates a steering angle. Et voila. In 2021, it’s even crazier. Deep Learning has taken over the major subfields of autonomous driving.
In this article, I’d like to show you how Deep Learning is used, and where exactly. In order to do this, I will go through all 4 pillars of autonomous driving, and explain how Deep Learning is used there.

In a few words:
- In Perception, you find the environment and obstacles around you.
- In Localization, you define your position in the world at 1–3 cm accuracy.
- In Planning, you define a trajectory from A to B, using perception and localization.
- In Control, you follow the trajectory by generating a steering angle and an acceleration value.
In this article, you will learn how Deep Learning is implemented on all 4 modules, and if you’re aspiring to work on self-driving cars, which skills you need to learn to be a Deep Learning Engineer.
👉 To write this article, I'm going to use a MindMap that details the list of Deep Learning algorithms in self-driving cars. If you'd like to download this MindMap, it's here.
Let's begin with my favourite topic: Perception.
Deep Learning in Perception

Perception is the first pillar of autonomous driving, and as you may have guessed, there is a lot of Deep Learning involved. Every student going through his first Deep Learning course will hear “Deep Learning is used in self-driving cars to find the obstacles or the lane lines”.
Perception generally uses 3 sensors:
To understand these 3 sensors, you can check the introduction of my Sensor Fusion article.
Camera Detection
In the following graph, I'll show the most significant use cases, how they’re implemented, and how to learn to implement it yourself.
In light yellow, you will see how to solve the tasks using traditional techniques.
In dark yellow, you will see how to solve the tasks using Deep Learning.
In blue, these are online course recommendations if you want to learn.

As you can see, Computer Vision is requiring a lot of Deep Learning for the task of detection.
In Lane Line Detection and Segmentation, we use Deep Learning over traditional techniques because they’re faster and more efficient. Algorithms such as LaneNet are quite popular in the field of research to extract lane lines.
👉 To learn more about it, you can also check my article on Computer Vision .
2D Object Detection is also at the heart of Perception. Algorithms such as YOLO or SSD have been very well explained and are very popular in this field. They’re constantly updated, replaced with new ones, but the idea is similar.
👉 If you’d like to learn more, here’s my research review on YOLOv4.
Finally, many camera setups are made in Stereo. Having Stereo information helps us build what’s called a Pseudo-LiDAR. We can completely emulate and even sometimes replace the LiDAR, and therefore do 3D Perception with cameras (2D sensors). For that, we used to implement Block Matching using traditional Computer Vision… and we’re now switching to Deep Learning.
👉 My article on Pseudo-LiDARs.
LiDAR Detection
(source)
First, traditional approaches based on the RANSAC algorithm, 3D Clustering, KDTrees and other unsupervised learning techniques are still the go-to for many robotics applications.
👉 I teach these in my Point Cloud Fast Course if you’re interested.
However, these aim to be replaced by Deep Learning approaches, faster and safer. Why? Because naïve algorithms can’t classify, or tell that two very close people are indeed two people. A learning approach is more suited here.
Many object detection in 3D papers have been released by companies such as Apple (VoxelNet), UBER ATG (PIXOR and Fast and Furious), nuTonomy ( PointPillars), and the University of Oxford ( RANDLANET).
At the heart of it, we find techniques such as 3D CNNs (Convolutional Neural Networks) or PointNet. These are the fundamentals of 3D Deep Learning.
These days, LiDAR detection using Deep Neural Networks is booming. That’s one of the most active area of research in self-driving cars.
RADAR Detection
RADAR is a very mature sensor. It’s over 100 years old, and it’s no shame to say it doesn’t need Deep Learning to be efficient. Using RADARs, we’ve been able to measure obstacles speed for decades. In fact, if you’ve got a speed ticket lately, it’s because of RADARs.
👉 The techniques used for this are well explained in my dedicated article .
Deep Learning in RADARs is starting to emerge with algorithms such as Centric 3D Obstacle Detection or RADAR Region Proposal Network . However, it seems to still be early research.
