How to stop recording 100% of what self-driving cars sees (Introduction to Event Driven Automotive Data Processing)
Have you ever heard the story of the iPod? It started in January 2001, right after Apple announced a loss of $195 million, and had missed the shift to digital music. The company was lost, and had one last chance of survival: building an MP3 player to catchup with the competitors.
If you are old enough to remember the MP3 players back then, the were confusing to use, overloaded with buttons and menus, and made the experience painful for customers. Apple was looking for a solution for months, but had no clue how to make it better.
Until one day, when Apple's Head of Marketing Phil Schiller suggested using a scroll wheel. Wheels already existed in mouses and dial phones, but had never been never used in music players. With this, he suggested that the menus should scroll faster the longer the wheel is turned, a stroke of genius that would distinguish the iPod from the agony of using competing player.
The rest is history: Apple developed the iPod in the greatest secrecy, launched it, and changed the world with "1000 songs in your pocket".
What made it so successful? It's not that it looked good, or had buttons, or could store more songs. No, the genius was in the smarter experience scroll wheel.
If you're in the autonomous vehicles market, we probably witnessed a similar pattern: companies have been collecting more and more data endlessly, building data centers, simulators, hiring people to analyze the data generated, and so on... Until some companies came up with smarter ways, not involving just "collecting more data", but rethinking the experience to focus on events instead.
In this article, I would like to tell you about the way automotive data processing works nowadays, and how the AI revolution is going to reshape it.
We are going to learn about 3 ideas:
- The first part is going to focus on the Manual Era (where we collect and process it all) and the Cloud Era (where we use DataLakes)
- The second part will be a case-study provided by an autonomous tech startup, revealing the 10 biggest problems of the Cloud Era.
- The last part will show you the Edge Intelligence Era & the Autonomous Era, which, as you'll see, if an incredibly more intelligent way to do
Let's begin with point #1.
