

How Google’s Self-Driving Cars Work
The autonomous tech world has 2 giants: Tesla & Waymo.
In my last article, I broke down Tesla’s computer vision system.
👉 You can find that post here .
Today, we’ll take a look at what Waymo, Google’s self-driving car division, is doing under the hood.
Waymo has driven more than 20 million miles on public roads in over 25 cities. They also drove tens of billions of miles in simulations (as we’ll see later in the article). Additionally, Waymo is operating a taxi service in the United States, transporting passengers—for real—without a driver.
Given their growing presence in the real world, I want to dive deep into Waymo’s technology so you can understand what’s actually behind this giant.
As with every self-driving vehicle, Waymo implements their tech using our 4 main steps: perception, localization, planning, and control.
In this post, the only thing I’ll not talk about is control. For Waymo, prediction (which is part of planning), is another core pillar, and it will be treated independently here.
Let’s start with perception.
Perception
The core component of most robotics systems is the perception task. In Waymo’s case, perception includes estimations of obstacles and the localization of the self-driving vehicle.
Sensors & Tasks
Waymo’s perception system is using a combination of cameras, LiDARs , and RADARs. Since most of Waymo’s work is done using 4 LiDARs, you can essentially consider it the anti-Tesla system.
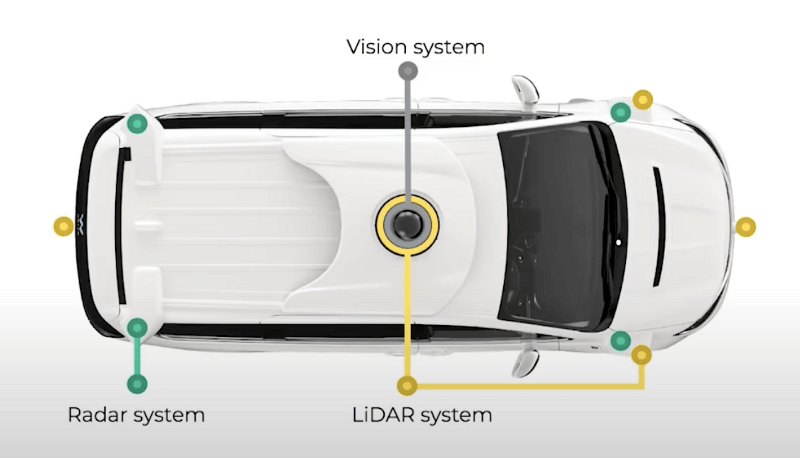
Here is a view of the complicated task of autonomous driving for Waymo—just to give you a sense of all the things their computer vision system needs to perceive.
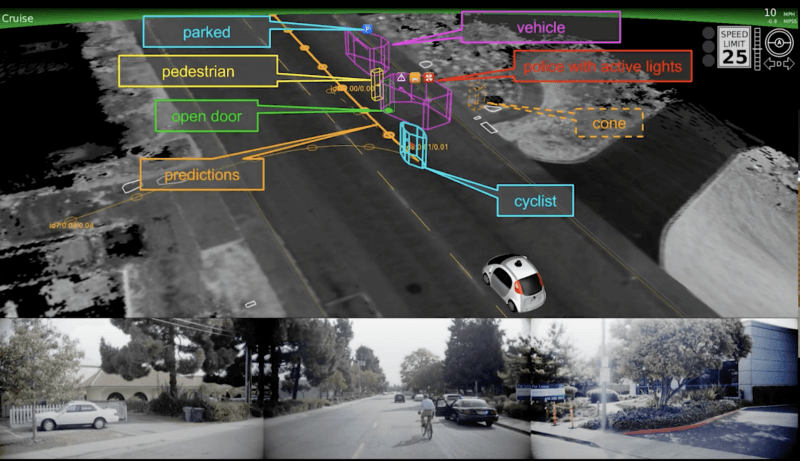
As you can see, the level of information we have for an obstacle is quite high:
Cars are classified into “regular”, “police”, “ambulance'', “fire truck”, and “school bus”.
If this is a specific car, the system can watch for sirens and lights and behave based on this
Each detected obstacle has a state: “moving”, “parked”, etc
As you can see, the perception system considers “state” and will feed this to their prediction system.