Sensor Fusion
The final part of Perception is Sensor Fusion.
To make the detection “sure”, we include what’s called redundancy. The idea is simple: we merge data from sensors and check if they tell the same thing.
There are 3 ways to merge for a company using all 3 sensors:
- Merging Camera and LiDAR
- Merging Camera and RADAR
- Merging LiDAR and RADAR
Here’s a map that shows you all the ways we use Deep Learning in Sensor Fusion.

Every time, I make the distinction between early and late fusion.
- Early Fusion means you’re fusing the raw data, such as LiDAR point clouds and Image pixels.
- Late Fusion means you’re fusing the output of the detections, such as a 2D and a 3D Bounding Box.
What’s interesting is that Deep Learning is more or less suited depending on the sensor used.
👉 For LiDAR camera fusion, a process such as the one I’m explaining in this article is used as a traditional approach.
But Deep Learning starts to be very well suited for this process.
Since we handle Deep Learning well with the camera and LiDAR, it’s understandable why we use Deep Learning for the fusion of the two.
Since RADARs don’t use a lot of Deep Learning, it’s more complicated and you’ll find more approaches involving Kalman Filters , IOU matching and tracking .
Again, you can start to see the impact of Deep Learning in Sensor Fusion. The discipline is usually very traditional, uses a lot of robotics and bayesian filtering. It tends to use Computer Vision feature detectors rather than CNNs… and now, it’s transforming into a Deep Learning discipline.
I have a complete recap of Perception:
Deep Learning in Localization
Localization is about finding the position of the ego vehicle in the world.
The first thing that comes in mind is to use GPS, but you’ll find out it can be very inaccurate and might not work perfectly every time, for example when it’s cloudy.
In the end, GPS is accurate to 1–2m, while we’re targetting 1-3 cm.
This problem created a whole field we call localization.
Depending on the algorithmic choice, we have many ways to do localization:
Knowing the Map and the initial position
Imagine you’re in New York, on the 5th Avenue (I miss traveling😗). And imagine you have a map of the Big Apple. Theorically, you just need to count how many steps you took in the streets to know where you’ll be after a 10 minutes walk. That’s the first case, you have the map (New York) and your position.
Knowing the Map, but not the initial position
Now imagine you’re still in New York, but you’ve been kidnapped, blindfolded, and placed somewhere else. You’ll need to use your eyes and knowledge of the map to determine your position. When you recognize something familiar such as the Empire State Building, you’ll know where you are!
These two things therefore rely on something we called landmark detection. We want to detect things we know and which are in the map.
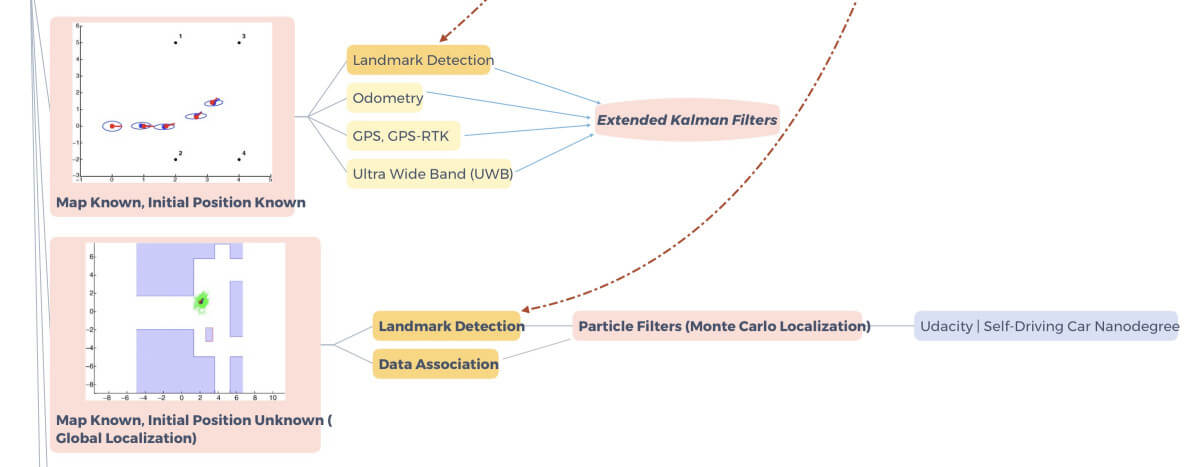
To do this, we use Extended Kalman Filters and Particle Filters.