1. Data Management: How self-driving car companies collect and process data in the Cloud Era
One of the things we heard the most this past decade was that Data is king. And for a long time, collecting as much data as you can in order to train heavy machine learning models has been the only way to do. Let's talk about data collection, and then processing.
How do autonomous vehicles collect data?
We know that when a self-driving car drives, all the data (sensors, images, messages, hardware status, algorithm decision, ...) is being recorded.
Should we give an intro line explaining how?
The process is simple, and looks like this:
- You plug your sensors to your system (for example, Robotic OS/ROS)
- You press record
I'm sure somebody out there worked hard to find a more complex process, but if you're using a tool like ROS, recording data is as simple as using one command line. In the video below, you can see me recording LiDAR point clouds, camera images, GPS positions, algorithms outputs, and mostly all the messages passed through the self-driving car while we drive...
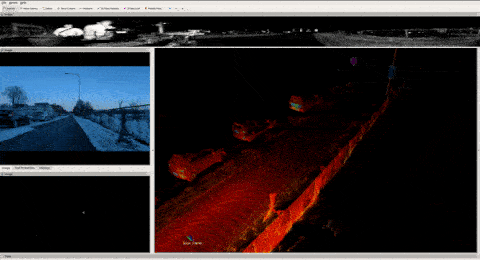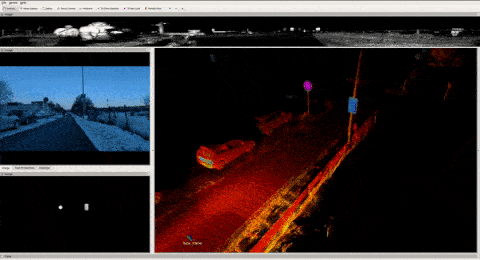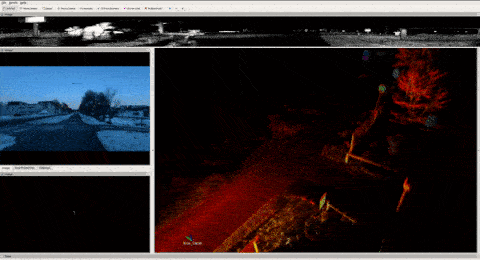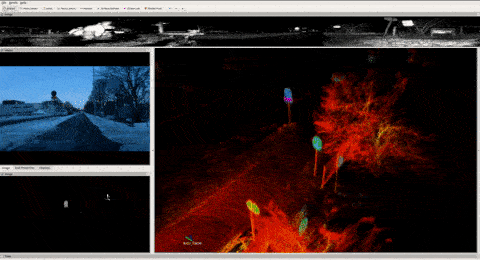
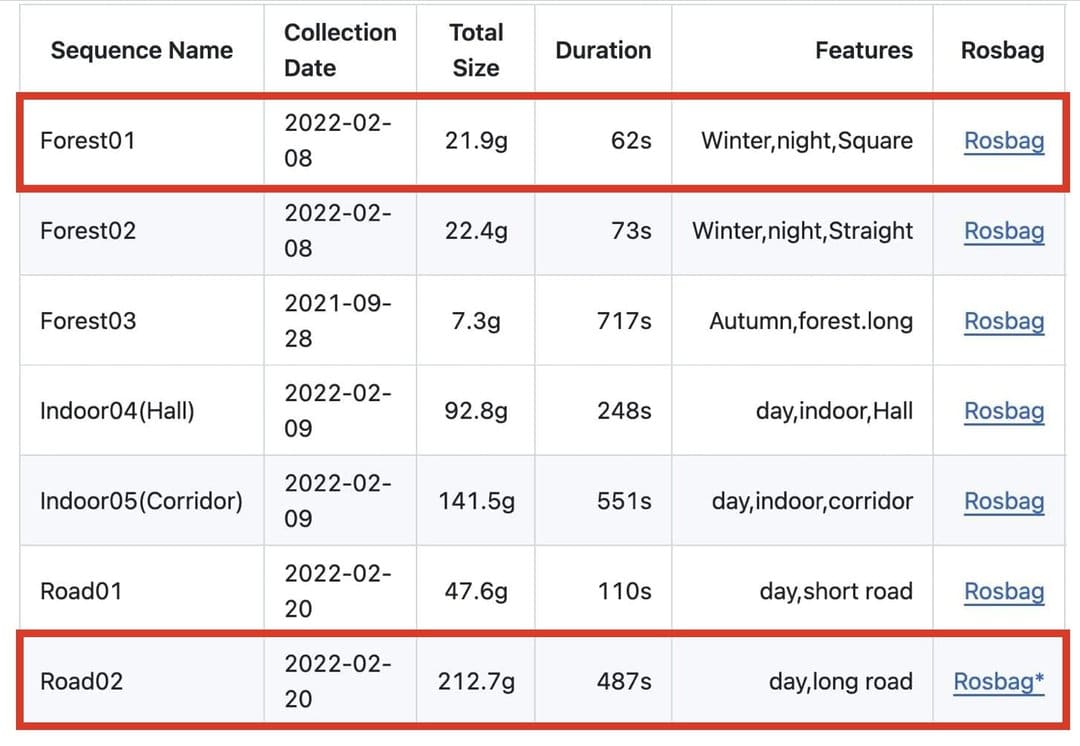
When I'm done recording, the output is a file in the .bag extension (for ROS 1) that can vary from a few Gb to Terrabytes of data. Let me show you an example below from the TIERS dataset. Notice the duration and sizes of the recordings below — the last one is just 8 minutes long, and yet weights 200Gb. This is 2.4Gb/minute!
The bag is the first element. Then comes what we do with it.
The Manual Era: How do we process and analyze data?
The first "era" I'd like to tell you about is the 1.0 era. Back when I worked on autonomous shuttles, each of our fully autonomous vehicles was driving and collecting data to SSD drives. When the day was over, we had hundreds of Gb to process. So we started coming up with file naming conventions, involving the date, event, and so on...
Then, when back to the office, we could replay our algorithms on it, train our models on the data, and so on... Below is an example of a drivable area segmentation algorithm I've been training on the data collected:

This was fine for a small startup of 8 people, and it's probably still okay for small companies that don't need extensive processing, but most autonomous vehicle companies have turned to the cloud...
The Cloud Era: How Advanced Driver Assistance Systems (ADAS) & most of the Automotive Industry is using Data Lakes
If you record data every day, and each recording is hours long, you're never going to find the events you need. This is why I'm showing you a more sophisticated, let's say '1.5' version, which makes data collection part of a pipeline.
It looks like this:
- You record the data
- You upload it to AWS/Azure
- The R&D team then processes it weeks later, replaying all the events, searching for 10% possibly interesting scenarios, or events, and so on...
If you'd like to see real-world concepts, you can see AWS and Azure Data Lakes:
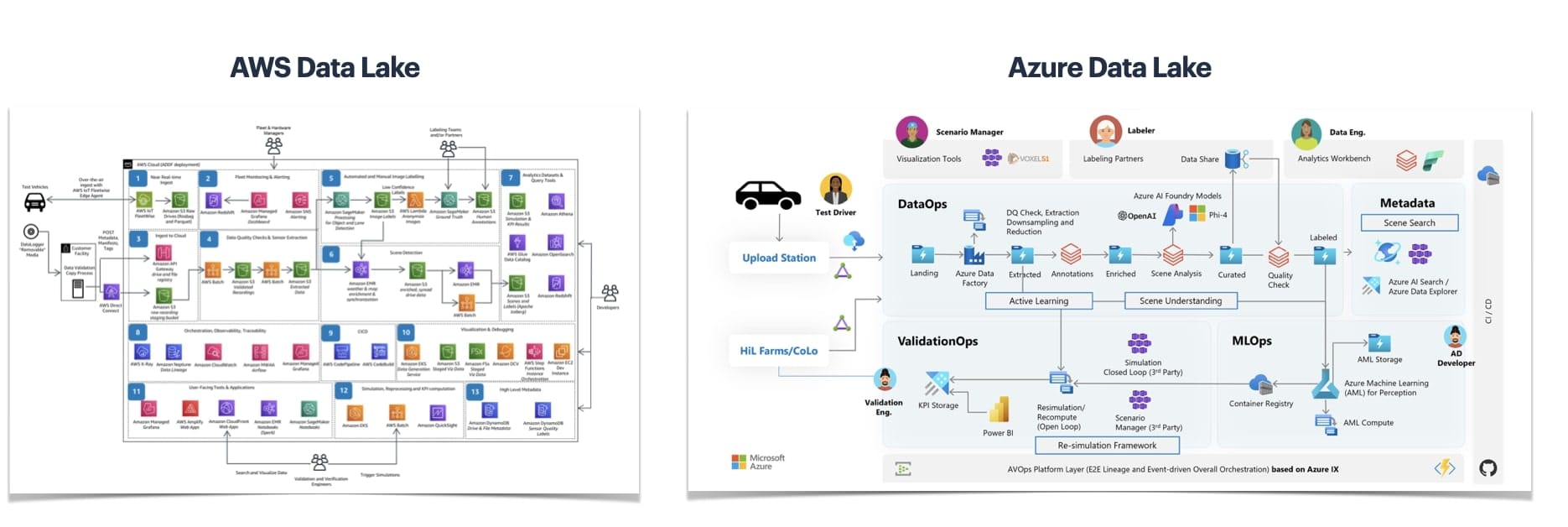
A lot of companies in the self-driving car market use these "data lakes". Let's look at the Azure Data Lake in a simplified view:
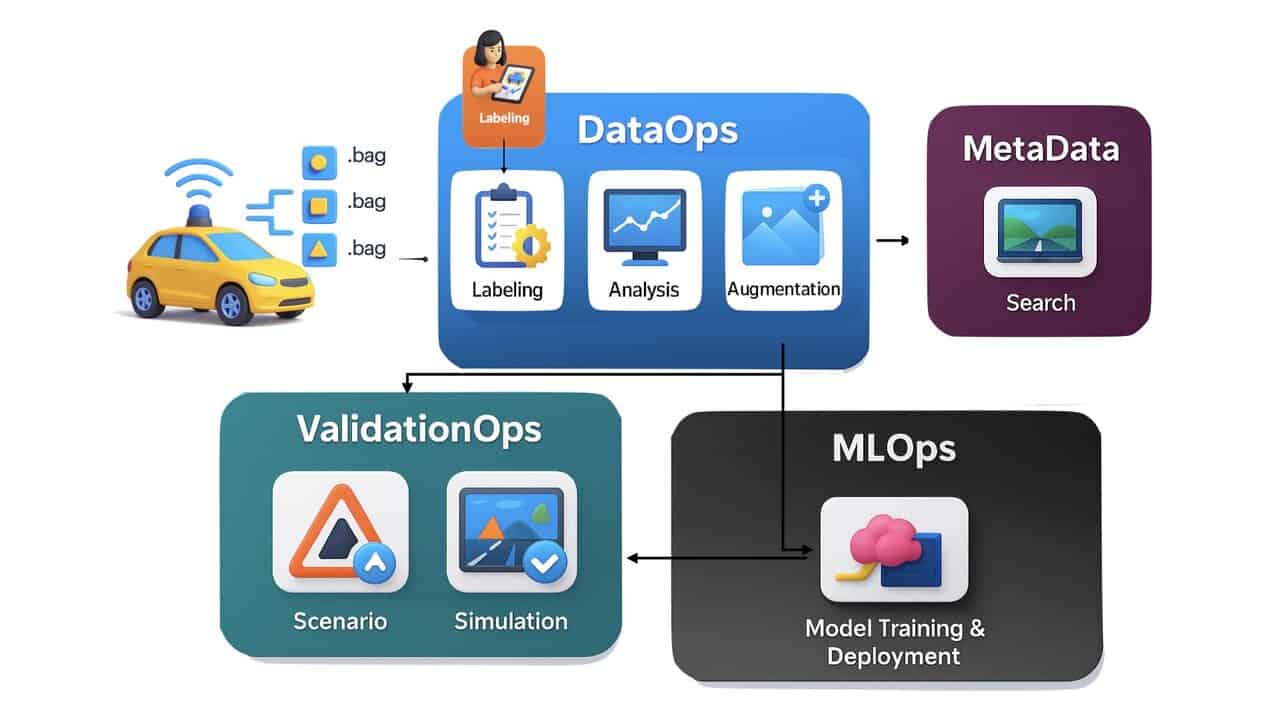
ADAS & fully autonomous cars use it. After recording, the 4 key blocks are:
- DataOps: Where we analyze data, clean it, label it, augment it, tag it, and so on... Notice the interaction with external labellers; that idea is called "human-in-the-loop".
- MLOps: The machine learning algorithms, training, testing, and so on...
- ValidationOps: The validation part, involving visualization, scenario, and simulation.
- MetaData: After the DataOps tagged the data, we can search for it.
You can see how it's placing data at an element in the chain.
So what are the problems of this? Before telling you about the 2.0 Autonomous Era, let's try to see a case study with real ADAS or artificial intelligence companies using it...
2. [Case Study] ADAS Actors reveals their 10 biggest problems with Data-Driven Approaches
In this section, before talking about the '2.0' approach, I would like to tell you about the core problems companies who process large volumes of data reported.
Before writing this article, I got the opportunity to talk to Heex Technologies, a french startup specialized in Event Based Data Management... and I asked them "Which problem do you solve?". To answer, they shared a 20 page PDF listing all the problems their biggest Advanced Driver Assistance Systems (ADAS), autonomous driving, or robotic clients from the automotive industry.
