BEV Fusion: Why Sensor Fusion is best done in the Bird Eye View Space
It was 2009, and Bob Iger, the CEO of Disney just got ghosted again by Marvel's CEO Ike Perlmutter. For the past few months, Disney tried to acquire Marvel, without much success. Not only Marvel's head was a mystery to Disney's CEO, but he also and mostly did not want to sell.
But Bob was decided, and saw a huge potential in Marvel. Against his board's recommendations, that included Steve Jobs (who had just sold Pixar to Disney, and was opposed to buying Marvel), Bob needed to find a way to convince Ike to sell Marvel and the thousands of characters it had.
And at some point, he came with THE argument: Brand Protection. Who could protect Marvel's brand better than Disney, who protected their own brand for a hundred years? Who could create characters better than Disney? Who was more involved in storytelling and universe building than Disney? If Marvel were to be sold, it would be to Disney, and nobody else.
This argument helped convince Ike that Disney and Marvel had a common ground, and showed Marvel that its future would be in good hands with Disney.
Common ground is also what makes Sensor Fusion work the best. A LiDAR and a camera are like Disney and Marvel: they aren't the same sensors, they're not even on the same dimensions. But when you apply a tiny transformation to both of them, you can find a common ground perfect for Sensor Fusion.
This transformation is called Bird Eye View... and in this article, I want to talk about the BEVFusion algorithm, which is one of the best algorithm to fuse sensors such as LiDARs, RADARs, or multiple cameras. In this post, we'll see why the algorithm is needed, how it works, and who uses it.
Why Bird Eye View is a great solution for Sensor Fusion
What happens when you try to fuse 6 camera images with a LiDAR point cloud? Well, you have a dimensionality problem. Your point clouds are in 3D, but your pixels are in 2D. So far, existing solutions involved projecting one space to the other, such as point clouds to the images. But when doing so, we were losing part of the camera and LiDAR information.
For example, if you project the LiDAR data (3D) to the camera space, you're losing geometry — and if you're doing the other way around, you're losing the rich semantics from the camera.

Similarly, if you fuse the detections of the LiDAR sensor (3D Bounding Boxes) with the camera detections — which is called Late Fusion — you're reduced to doing object detection only.
This is why Bird Eye View is a great solution: it's a way to preserve both geometric structure and semantic density, by adopted a common representation. And in our case, we don't even fuse the raw data, but the LiDAR and camera features directly. This will be useful not only for fusion, but also to build our HydraNet...
How BEV Fusion works: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
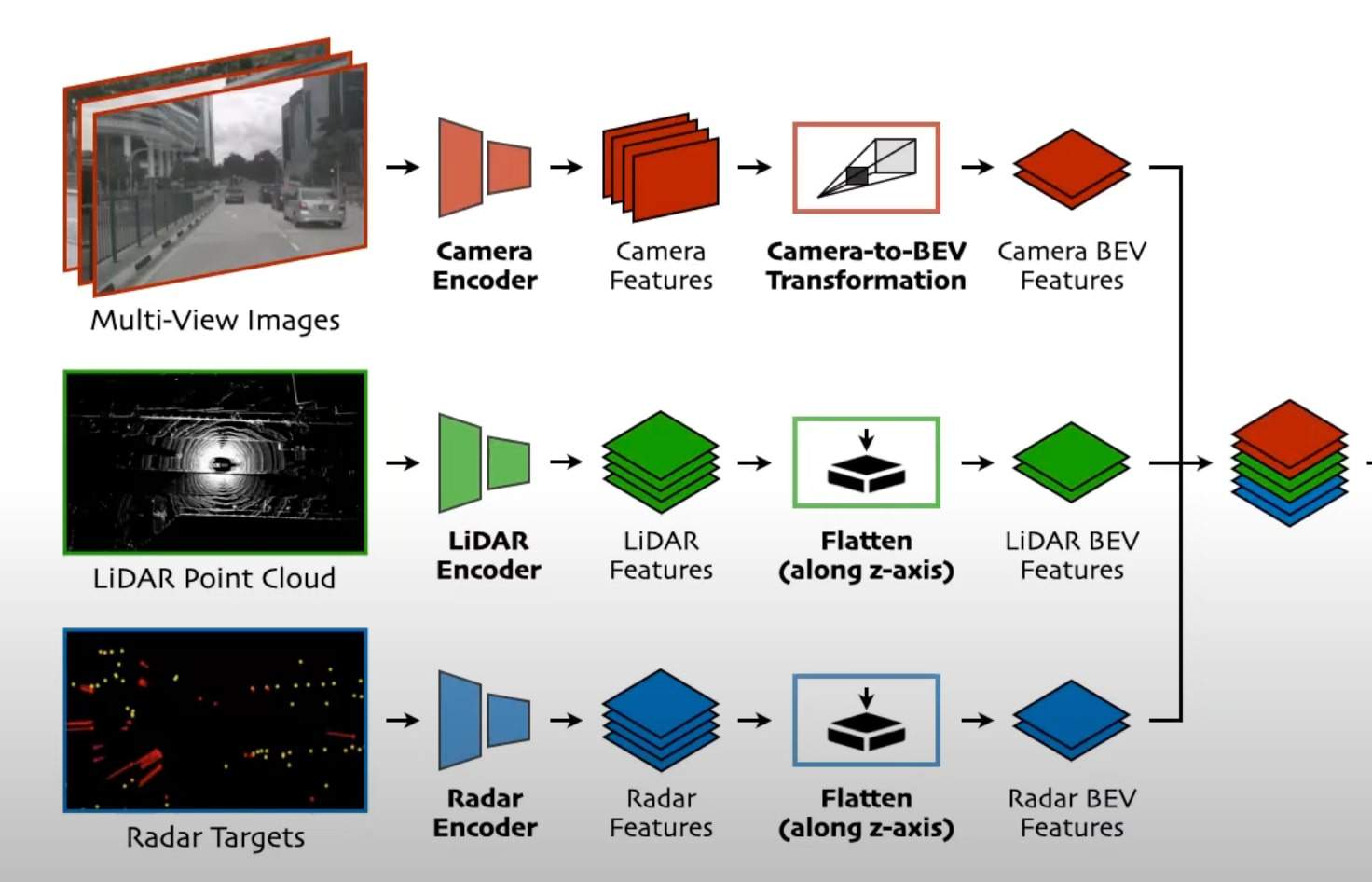
This is the architecture of BEVFusion:
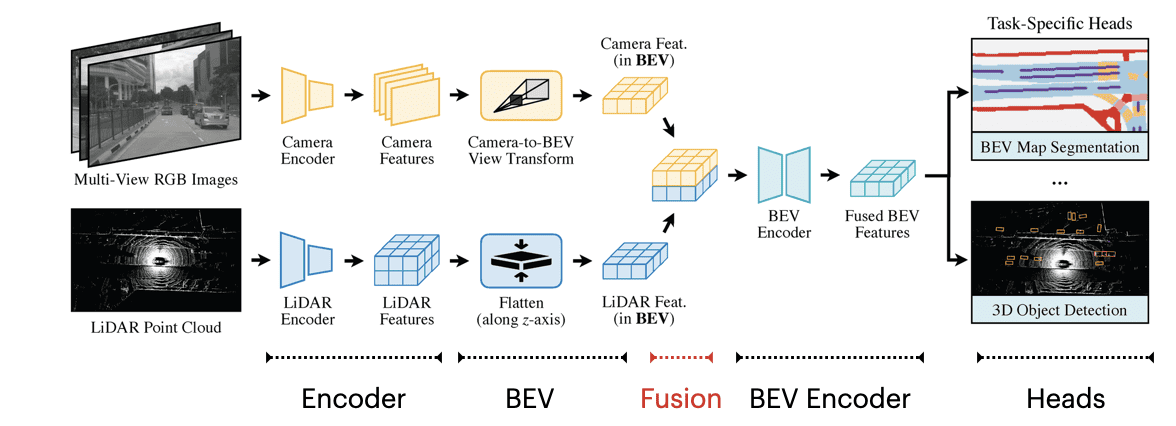
Notice what's happening? We have 5 main stages:
- Encoders: Each of the sensor data goes through an encoder and becomes features.