👉 The difference is explained in my article on Localization .
As you noticed, we’re also using Odometry (how much the wheels spin, GPS, GPS-RTK (a better GPS), and UWB (trilateration using physical devices).
If you’re looking for Deep Learning, there’s just the landmark detection, that is obtained in the Perception step.
Knowing neither the Map nor the initial position
Now imagine you’re kidnapped, blindfolded, and put somewhere in New York but you don’t have the map.
That’s called Simultaneous Localization And Mapping (SLAM): you need to both locate and build a map of your surroundings.
The SLAM field originally uses a lot of Bayesian Filtering, such as Kalman and Particle Filters, but something called Visual Odometry is currently booming.
The idea is to use sensors such as cameras, or stereo cameras, to recreate an environment and therefore a map. Here’s a map of SLAM, and you can also read this paper to understand it better.
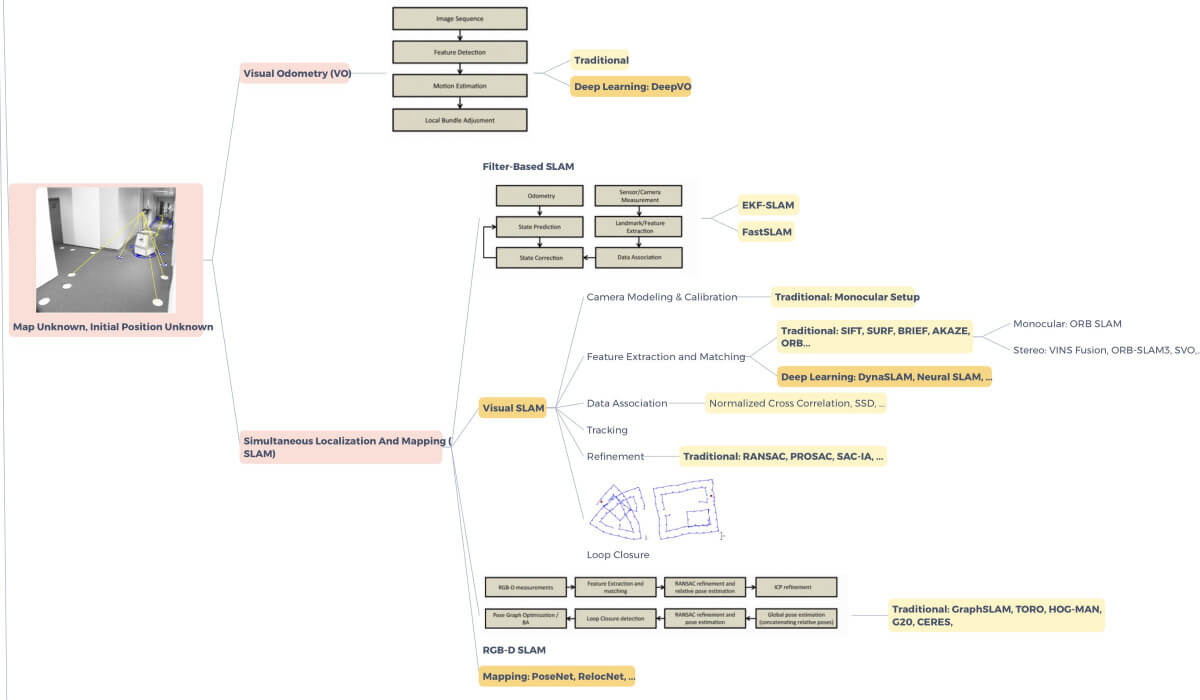
As you can see, there is a lot of Deep Learning involved for mapping and localization… but the field is primarly not using Deep Learning. If you’d like to be a localization engineer, it’s much more important to have a great understanding of robotics and traditional techniques than Deep Learning.