In the PDF, I spotted a lot of interesting problems. Let me share the main ones with you:
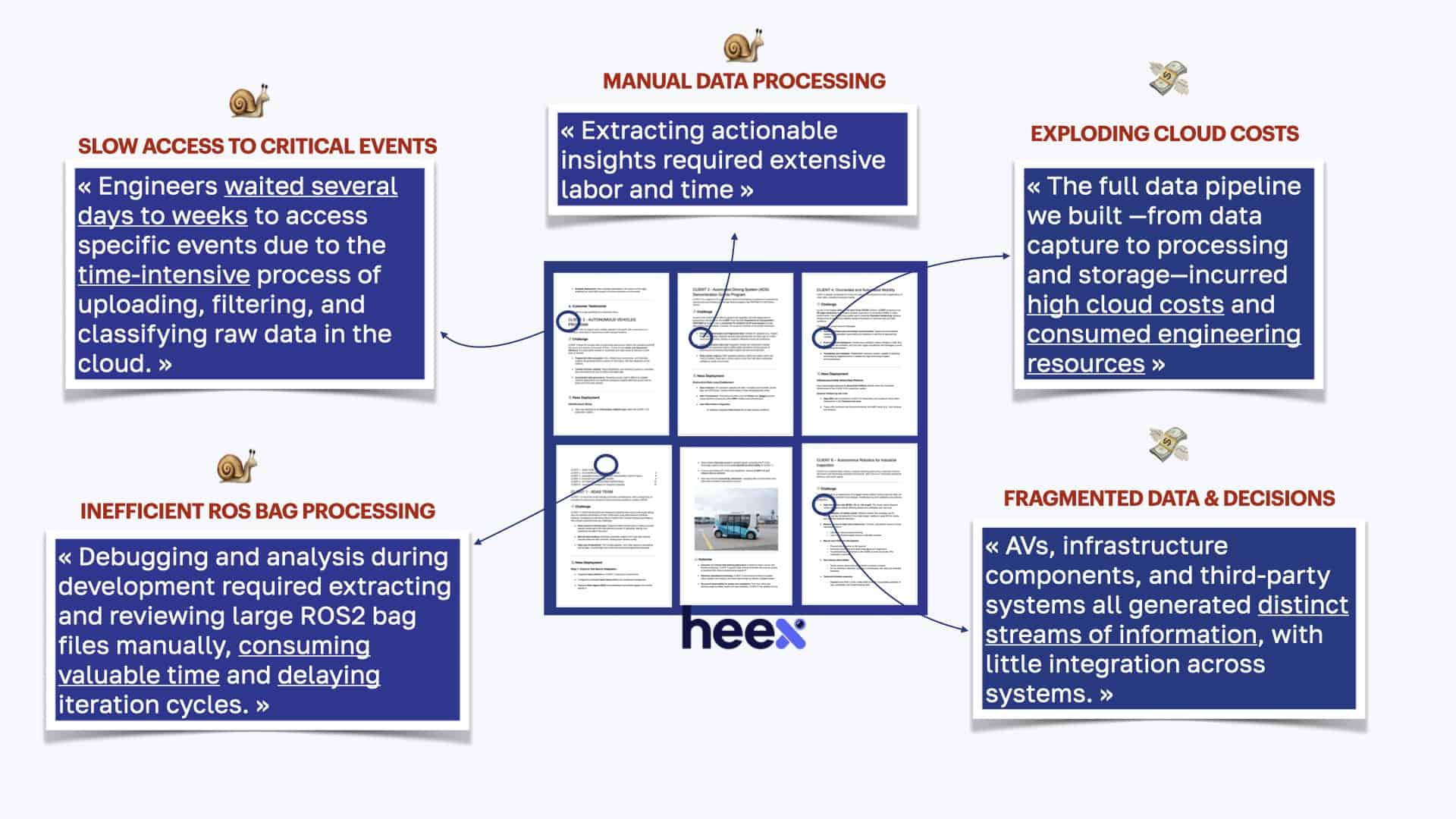
If I were to list down the 10 main problems, you'd see: Slow access to critical events, Manual data processing, Exploding Cloud costs, Fragmented data, Delayed visualization (no real-time), Manual Extraction of scenarios, Useless streaming data, Physical SSD Extraction, Blind Debugging, and Inefficient ROS Bag Processing.
Notice all these terms I underlined? These are the problems of today's data management systems.
Let's take some examples...
- If you collect the data on Day 1, and process it on Day 3, you have slow/delayed access to critical events; like a missed pedestrian. So you're driving, notice something wrong, but you have to wait until 2 days later to even look for the data, and start searching for that event you noticed...
- Similarly, can you see how the 'fragmented' data processing is a problem? Especially when you are with a team. Engineer A grabs bag A, and makes decisions based on it... Engineer B grabs bag B and makes a different decision based on it... The entire decision cycle happens in silos.
- The Physical SSD extraction is a problem too. In May 2025, I was at the Stuttgart ADAS & AV Expo, and I met a company who invented a "swap" disk system... All of this is great, but that's still the same problem of storing, copy/pasting data, etc... to a system.

In each of these problems, I noticed a time and money waste.
For example, the client reporting: "Engineers waited several days to weeks to access specific events due to the time-intensive process of uploading, filtering, and classifying raw data in the cloud." is clearly facing a time problem, reviewing large amount of data... The other client who mentioned: "The full data pipeline we built —from data capture to processing and storage—incurred high cloud costs and consumed engineering resources" faces a money problem...
In this same report shared by Heex, all the companies reported improvement in their pipeline. Whether it was better decision making, more time freed, or money saved. This is why the next part is so important, so let's now focus on it: Event Driven Data Processing for autonomous cars.
3. Event Driven Data Management for autonomous cars
Back when I started learning autonomous driving algorithms, I listened to an interview from Sebastian Thrun, acknowledged as te godfather of self-driving cars, who at some point, said something that marked me: [paraphrased]: "With a team of 2/3, you can build a self-driving car that drives 90% of scenarios in a weekend. Then to get to 95%, it takes a few weeks, and to complete these last 5%, it takes years."
This idea is called the "long-tail" problem.