This perception system can quickly run into some especially tricky situations, however. Here’s an example:

The above reflection problem is far from being the only one—people could show up as disguised, lie on the roof of a truck, walk carrying a STOP sign 😳—we could probably imagine quite a few more edge cases, but these should give you a sense of the problems the system can run into.
Waymo’s Notes— However, a lot of the cited problems have been solved in the last few years.
The reflection problem can be solved thanks to LiDAR. Reflections won’t appear in a LiDAR; only point clouds showing the shape of the true obstacle (here, a bus). Learn more about LiDAR on my Point Clouds Fast Course!
The “person carrying a STOP sign” problem has been solved thanks to mapping. Detecting a STOP sign is one step; matching this information with the Map and prior knowledge is the second. Every time Waymo detects a sign, they also ask the question “Does our map contain a STOP sign here? If not, are there roadworks? If not, there is no reason to stop!” —
Architectures
When I recently discussed Tesla’s computer vision architecture, I explored an architecture called HydraNet. It’s an architecture designed to run multiple neural networks at the same time. The word “Hydra” implies a system with several heads.
Waymo doesn’t talk about HydraNets, but they do have some specific things to say about their vision system.
The first thing that might surprise you is that Waymo’s architecture isn’t fixed; it’s estimated.
This is a neural architecture search (NAS) cell.

It’s a building block for neural networks that’s repeated in a larger neural network—similar to ResNets. This idea has been taken and adapted into something called AutoML. The idea of AutoML is that the neural network architecture must be estimated by an algorithm.
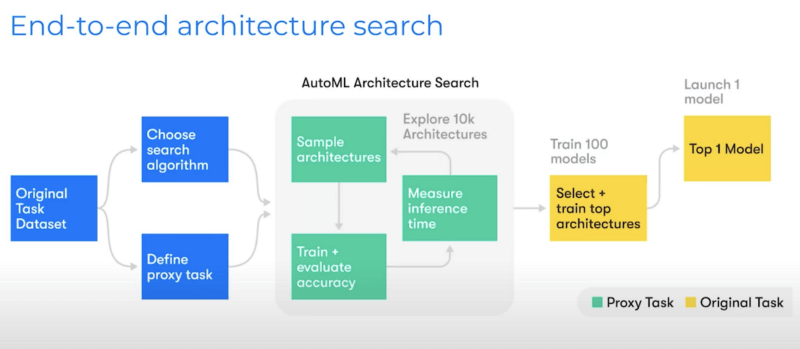
The architectures are built using NAS cells, and the best combination wins.
10,000 architectures are tested, 100 models are pre-selected, and then 1 final winner is selected. The criteria for winning are accuracy and inference cost.
Datasets & Models
You probably know Google is using a process called active learning.
The idea of active learning is as follows:
- For every piece of unlabeled data, we send it to an AI.
- If the AI is very certain about its prediction, it receives an automated label.
- If it’s less certain, the AI sends the data to a human labeler.
This way, the human labeler only labels hard data, and the rest is automated.
You can learn more about active learning in this short article.
This process is used by Waymo to train their models, leveraging TPUs (Tensor Processing Units) and TensorFlow, Google’s deep learning framework.
Similar to Tesla, this is a closed-loop.
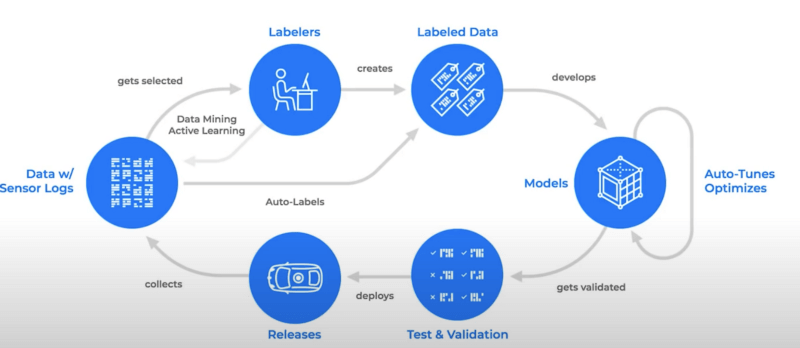
I believe the picture speaks for itself; start with “Releases” at the bottom and move to the left.