The explanation of this Localization Mindmap is here:

Deep Learning in Planning
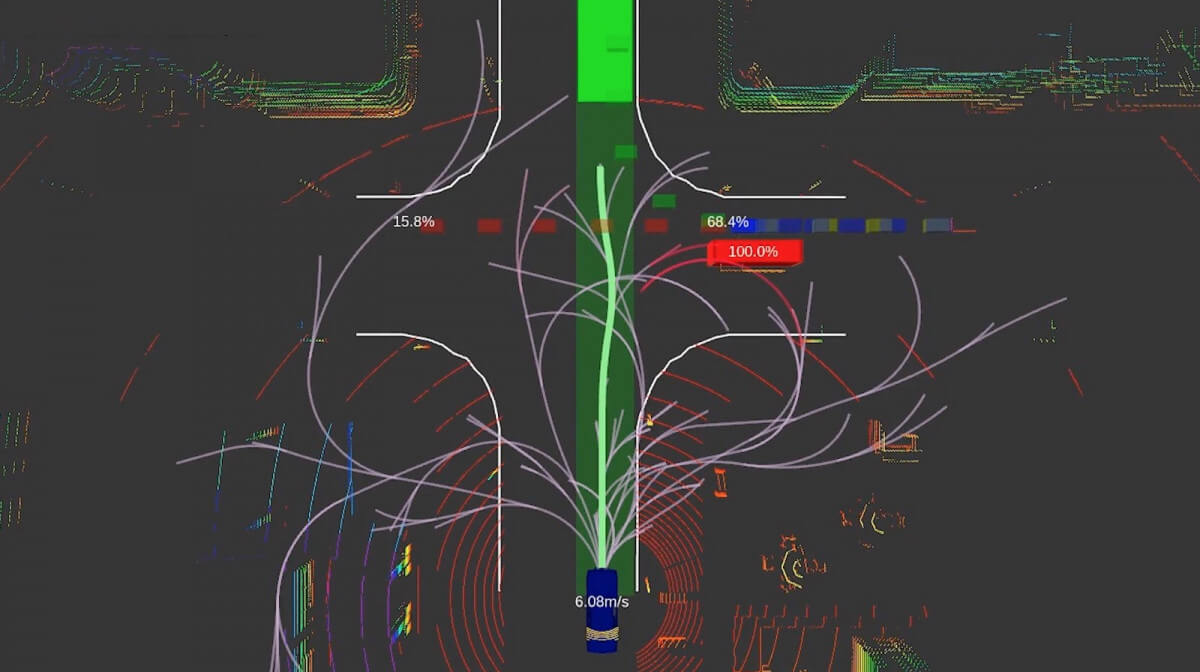
Planning is the brain of an autonomous vehicle. It goes from obstacle prediction to trajectory generation. At its core: Decision Making.
We can divide the Planning world in 3 steps:
- High-Level/Global Planning — Programming the route from A to B.
- Behavioral Planning — Predicting what other obstacles will do, and making decisions
- Path/Local Planning — Avoid obtacles, and create a trajectory.
To use Deep Learning in self-driving cars, the best way is to do Perception… but the second best way is through Planning.
