2 Ways to do Early Fusion in Self-Driving Cars (and when to use Mid Or Late Fusion)
A while ago, I was involved in an open source self-racing car initiative, and was part of a team in charge of Computer Vision. The first thing our team leader asked us to do was a study on object detection algorithms.
— "Okay, let's start by looking at papers and understand together what they're about" I started
— "No, it's better if we each read the papers on our own, and then share our conclusions." said another
— "You guys know how to read papers?" said a third in confusion.
We were stuck.
Which way should use go with? In the engineering world, students love the default technique of having engineers on their own, reviewing papers, and then after a week or two, share their conclusions. I thought this was a waste of time, as the others never really do it, or do it in a rush last second.
But do you see how we have two clear strategies here? We have an "Early Fusion" strategy, which involves fusing our brains right at the beginning, before we even read the paper... And we had a "Late Fusion" strategy, which was about fusing our conclusions after we had done our reading.
And in Sensor Fusion, this is exactly the same, there are "moments" to fuse data. Take, for example, a LiDAR Camera Fusion pipeline. We could do an early fusion of LiDAR point clouds and camera pixels, or a late fusion of bounding boxes. These two procedures for this exact examples are detailed in my article "LiDAR/Camera Sensor Fusion in Self-Driving Cars".
In this post, I'd like us to "zoom" in Early Fusion, understand what it is, what are our "options" to do it, when to do/not do it, and get a good understanding of this.
Let us begin...
What is Early Fusion?
The first thing to understand is that when talking about early or late fusion, we're talking about a "moment". When should we do the fusion? Right at the beginning? A bit later? At the very end? Originally, there are 2 ancestral ways to do the fusion, early and late.
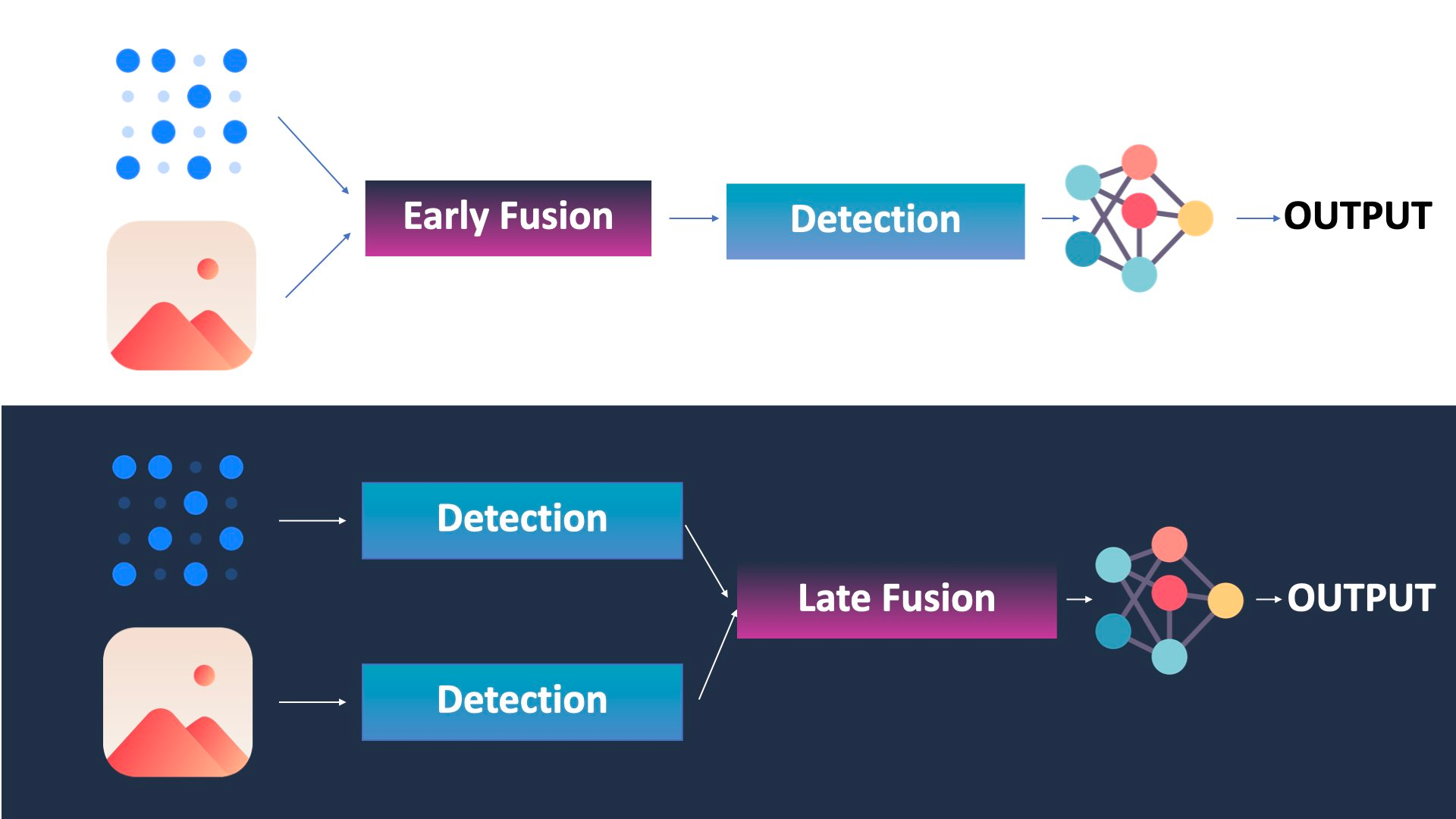
So as you can see, Early Fusion is about fusing raw data, while late fusion is about fusing outputs/objects.