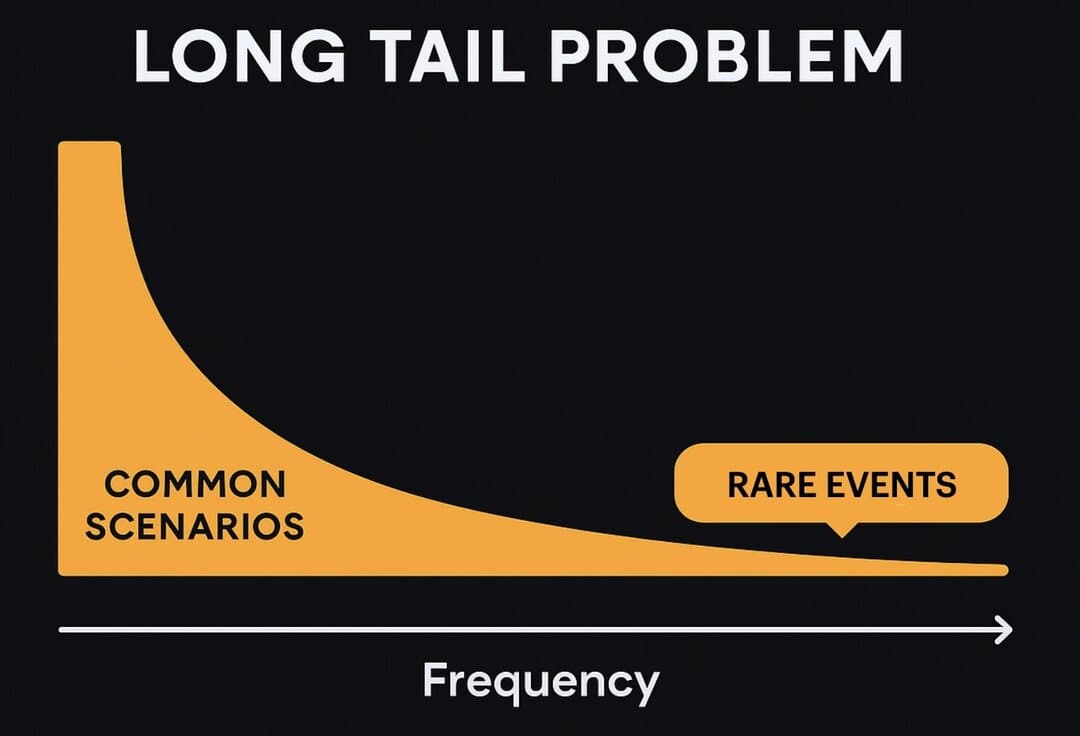
When looking at traffic accidents involving autonomous vehicles, you often see rare events or edge cases at the root cause. The person wearing a stop sign t-shirt, the truck with a donkey on the trailer, the traffic sign burned by parisian riots, all of these unusual scenes totally different from empty highways cars are used to.
Some companies solve it with data generation, others with simulation, or with End-To-End Learning. Yet, the root of all evils here is data, and thus, this is what we have to change.
A decade ago, the term "data" became king, and everybody became a Data Scientist, Data Engineer, Data Ops, Data Something. It was the case until recently when the data revolution passed, and breakthrough innovations happened not thanks to more data, but thanks to smarter training systems (like self-supervised learning), or more powerful architectures (like transformers). "More data" was ultimately not the solution, and thus, we have to switch our thinking...
The Edge Intelligence Era: From Data Management to Event Management
After companies have recorded a few laps of the neighborhood they drive in, recording more of this same scene doesn't make sense. Companies record more and more, just to spot the 1% of long-tail events. What if we worked on these events only, from the beginning?
It can be done, by setting up a "triggers" in your system, that will act as a filter and only capture the scene when interesting events happen, such as:
- Objects Missed: If one camera misses an object that another sensor sees
- Near Pedestrian Collision: If pedestrians are within 2 meters of our car, and we drive over 30km/h
- Human Intervention: If a human driver manually took over
- Shakes: If the camera physically moved due to a bumper or small shock
- Ego Collision: If a collision with the ego vehicle happened
- and so on...
All of these are valid events we'd like to record. The rest? When it's all smooth? Well, we already have millions of it.