- BEV: Both the camera and LiDAR features are transformed into BEV Features.
- Fusion: The BEV Features from both sensors are concatenated together.
- BEV Encoder: We then have an encoder designed to learn from the concatenated features.
- Heads: Finally, we have heads for object detection and BEV map segmentation.
1 — Encoders
Encoders are meant to learn. Traditionally, it's just a set of convolutions designed to transform raw data into feature maps. In our case, we use:
- The Image Encoder: It can be a ResNet, VGGNet, or any other you like.
- The LiDAR Encoder: It can be a PointNet++, learning from the points directly, or it can be a set of 3D Convolutions happening after a voxelization process.
In the authors implementation, several combinations of encoders are tested, and one including voxelization, pillarization, and CNNs is used. If you just realized you're weak on 3D Deep Learning for Point Clouds, I invite you to check out my Deep Point Clouds course here.
2 — BEV Transformations
Once we have been through the first layers, how do we turn them into Bird Eye View features? We have two types of transformations:
- Camera to Bird Eye View
- LiDAR to Bird Eye View
In the camera case, BEVFusion uses a technique called Feature Lifting, which involves predicting a probability distribution of depth for each pixel. This means that for each pixel, you predict depth. This generates a camera feature point cloud.
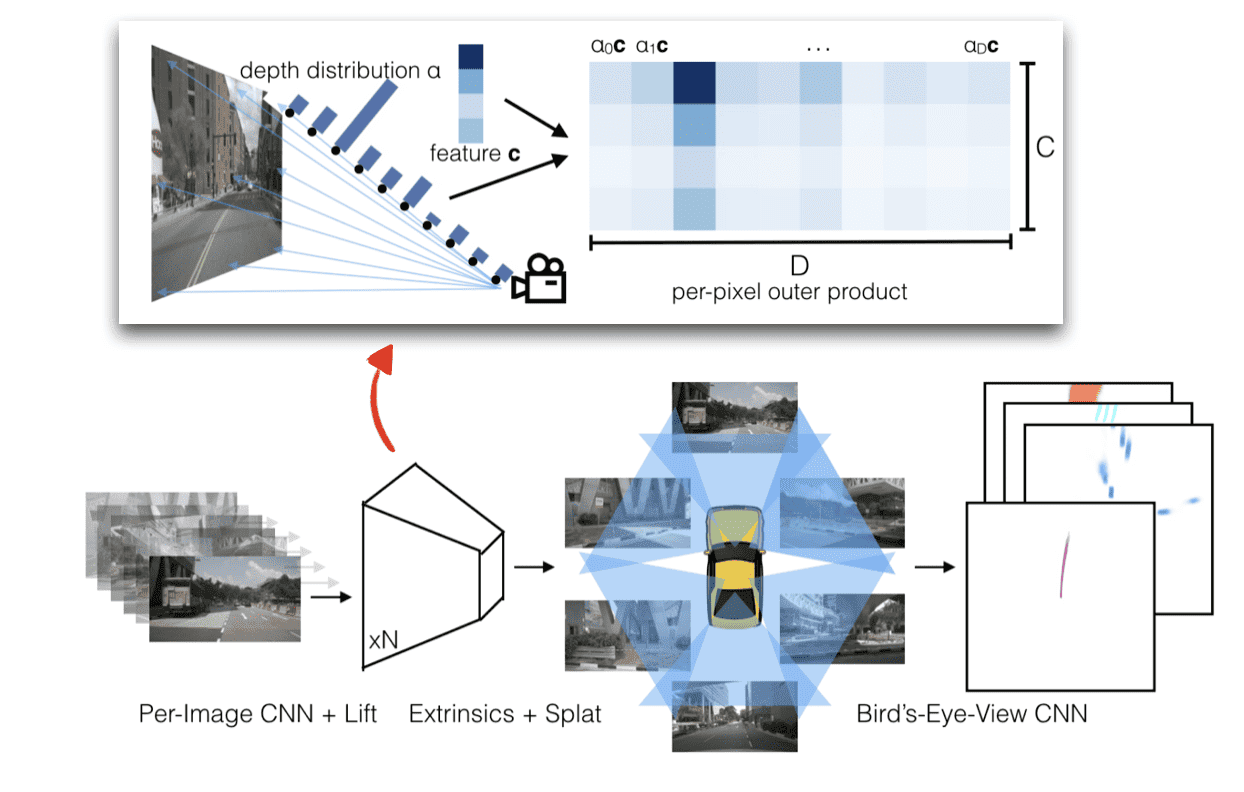
An example?