- Once a release is done, data collection begins.
- Some data gets selected and is annotated by neural networks and human labelers.
- The labeled dataset is then sent into the AutoML architecture search, which then estimates the best model .
- The best model is validated, tested, and deployed to a new release.
And we start over…
The goal of these machine learning models for perception is to accurately estimate a 3D world.
Localization
The idea of localization is to position the vehicle in the world within 1–3 cm accuracy. Some companies work using GPS, others add cameras and LiDAR information, but…
Waymo is using Mapping, LiDARS, and GPS to localize the vehicle. Google also leverages the experience acquired with Google Maps.
For years, Google Maps Team has worked on precise mapping using LiDARs, cameras, and GPS. These are the exact sensors used in autonomous vehicles.
Waymo‘s Notes — Although neither Waze not Google Maps are involved in Waymo and their localization module, the experience accumulated on mapping seems highly beneficial.
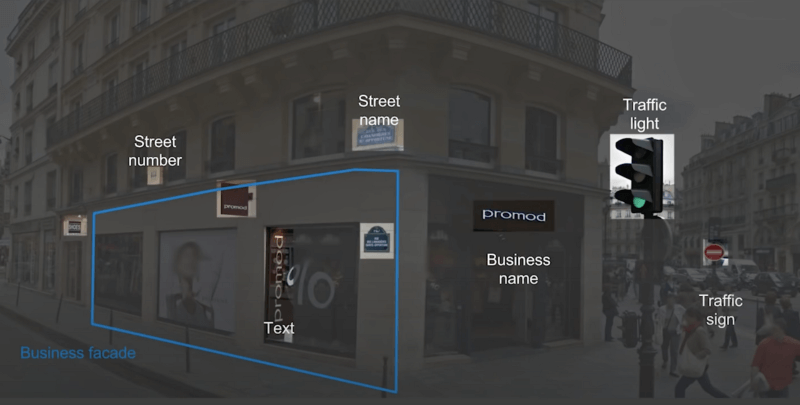
Google has quite literally almost mapped the whole world. If they detect that you’re seeing a street address number 2 from a relative position, they can know exactly where you are. That’s what they’ve been working on for the last two decades.

Waymo’s localization module is made with mapping, cameras, GPS, and algorithms to position the vehicle accurately in the world. Waymo also uses a lot of redundancy in their module to be more robust and reliable.
Prediction
Behavioral Prediction
The most important feature of Waymo’s self-driving car is behavioral prediction. Google cannot leverage the same fleet power, as Tesla does. Tesla put hundreds of thousands of cars in the hands of their customers and let them collect data for them. Waymo wasn’t able to do that; they however have their own fleet of vehicles that could grow a lot in the recent years.
In self-driving cars, what you want is ultimately to learn about human behaviors and anticipate them. That’s called behavioral prediction.
These behavioral predictions are made using recurrent neural networks: they use past information to predict future behaviors. Thanks to that, they can know exactly what to do, and they can measure their confidence in their predictions.
Behavioral prediction is similar to the following:
If the vehicle sees a pedestrian watching you, the risk of accidents is low.
If it sees a pedestrian running without watching, the risk gets higher.
Waymo’s system knows this. How? They are inputting expert bias in their models. Their prediction system is a hybrid: it’s a combination of machine learning and human knowledge of the world. The human knowledge also includes traffic laws and things that can be impossible (i.e. a human can’t walk or run at 50 km/h).
Simulations
Waymo is driving a lot, but they are also simulating a lot. Waymo built a simulator that takes as input real-world data and outputs new scenarios.
Take a situation that happened in real life. Now, modify it using simulators. Imagine if we had a car overtaking the human driver—now imagine if this car didn’t overtake the driver.
This is similar to the movie Next, where Nicolas Cage has the power to visualize every possible scenario and choose the one where he survives.

Waymo can look forward in time, they can look backward in time, and they can simulate behaviors. They can build complete fiction and see how their algorithm behaves. There is a real power to using simulators. In fact, Waymo runs, on average, 25,000 virtual cars 24/7, and they drive 10,000,000 miles per day in these simulations.
Have a look at the following image. On the right, you can see a yellow line that splits in two.