In reality, there are also other types of fusion, such as Mid-Fusion, which involves fusing the features (after some convolutional neural networks and extraction — usually for image recognition), or sequential fusion, which is the Kalman Filter approach, where you'll consider the LiDAR, then the camera, then the LiDAR again... in a loop.
In this post, I want to do the focus on Early Fusion.
Now the question is... how does it work?
The 2 Ways to do Early Fusion
There are 2 ways to do Early Fusion:
- The Geometric way
- The Neural Networks way
Let's begin with the traditional way.
The Geometric Way
Let's keep the example of LiDAR and cameras, because I think it's a really good example. Not only the sensors are totally different, but they're also in a different dimension (the camera is 2D and the LiDAR is 3D).
The first approach involves projecting one data onto the other. For example, you could project point clouds on images. Or you "could" project pixels in the 3D space. The first is more commonly done, but the second is also more and more done, especially in Dense SLAM and 3D Reconstruction. Whatever the case, it looks like this:

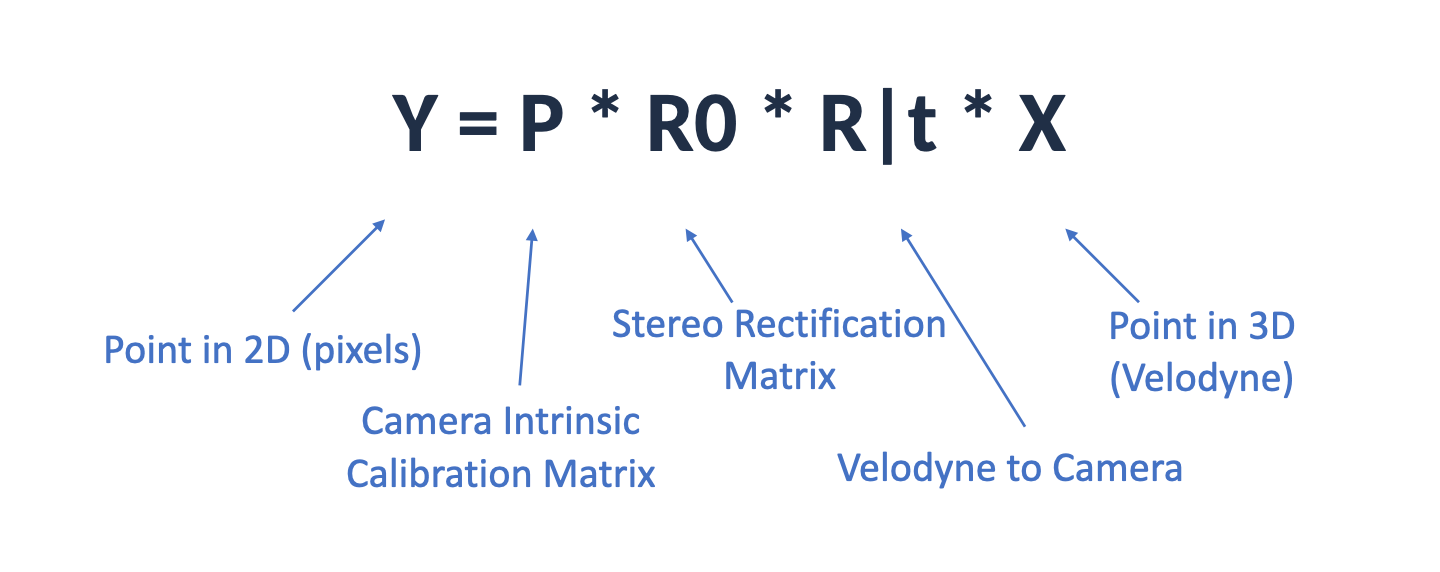
And of course, it's not "easy" to understand how to do this, because a point cloud is 3D, but a pixel is 2D. Yet, if you ever took 3D Computer Vision lessons, you probably heard about camera calibration, intrinsic and extrinsic matrices, coordinate spaces, and you probably saw that there are some math equations allowing us to move from one to the other.