- After a convolution, pixel (0,0) has a feature value of 2.
- After lifting, we predict the depth distribution (0, 0.5, 1.5, 0.5, 0)
- We then multiply 2 with the most likely (1.5) and get a 3D feature value we can use.
We then use BEV Pooling to aggregate all features within cells of a BEV grid. The grid is used as a common ground across several images, several sensors.
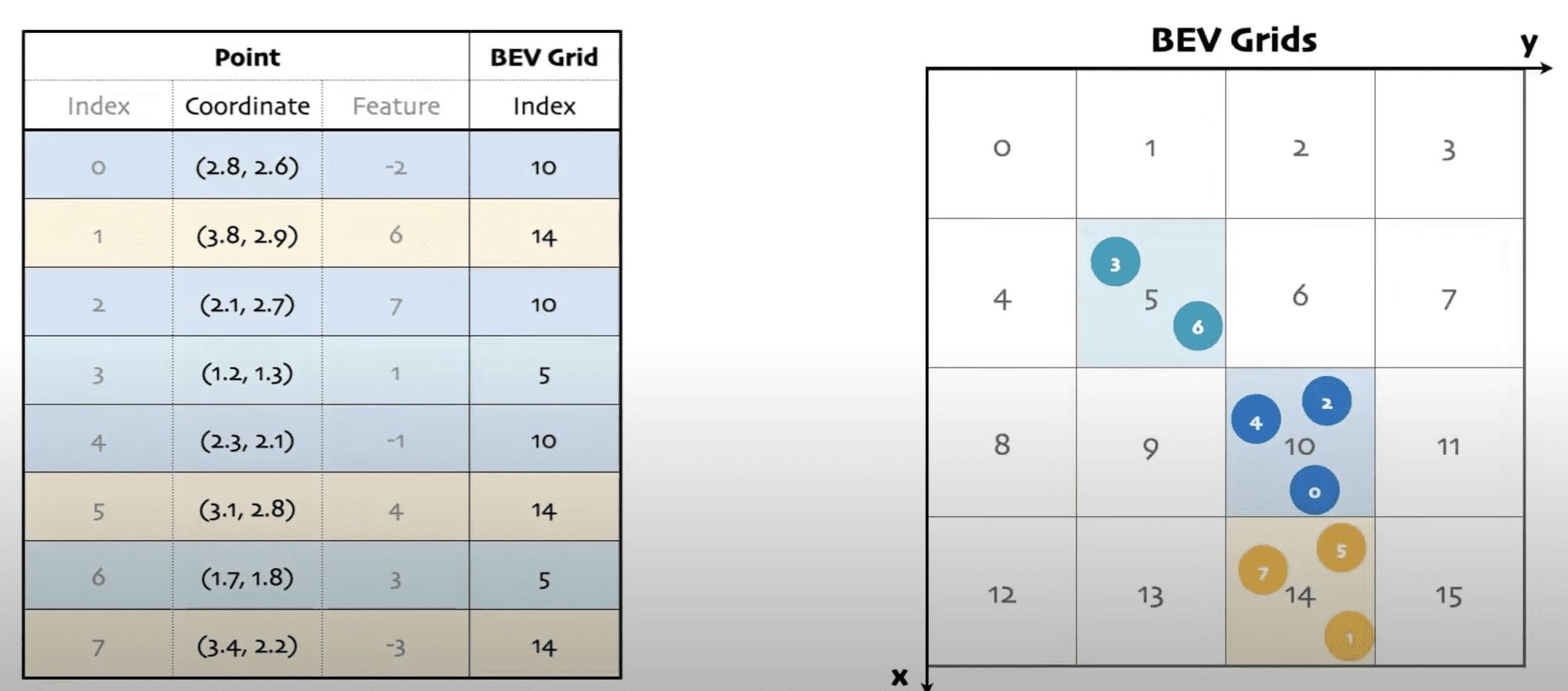
In the LiDAR case, features are already in 3D, so the main thing we need to do is to flatten these along the Z dimension: we make them 2D, but in Bird Eye View space.
3 — Fusion
This step is where the magic happens, and yet, it's the simplest. Everything is under Bird Eye View representation. Therefore, to concatenate them together, all you need to do at this point is... A Concatenation operation!
Something like `torch.cat()` works relatively well, and we're good to go.
What you can also see here is that the potential goes beyond LiDAR/Camera Fusion. We could just as easily do the same operations on RADAR point clouds, and end up concatenating the RADAR as well.
BEV AutoEncoder
Okay, I lied. If you just superpose the features from the camera and the LiDAR, there may be some misalignment... and this because the camera conversion may be a bit imperfect, or there may be some realistic LiDAR malfunction. This is why at this stage, we apply a convolution-based BEV encoder (with a few residual blocks) to learn more and compensate for the misalignments.
Heads
Finally, you must realize that BEVFusion is a HydraNet. This means that for this single network, we have several heads, and we can therefore do several tasks. Each head solves one task, so instead of having a network for object detection, and another one for segmentation, we have just one network with two heads.
Similarly to a backbone, the heads can be interchangeable. You could use the head from YOLO, or SSD, and that would work. In this case, they're using the head of CenterPoint, a 3D Object Detection algorithm that regresses the center of bounding boxes, as well as the object size, rotation, and velocity.
On the segmentation side, the algorithm predicts a BEV segmentation mask among 6 classes: drivable space, pedestrian crossing, walkway, stop line, car-parking area, and lane divider. This isn't like a regular segmentation, it's actually a map being predicted. From there, you can predict a path and drive!
Output
The output of the algorithm is 2 tasks: 3D Object Detection & Map Segmentation.

Example? How Aurora uses Bird Eye View for Sensor Fusion
Going larger than this one algorithm, you can see how the Bird Eye View space is a great choice for Sensor Fusion. For example, in this article, you can see Aurora using Bird Eye View, or how they call it "Euclidean View", to build this common ground representation.
