A look at Spatial Transformer Networks for Self-Driving Cars
Could you shoot a movie without doing a single cut? Well, maybe not an entire movie. Now what about a scene? A few years ago, I was in a theatre watching the opening scene of "La La Land" with my (then) girlfriend — and I had been shocked by how well crafted was that intro scene "Another Day of Sun".
This 6 minute long scene is unique because it has almost no "cut". It's an uninterrupted take, moving the camera from actor to actor, car to car, all on a highway. Now, can you imagine if movies didn't have the ability to "cut"? The making of a movie would be much harder, and this because cuts allow for perspective, zooming, changing angles, ratios, and much more...
It's the same with Deep Learning & Convolutions. When you use the standard convolutions, you have that uninterrupted flow of feature maps. But this is playing the game on hard mode. When you use "cuts", you can zoom on a specific feature map, rotate it, change perspective, etc...
In Deep Learning, this cut is achieved via an algorithm called a Spatial Transformer Network.
Since 2015, Spatial Transformer Networks (STNs) have been one of the most practical algorithm in fields like Computer Vision and Perception. The main particularity is that they allowed to apply transfomations in the Feature Space directly, rather than on input images. This made them very convenient, and easy to just "plug" on any network; from perspective transforms to point cloud processing.
In this article, we'll explore Spatial Transformer Networks, see how they work, where they can be used, and try to understand what you as an engineer can do with this knowledge.
What are Spatial Transformer Networks?
To put it simply, they're the equivalent of doing "cuts" in a movie. Rather than looking at an image or scene from the same perspective every time, you apply transformations, and therefore have access to these cuts.
An example?

See? It's like zooming always to the traffic sign. And "zooming" is only one of the many spatial transformations we can do. We could change the perspective, rotate, and do many things on these images. The key idea is that we input an image, and output the transformed image.
It's something happening inside a network, that isn't always needed, but that could be very much useful in specific cases. Let's say for example that you have a digit classifier, a STN could be applied to then classify the traffic sign as 120. Another example could be when you need to apply spatial transformations to feature maps, like for example when taking them to the Bird Eye View space.
We will discuss examples at the end of the article, but right now comes a question:
How does a Spatial Transformer Network works?
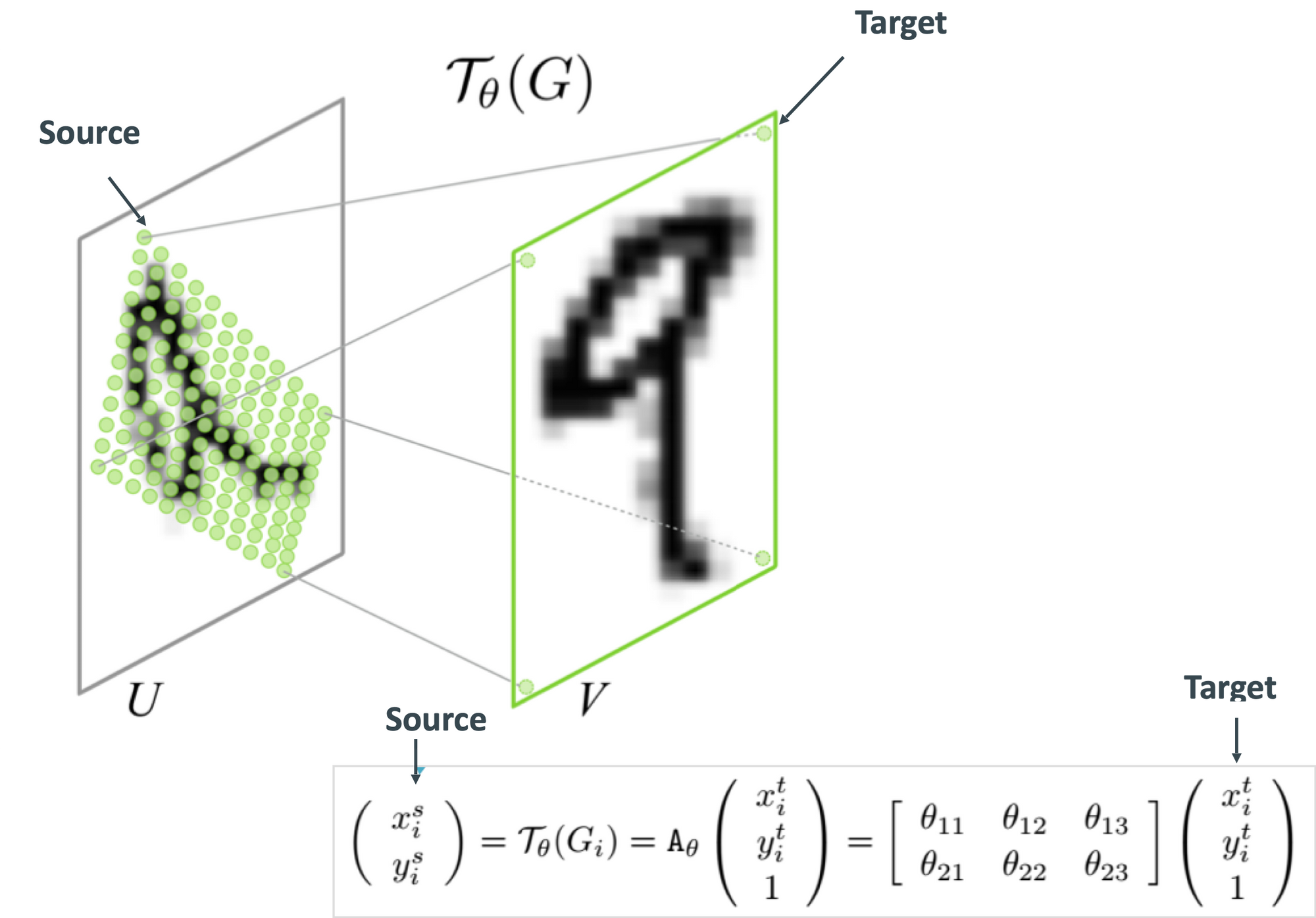
This is a STN according to their original paper:
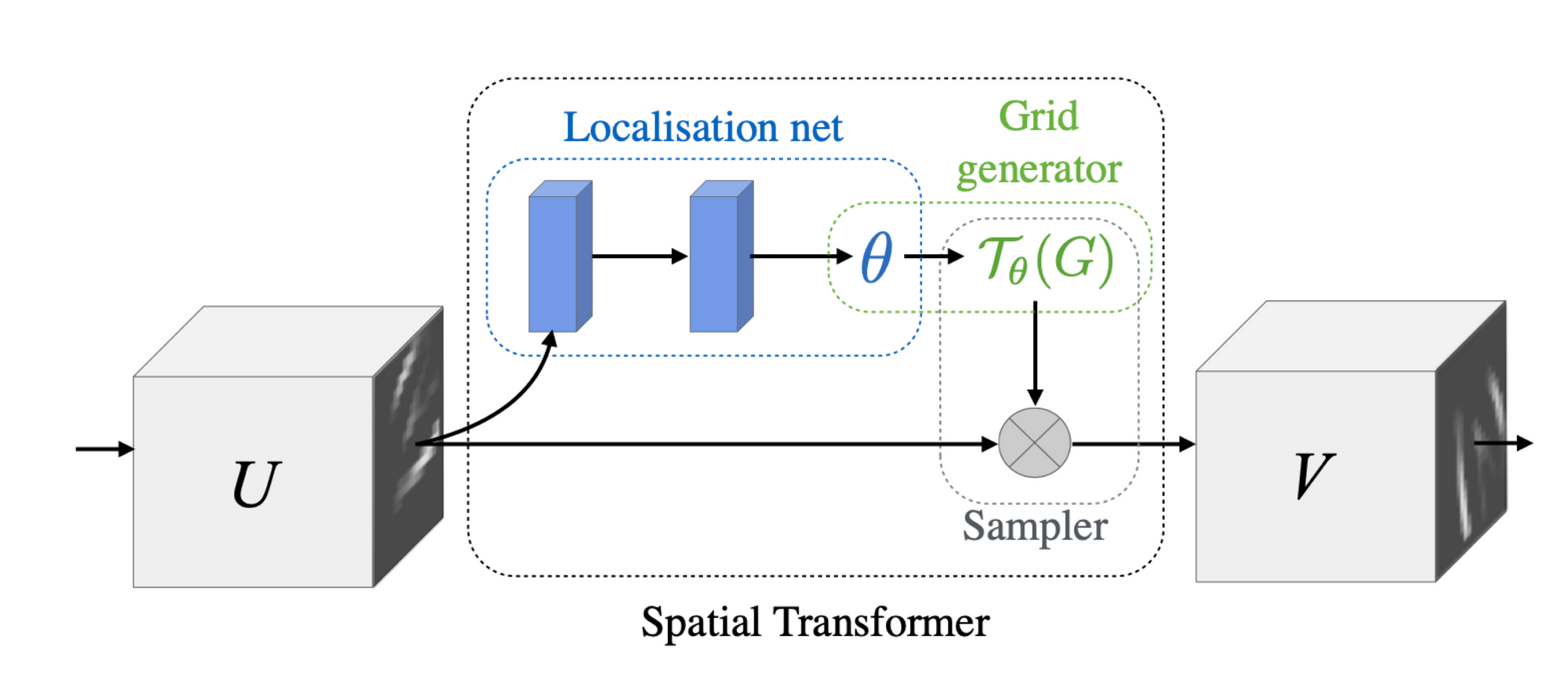
Notice the 5 key parts:
- U — the input
- The Localisation Net
- The Grid Generator
- The Sampler
- V — the output
First, notice that both U and V are feature maps here. This means that you usually don't apply a Spatial Transformer on an image, but rather on top of feature maps. It's going to be the same for the output, it's all feature maps!
The Localisation Net
The localisation net is a neural network that regresses a value for theta θ. Don't try and search very complex architectures, it can just be 2 fully connected layers, that try to predict a number theta. This theta is like a "rotation" parameter we'll use right after. In code, it can be as simple as this:
# reshape your convolutions into a vector
xs = xs.view(-1, 10 * 3 * 3)
theta = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2))(x)See? it's a simple thing that, at the end, predicts 6 values (3*2). What is theta made of? These are the 6 parameters of a 2D affine transformation, these parameters control scaling, rotation, translation, and shearing along x and y. Look at this for example:
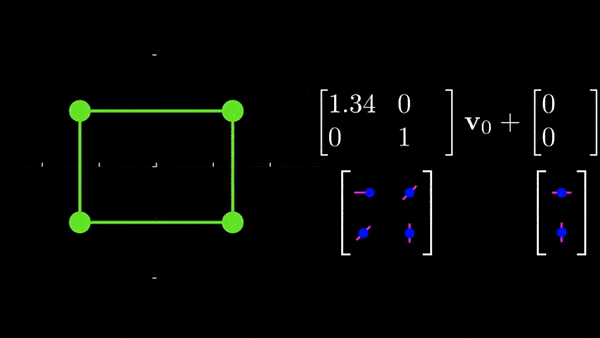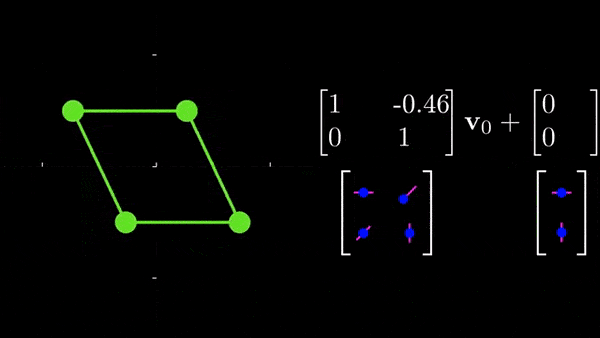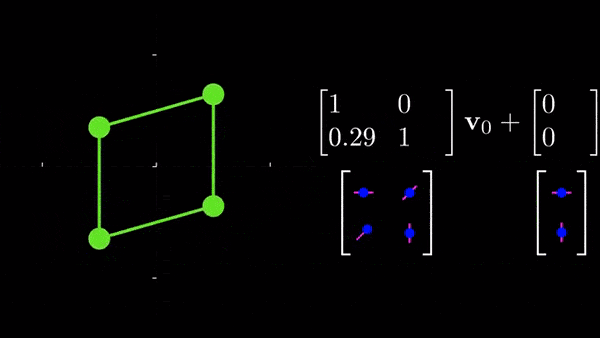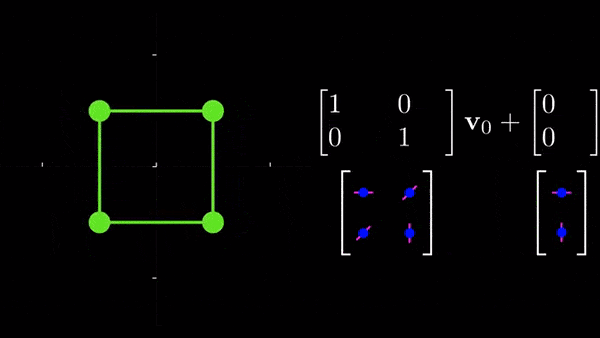
If you want to explore affine transformations further, I would highly recommend the amazing source I linked that show how each parameter controls rotation, scaling, etc...