When we are projecting the LiDAR point clouds to the image space, we're essentially moving from one coordinate space to another. A single point in the 3D Space is first converted to the Camera Space (3D), and then moved to the Image Space (2D). A formula can even help us achieve this:
And when using these parameters properly, you end up here:
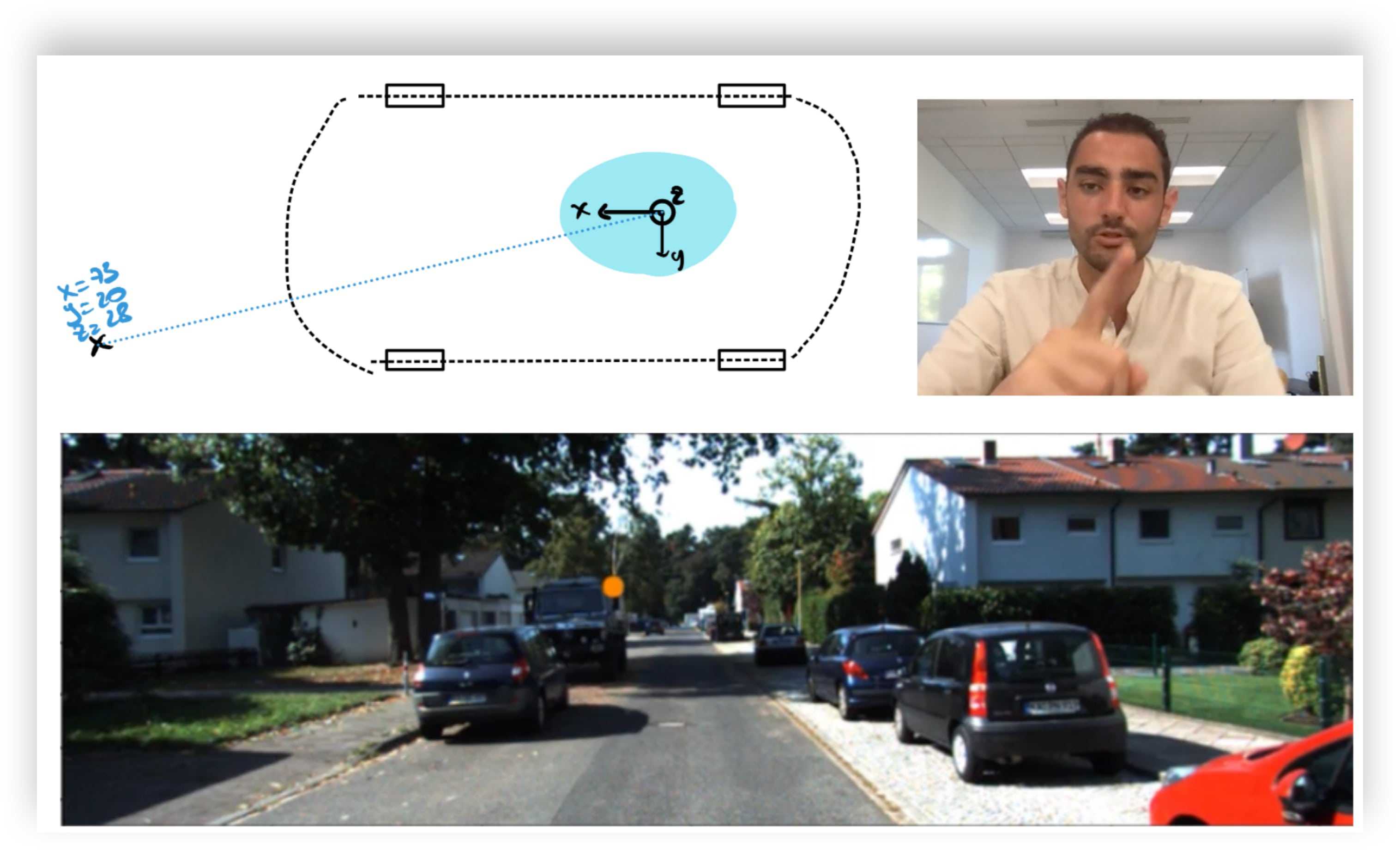
A very obvious (yet worth mentioning) note here is that the sensors need to be synchronized.