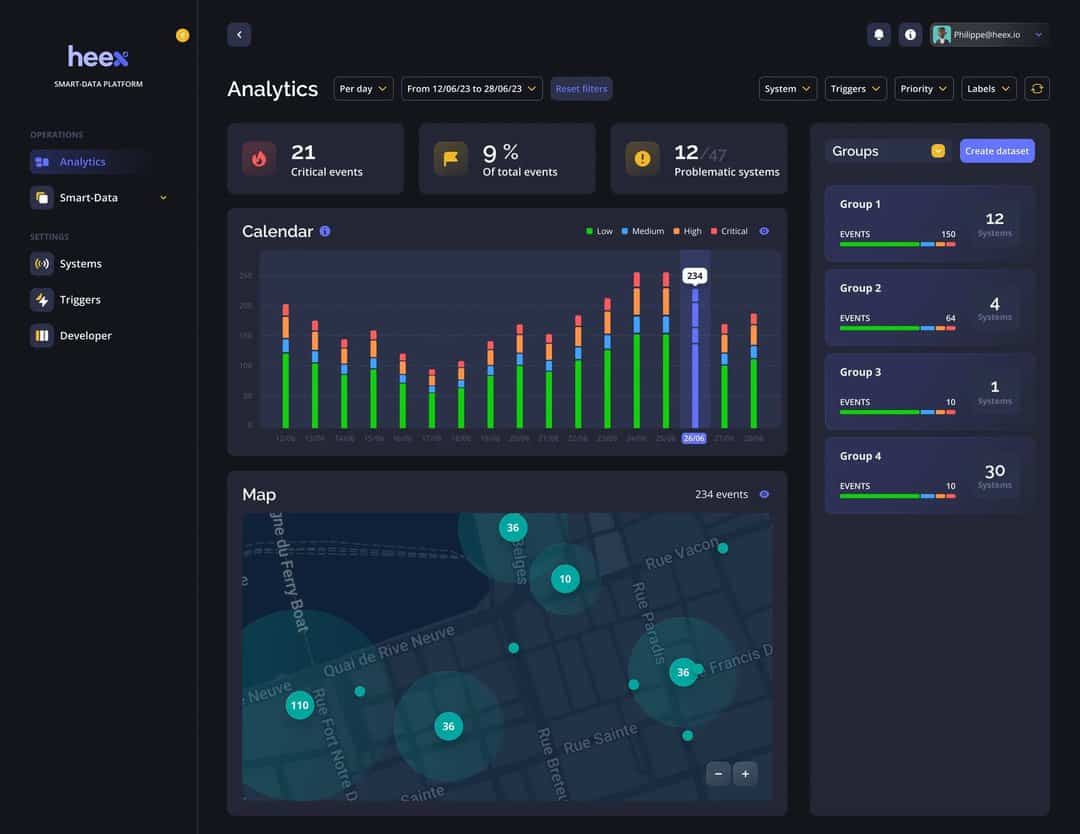
An example with Heex Technologies, and their platform allowing to set triggers:
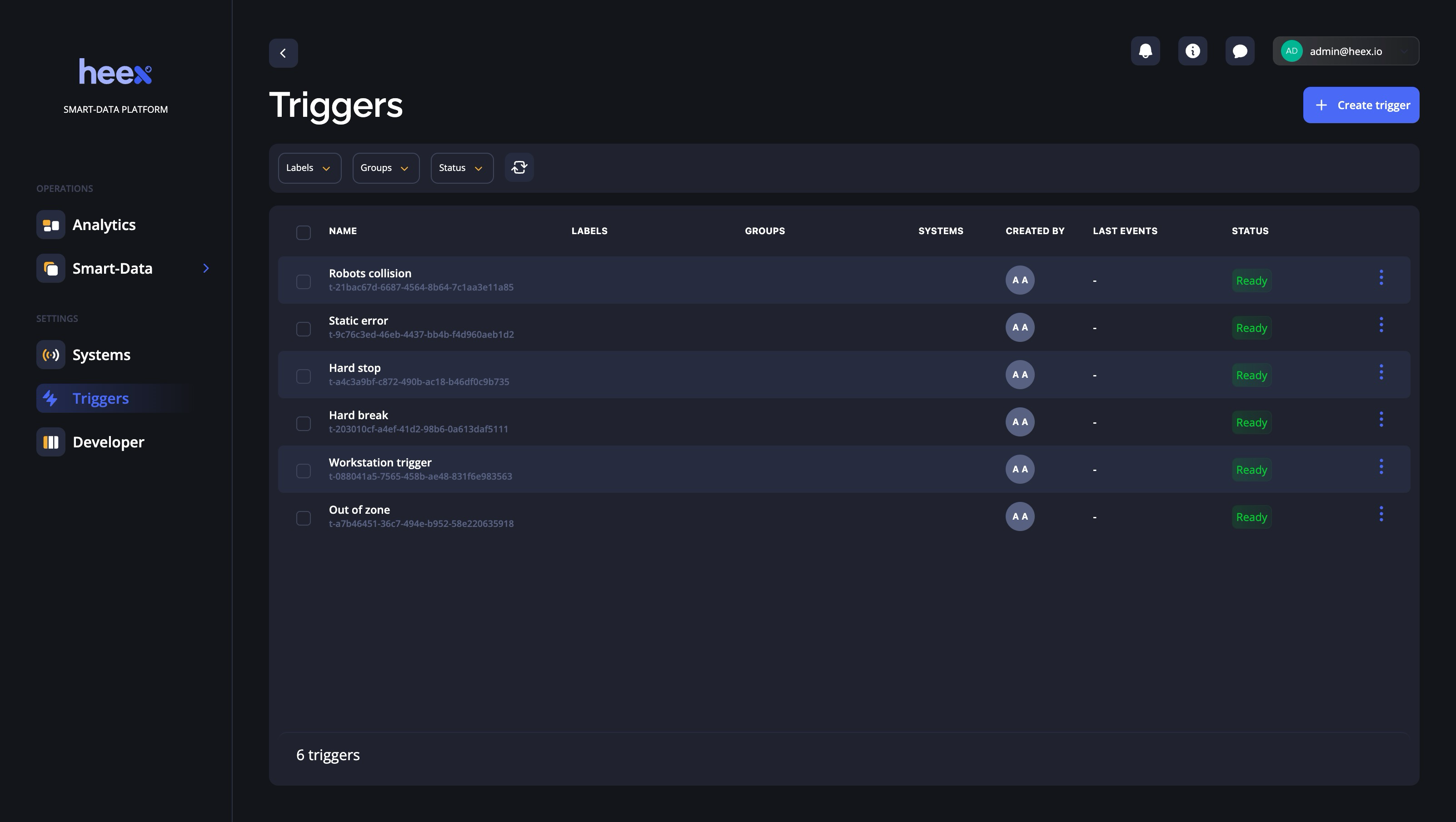
If I were to show you the 2.0 process, it'd look like this:
- You have the same car with LiDARs generating the same 10Gb/h data
- Rather than recording all data available, you define triggers.