This is not Dominic Toretto and Brian O’Connor saying goodbye. These two lines are projections of what a vehicle might do. The more information we have on this vehicle, the more accurate and confident our prediction gets. Until one remains…
To simulate more scenarios, Waymo is using DeepMind and deep reinforcement learning to create agents and driving policies.
In reinforcement learning, a policy is a behavior. Waymo can simulate an angry driver trying to cut dangerously in front of someone, or a careless scooter driver. Every time, they look at how their algorithm behaves and correct.
Once they have accurate and trained predictions on drivers, they can generate trajectories to take. This is also called Decision-Making & Trajectory Generation. Their driving model is called ChauffeurNet.
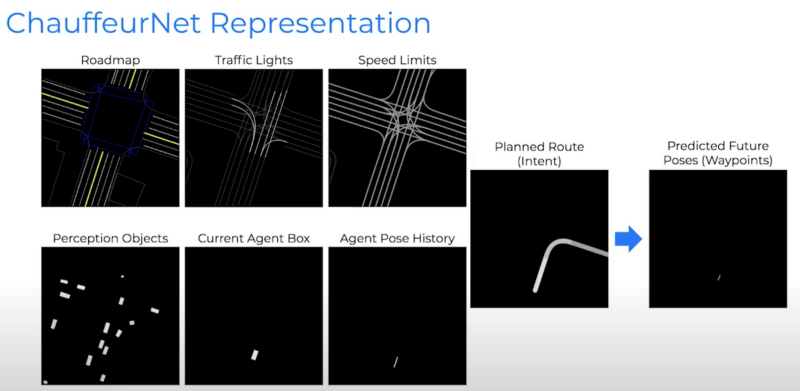
Waypoints are just a series of (x,y,z) points that create a trajectory.
The goal of the planning module is to generate the trajectory (set of waypoints) that has the lowest errors in terms of safety, speed, and feasibility.
Here’s a look at Waymo’s complete planning module:
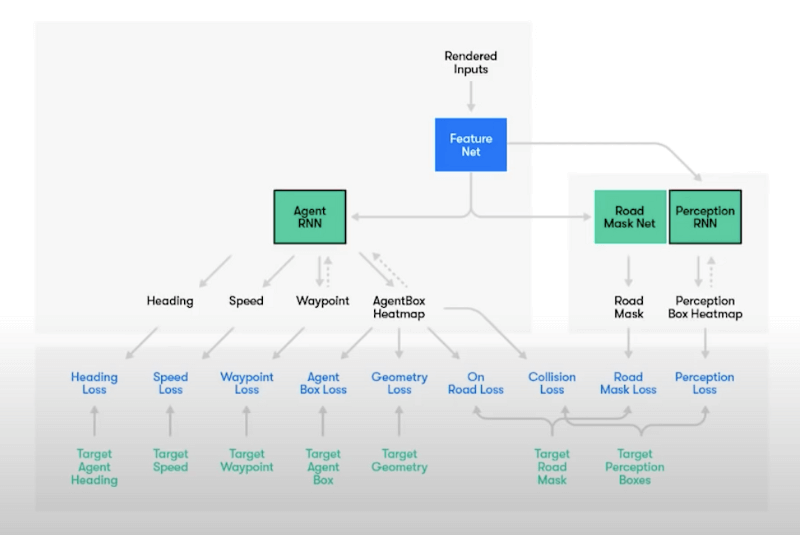
This might look pretty complicated (it kind of is), but don’t worry, that’s why I wrote this article!
Let’s start at the top and consider “Feature Net” as the output of perception, localization, and predictions.
On the left, you can see an “Agent RNN”. This is actually a network that generates trajectories for the ego vehicle. These trajectories will take into account Heading (feasibility), Speed (traffic laws), Waypoint (length), and Agent (feasibility, geometry, …). 👉 The goal of the Agent RNN is to simulate a feasible, realistic trajectory.
Then on the right, you can see Road Mask Net. 👉 This is a network that gets a high penalty if it generates a trajectory that’s not on the road. It does indeed make sense that we don’t want to drive on the sidewalk—this is how Waymo ensures this doesn’t happen.
Finally, on the far right, you can see the Perception RNN. 👉 This is a network that will penalize collisions and interactions with other vehicles. For instance, if you are 1 meter away from a vehicle, the loss is higher than if you are 1.5 meters away from it.