So, we get that we have a network that "learns" how to modify feature maps from one plane to another... what then? Then we need to apply the transformation — and this is what the grid and the sampler.
The Grid Generator
The grid generator is a function that creates a grid that will remap pixels from the input feature map to pixels from the output using the theta matrix.
What's interesting about this is that we already know the target, and the theta matrix, so we essentially construct a blank image (called a sampling grid), and then try to find the source pixel and paste it in the blank image (we work backward).
Finally:
The Sampler
The sampler is what actually does the transformation. If you got it right:
- The localization net calculates the needed translation, rotation, etc...
- The grid generator calculate the source and destination pixel for each pixel
Therefore, the sampler is going to take both the input feature map and the sampling grid and using e.g. bilinear interpolation, output the transformed feature map.
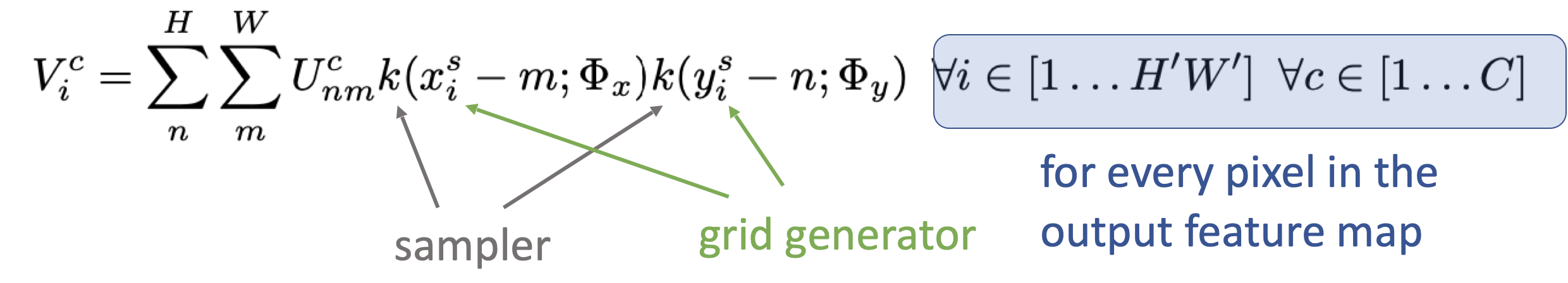
In code, these affine transformations are so well-known that you don't even need to do them by hand, you can just call PyTorch functions and it will do these for you. Something like this.
grid = F.affine_grid(theta, x.size())
x = F.grid_sample(x, grid)So you now get what a Spatial Transformer does, and we could even look at some code example:
def stn(self, x):
... some convolutions to get feature maps
xs = xs.view(-1, 10 * 3 * 3) #resize to vector
# localization net
theta = nn.Sequential(
nn.Linear(10 * 3 * 3, 32),
nn.ReLU(True),
nn.Linear(32, 3 * 2)
)(x)
theta = theta.view(-1, 2, 3) #reshape to a grid
# Grid Generator
grid = F.affine_grid(theta, x.size())
#Sampler
x = F.grid_sample(x, grid)
return xNow, let's see 2 examples that I think you'll like...