This isn't the only way to do, because you can also project pixels to the 3D space. And I say pixels, but it could also be visual features. In Visual SLAM, we often refer to these techniques as Sparse and Dense 3D Reconstructions. Or Direct and Indirect. In my SLAM course, there is a project where you learn to do 3D Mapping using exactly this idea of Feature Fusion.
In this image, we are not fusing pixels with points, but features with points.
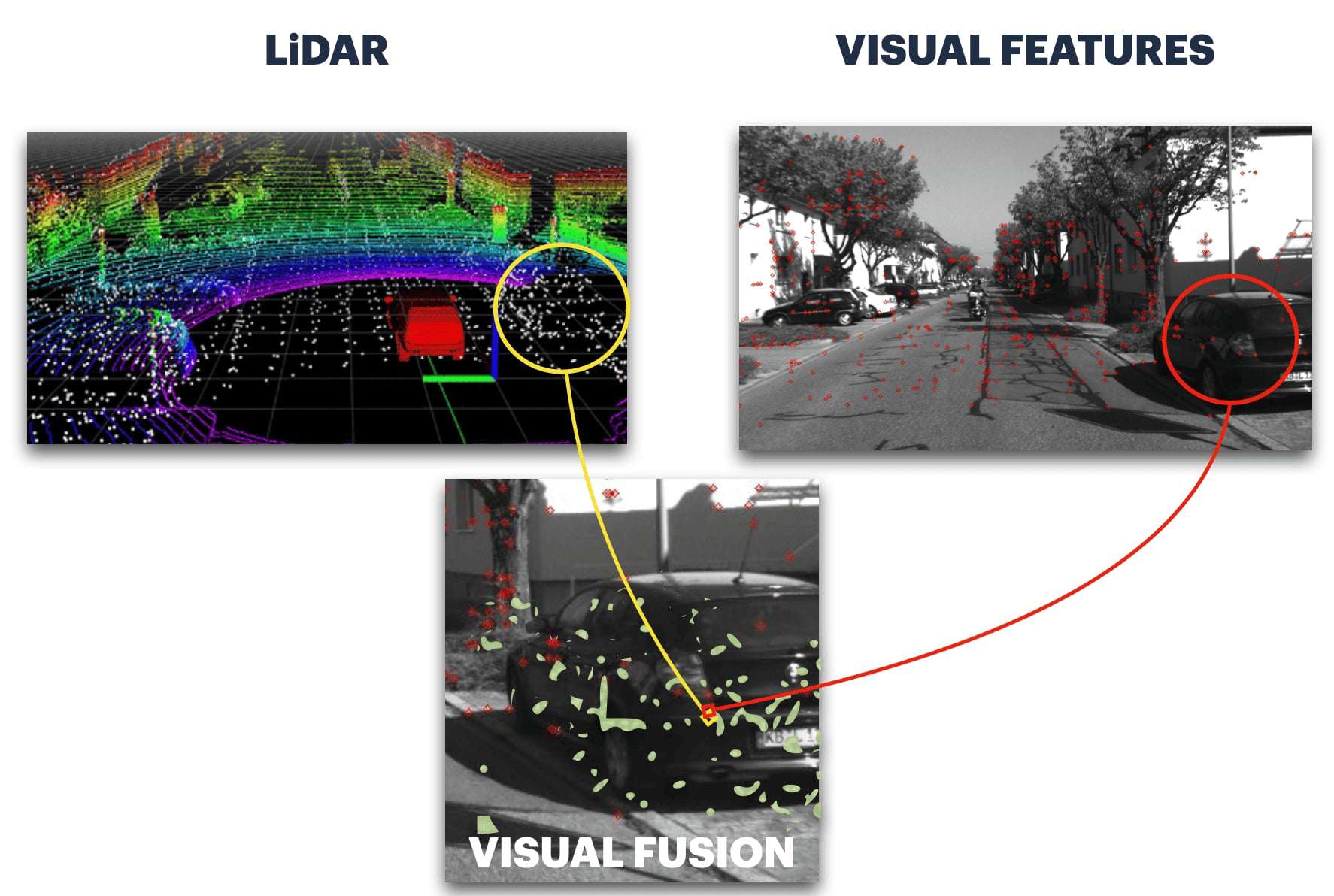
And we could also fuse features with features, in this case we'd fuse the highly correlated features, and not the rest. The reality is, sensor fusion can be done via many different approaches. There may be optimum fusion strategies, but we really have endless ways to do this.