In summary, the network generates a trajectory that’s feasible, stays on the road, and avoids collisions.
Finally, the trajectory also considers repellers and attractors. We want to stay at the center of the lane, and so we want to avoid barricades and follow the center.
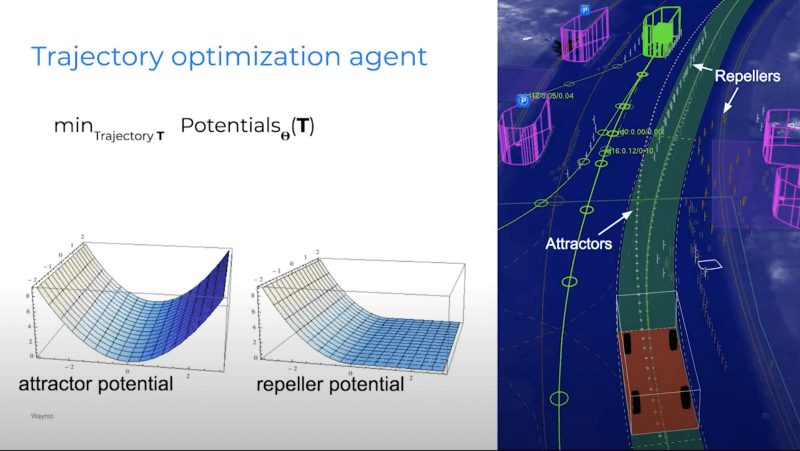
The process of generating an appropriate trajectory also uses a technique called inverse reinforcement learning.
In inverse reinforcement learning, we try to look at the real human trajectory (the ground truth), and determine what made this trajectory a good one. This improves the generated trajectory and makes it more realistic.
We’ve covered a lot, and there’s much more we could discuss. But let’s end this here, as we’ve covered many of the basics.
Summary
I hope you don’t feel overwhelmed—I’ll try to summarize here:
Perception is about finding obstacles, traffic lights, and roads. Waymo uses active learning to collect data, and AutoML to generate architectures and select the more efficient ones (accuracy and inference time).
Localization is mainly perception with the task of finding where you are. Waymo is leveraging the knowledge of Google Maps to do so.
Prediction is using recurrent neural networks and reinforcement learning in simulators to train their agents to estimate trajectories really well.
Planning is generating trajectories based on feasibility, staying on the road, and avoiding collisions. The vehicles also learns from human labelers to generate more realistic trajectories.
Waymo’s system is the result of 11 years of research and experimentation in self-driving cars. In the autonomous tech world, their way of building cars has some enemies, as people have voiced a preference for Tesla’s system and realized that on-the-road experience is very valuable.
Whatever your opinion may be, you can’t deny the insane level of work and tech Google and Waymo have invested in their autonomous vehicle efforts.
Waymo still has a long way to go…
One of their main problems is the way they use Maps: Waymo can’t drive without a map. They can map the whole world more precisely, but this is a huge challenge for scale.
Waymo’s principal vision system being made of LiDARs is also actually a problem—LiDARs are completely blind during snow, rain, or fog.
Consequently, Waymo drives a lot in places like Phoenix, Arizona, or San Francisco, California, where the conditions are perpetually dry and sunny.
Waymo‘s Notes— Recently, Waymo started to drive in a very humid Michigan, a stormy Miami, and a rainy Washington.

If you look at Tesla, they’ve already driven their autonomous vehicles in the middle of New York City and in Paris. They already have knowledge of these places thanks to their drivers. Scaling might be much easier, and relying on LiDAR might, after all, be a problem.
If you’ve read this far, congratulations!
You did an amazing job reading all of this, and I hope you understand Waymo a bit better! Here’s an amazing 360° video of Waymo’s self-driving car in action:
Waymo is a direct competitor of Tesla in the race to Level 5 Autonomy! Who do you think has a better system? Let me know in the comments.
And if you want to go further, I have created a MindMap that will explain to you the main parts in Self-Driving Cars...
References
To understand Waymo better and to dive deeper into the concepts we covered in this post check out two MIT videos that you can find here. All screenshots and images are also coming from these sources.