Example 1: Bird Eye View Networks
In my course on Bird Eye View Perception for Self-driving car engineers, I have an entire module on homographies, and how they can be used to generate "bird eye view" scenes. However, there is also a project where you can learn to create a spatial transformer module that take feature maps into the Bird Eye View space, like this:

Now realize that once you have a Bird Eye View feature map, the job is almost done. You could even use several spatial transformer modules (one for each image) and then fuse multiple bird eye view maps into a complete 360° scene, and end up with multi view Bird Eye View Perception systems like here:
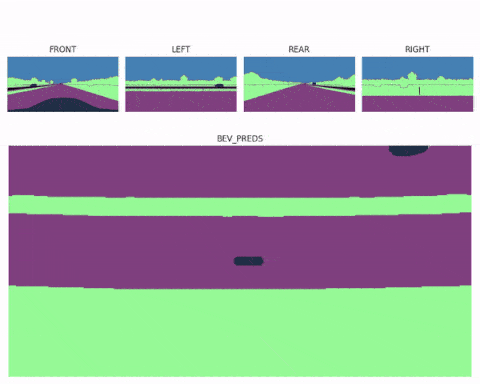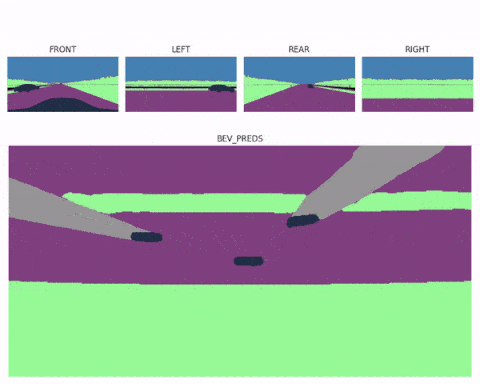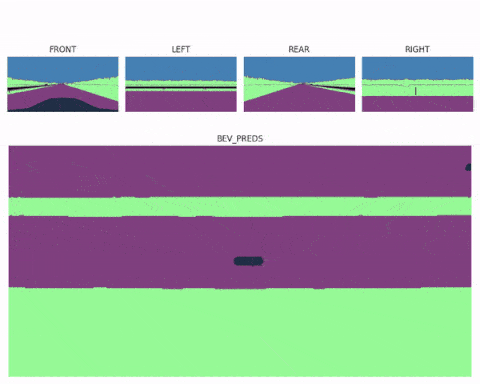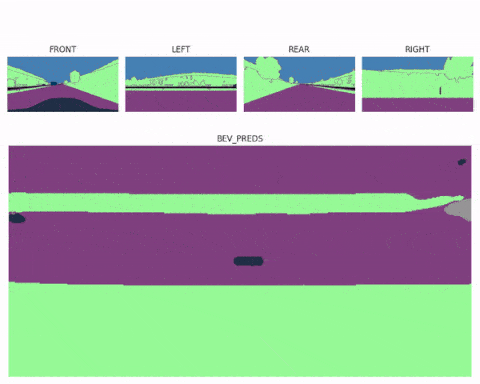
Next, let's see a second example...