- You intelligently record the events, like the near pedestrian collision, and not all the data
- You get instant notifications, labels, and can do real-time decision making
Seems smarter, isn't it?
Now that you have this in mind, I'd like to show you the last era...
The Autonomous Era: AI does it for you
The next step is to create algorithms to do it automatically for us. For example, Tesla patented a concept called trigger classifiers. The idea is to train their HydraNet backbone to classify whether the general scene it's learning from contains unusual events or not. If it does, let's say above a certain confidence score, then the machine learning models will trigger a warning.
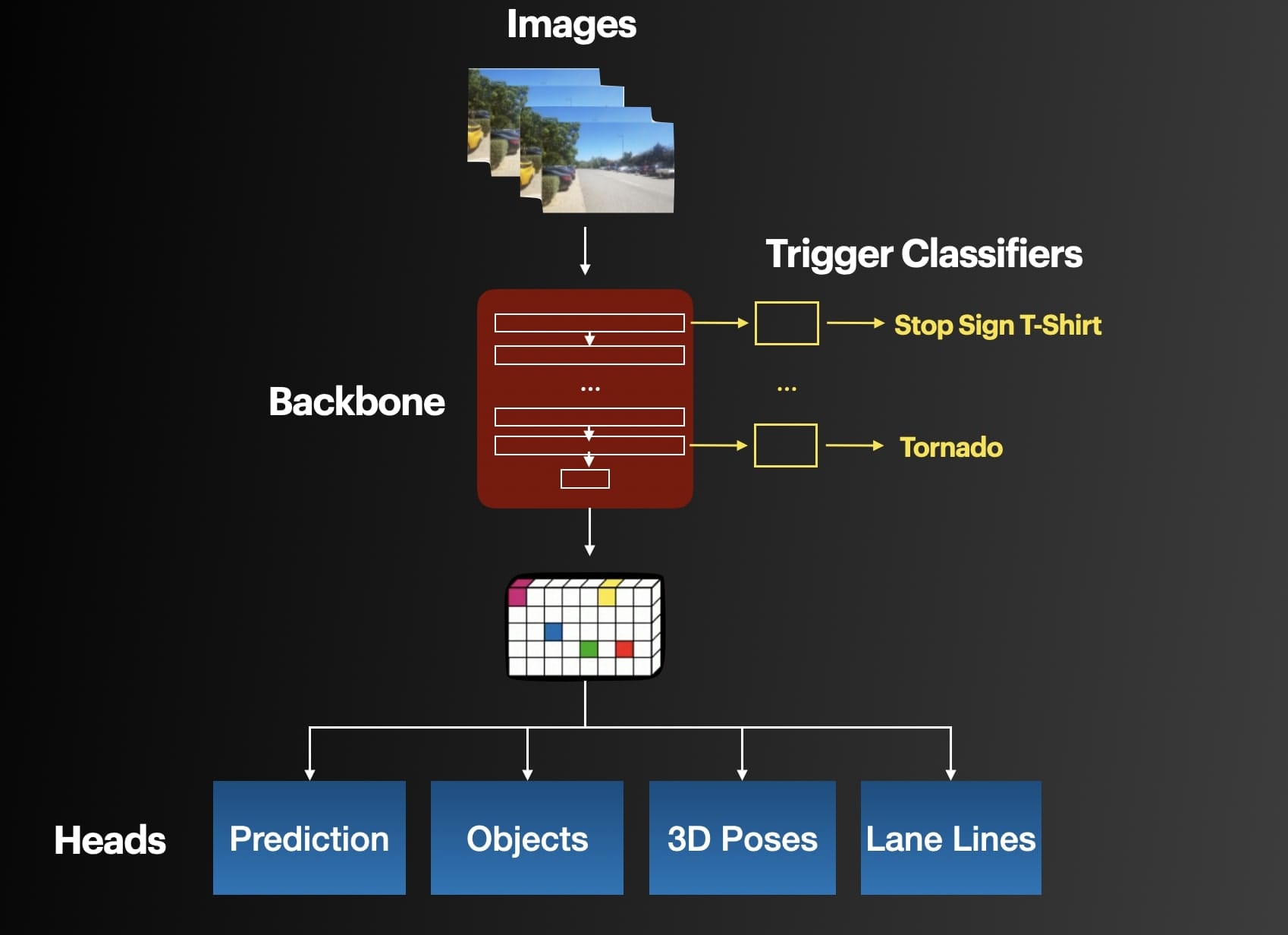
Whether you're working on spreadsheets or building autonomous vehicle technology, automating manual items like labelling or searching for data makes sense. In this case, just like the Edge Intelligence Era, you can see the events being captured live while driving, and not after.
The 2.0 Vision
This is going with the "2.0" vision of self-driving cars that companies now define. A vision driven by Deep Learning first, where data matters, but where more data isn't the solution. In the 2.0 vision, quality is better then quantity; contextual intelligence is needed, learning should be real-time, and training should be done on relevant data.
If the 1.0 vision involved heavy test vehicles, modular architectures; the 2.0 vision is about AI & efficiency.