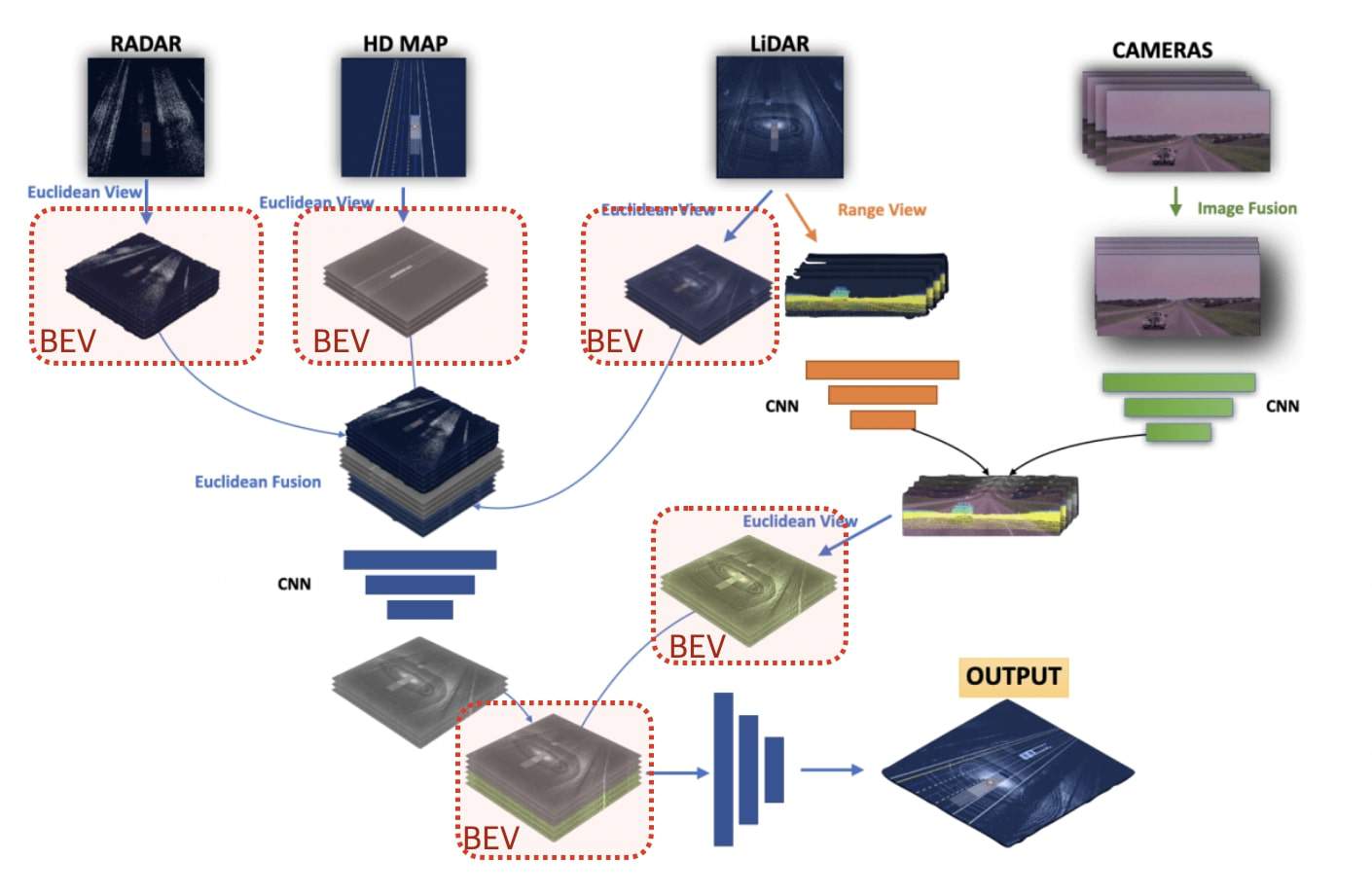
BEVFusion is introduced as a powerful solution for a reliable autonomous driving system; and I bet a lot on this kind of architecture for general sensor fusion. It begins with separate encoders, and then turns each of the feature maps to the Bird Eye View space. Each set of BEV Feature Maps is then concatenated, before we add an Encoder and Heads on top of it.
Next Steps
- If you'd like a general overview of Sensor Fusion, I invite you to read my Intro to Sensor Fusion article here.
- If you'd like to learn more about Early & Late ways to fuse LiDAR & Camera data, I invite you to read my dedicated article here.
- To get further on implementing Sensor Fusion algorithms, you can take my Visual Fusion course here, and my Bird Eye View course there.