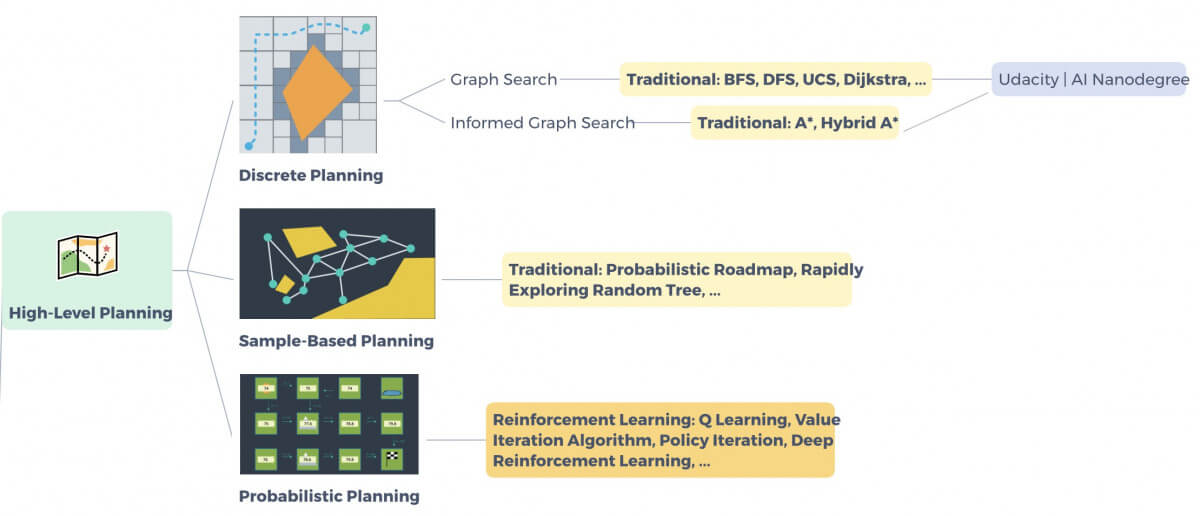
High Level Planning
The first thing is to program a route from A to B, like Google Maps or Waze.
For that, we’ll have to use Graph Search algorithms such as Dijkstra, A*, DFS, BFS, …
Commonly, A* is used.
But you’ll also find a lot of Deep Reinforcement Learning here: that’s called Probabilistic Planning.
Behavioral Planning
This step includes 2 sub-steps:
- Prediction
- Decision-Making
In prediction, we want to use time information and data association to understand where an obstacle will be in the future. Learning-based approaches such as Gaussian Mixture Models for Intent Prediciton can be found… and Kalman Filters approaches too; as in my most popular article Computer Vision for Tracking .

Decision-Making is something different. We either manually input some rules and create a Finite State Machine, or we don’t, and use Reinforcement Learning approaches.
Path Planning
Global Planning is good to know where you’re supposed to go in a map. But what if a car is blocking? What if the traffic light is red? What is a vehicle is very slow? We need to do something, like modifying the trajectory, or stopping the car.
A lot of algorithms such as Rapidly-exploring Random Trees (RRT), RRT*, Probabilistic RoadMaps (PRM), PRM*, … are in use.
In planning, if we use Deep Learning, it can mostly be in Prediction, or Path Planning using Reinforcement Learning approaches.

Deep Learning in Control & Other Applications
Control
Control is, as said in the introduction, about following the generated trajectory by generating a steering angle and an acceleration value.
When I first searched to write this article, I thought “There is no Deep Learning in Control”. I was wrong.
As it turns out, Deep Reinforcement Learning is starting to emerge in both Planning and Control, as well as End-To-End approaches such as the one ALVINN used.
Other Applications
The 4 pillars of autonomous driving are somehow all using Deep Learning. However, there are many other ways Deep Learning can be used….
Explainable AI, GANs to generate synthetic datasets, Active Learning to have semi-automated labelling, and more…
Here’s the video on Control and the other use.

Conclusion
If you’ve read that far, congratulations! You’re much closer to understanding self-driving cars now that you were 10 minutes ago!
As you can see, Deep Learning is well in place in many areas of autonomous driving… and it’s emerging in all the others.
BONUS : So if you want to become a Deep Learning Master, I have created a Deep Learning MindMap that will explain to you every use of Deep Learning in Self-Driving Cars.
📩 To download the mindmap , I invite you to join the daily emails and receive my cutting-edge content on Self-Driving Cars and Deep Learning! Here