Now, let's see an example of a company specialized in this...
Example: How Heex Technologies turns Data into Event Management

One of the companies that captured this vision the best is Heex Technologies. They built a SaaS platform that implements exactly these ideas of "triggers" — and their motto is that rater than focusing on the data, they focus on events. As I already showed you the triggers, we could see it in action:
Let's look at their pipeline, which you'll notice also works backwards — once the bag is generated:
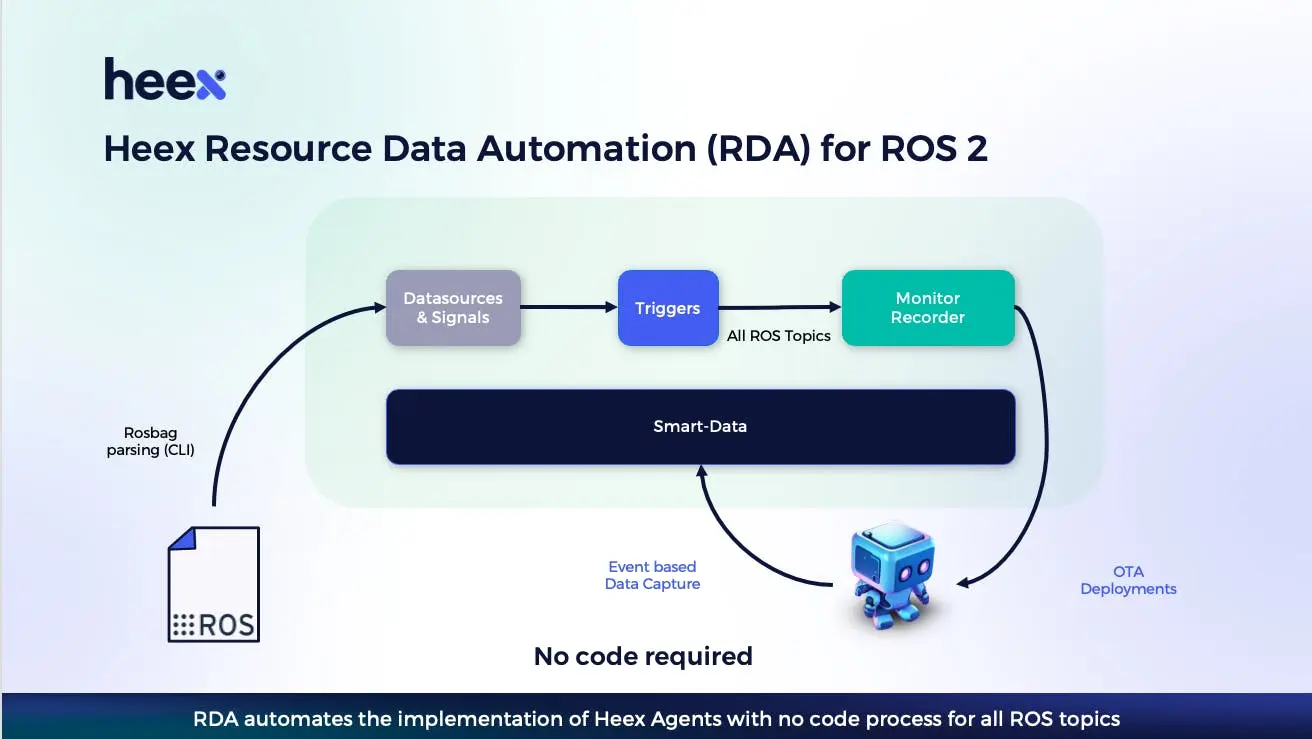
From a heavy bag, we get a smart bag. The data is definitely smarter when automatically annotated, categorized, and when relevant events are flagged. We can then re-inject this data into the training pipeline, without having to worry about the rest of the dataset.
As an entrepreneur myself, I can only admire the focus on one specific and painful problem like this one. When you can anticipate customer needs, and enable automakers and automotive engineers move away from a complex process to focus on their core job (self driving technology)... you win!
Alright, let's do a summary and see what to do next:
Summary & Next Steps
- Collecting data is essential to train AI models and develop self-driving vehicles. Yet, "more data" is not the solution to create breakthrough, and solve the "long tail" problem, which cause a significant challenge.
- The first Era of data processing is the Manual Era, in which we record and process everything manually. (1.0)
- The second era (1.5) is the cloud version, in which you work with data lakes and build a real "chain" that contains DataOps, MLOps, ValidationOps, and so on...
- The third era moves to the 2.0. It's where we stop obsessing on the data, and focus on events. We can use triggers and platforms like Heex Technologies to do it.
- The fourth era is the AI Era. (2+) This is where we have AI automatically find events, and train itself continuously on these.
Which solution is right for you? In reality, they can all work. A small startup can work manually, until they find their hard problem to solve, and they have a budget to invest in data lakes... Companies can work with data lakes, but for bigger fleets, it'd make much more sense to think in terms of events instead.
Next Steps
If you realise you have these problems of recording everything, having your data staying a bit « dumb », and would like to know exactly how to stop recording everything by this afternoon (without losing the important information)...
... Then I’d recommend to check out Heex free discovery quiz, which will reveal tell you exactly what you’re doing wrong today, and (based on your answers) show you what to do this afternoon to save hours of recording, data processing, etc...
It’s free, and you can get access below:

You can also take a look at Heex' product here: https://www.heex.io/en-gb/smarter-data-faster-decisions