Example #2: Point Cloud Processing
Ever noticed how Point Clouds always show up from different angles? I mean, let's say you want to classify a point cloud using Deep Learning, like this:
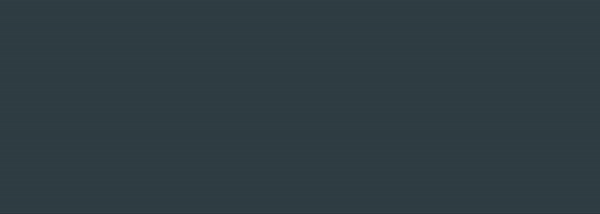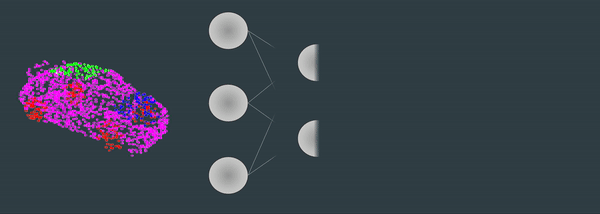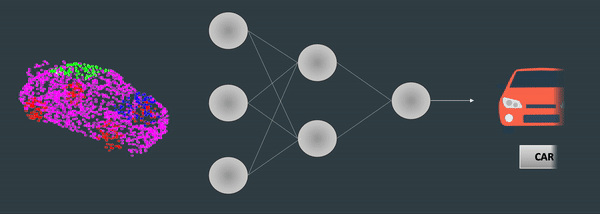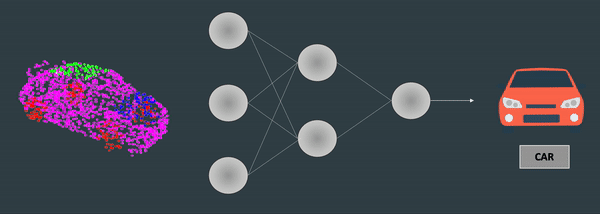
Well — this is nice, but what if your point cloud come up in the other direction? Or from the front? How do you handle rotations? In an image, it's pretty straightforward, because there is this nice continuity of pixels, and we have convolutions... But in a series of 3D points, the order of points are mixed up, and you can't directly use convolutions.
So you use Spatial Transformer Networks! In algorithms like PointNet, an STN is used via 1x1 convolutions to rotate and, as they say in the paper, "align the point cloud to a canonical space". This allows to always have the point cloud in the same angle when you process it, and thus makes things easier.
Keep in mind that this algorithm (PointNet), that you can by the way learn through my 3D Deep Learning course, is used in the majority of the point based 3D Deep Learning algorithms, and so it's therefore omnipresent.
Okay but...
Aren't Transformers also doing it?
You may have heard of another type of Transformer Networks... Transformers! The models behind Chat-GPT, but also behind Vision Transformers —and you may wonder whether they can do this too?
Well, no. In fact, they may have a similar names, but they actually serve different purposes.
- Transformers: Originating from natural language processing, Transformers are designed to handle sequential data, focusing on capturing dependencies regardless of distance in the sequence. They are now also used in various fields, including computer vision, but their primary function is to model relationships in data, whether it's words in a sentence or pixels in an image.
- Spatial Transformer Networks (STNs): STNs, on the other hand, are designed specifically to apply spatial transformations to data. They allow a neural network to learn how to spatially transform an input image in a way that enhances the extraction of relevant features. This includes spatial manipulation tasks like scaling, cropping, rotating, or warping the input image.
So, they're not the same; and while we could train a Transformer Network for this kind of task, there's no point when we have a module designed specifically for this particular operation.
Alright, time for a summary!
Summary
- Spatial Transformer Networks (STNs) are the equivalent of doing "cuts" in a movie. They allow to always look at a scene the way we want to, and to have an ideal view every time.
- The input and output of a Spatial Transformer Network are most of the time feature maps — meaning we have already been through convolutions and we process what's in the middle of a existing convolutional architectures.
- Via the localization network, we can do rotations, translations, shearing, and even scaling by learning affine transformation parameters. This goes way beyond doing "cuts", and this θ value is made of 6 parameters (in 2D).
- The grid generator then calculates a transformation of each pixel in the feature map following the θ parameter.
- Finally, the sampler is going to apply the transformation and generate the output feature map.
- We can use STNs in many applications, like Bird Eye View Networks, or even Point Clouds Processing with Deep Learning.
- Spatial Transformers are different than Transformers and serve different purposes. STNs are done specifically to calculate a transformation of a feature map from one plane to another.
Next Steps
Are you interested in learning more about using Deep Learning in Self-Driving Cars? I'm regularly talking about Deep Learning through my private daily emails. They're ready by over 11,000 engineers all over the world, and will help you understand how to use Deep Learning in Self-Driving Cars.
👉🏼 Fact is, you already missed today's email that I sent a few hours ago... make sure to receive tomorrow's email here.