Think about it, we could fuse:
| Camera | LiDAR |
|---|---|
| 2D Pixel | 2D Point (2D LiDARs) |
| 2D Pixel | 3D Point (3D LiDAR) |
| 2D Feature | 2D or 3D Point |
| 3D Pixel | 3D Point (3D LiDAR) |
So this is all the geometric way, without any Machine Learning. And you can already see how using these, we can already implement a complex early fusion strategy. I also talked about LiDAR and camera, but we can also fuse RADAR and Camera. We could fuse IMU and GPS. We could fuse multiple modalities in an early fashion.
Now let's see the same thing, but with Neural Networks.
Early Fusion with Machine Learning
When using Deep Learning, we add an additional layer of complexity... what are you fusing? Features? After how many layers? The very first? 3? 10? Does it matter? And what about the 2D vs 3D problem? Are you still projecting one to the other?
Okay, let's imagine this scenario, where we have a fusion layer like this one:
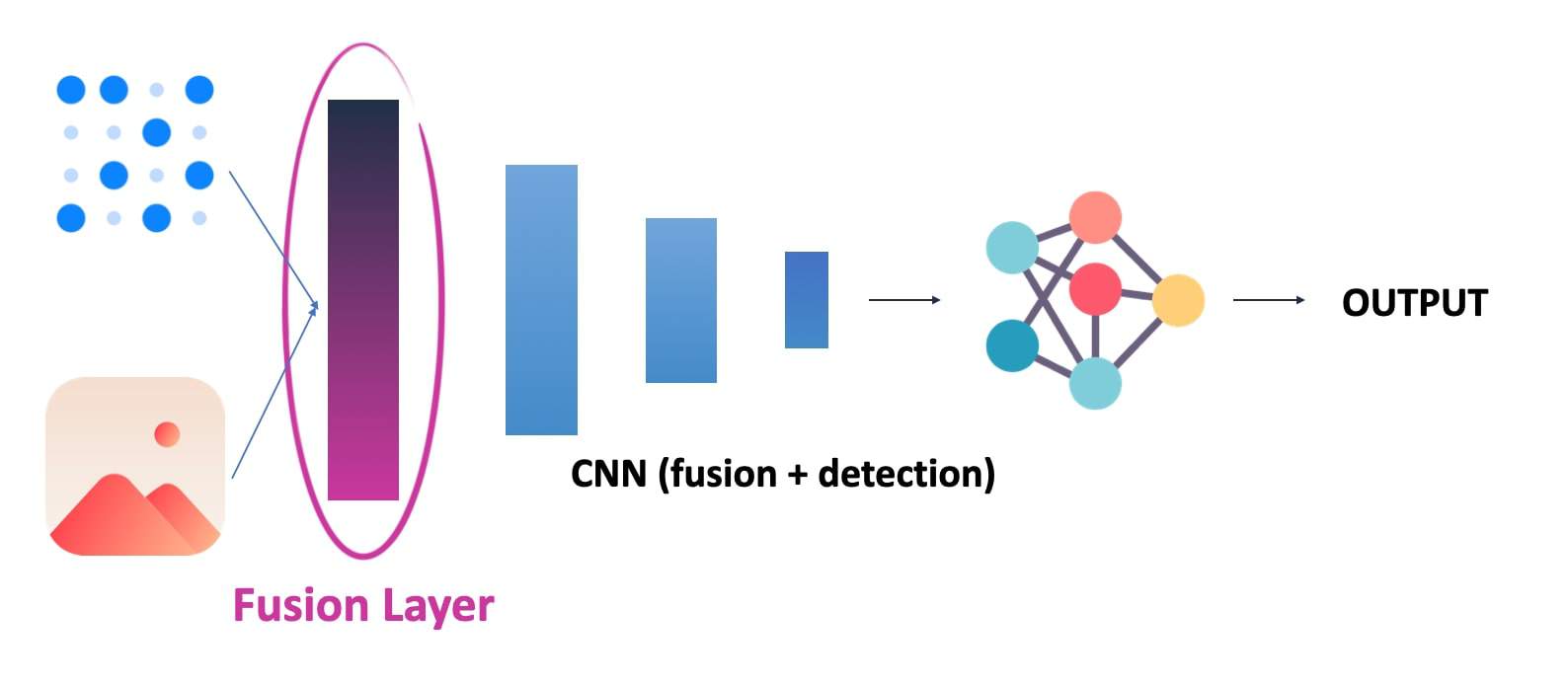
Notice how here, we fuse the raw data from Layer 1. This is a "true" early fusion.
On the other hand, if I first processed each data with a few convolutions, and then did a fusion after 3 or 4, it would look like this:
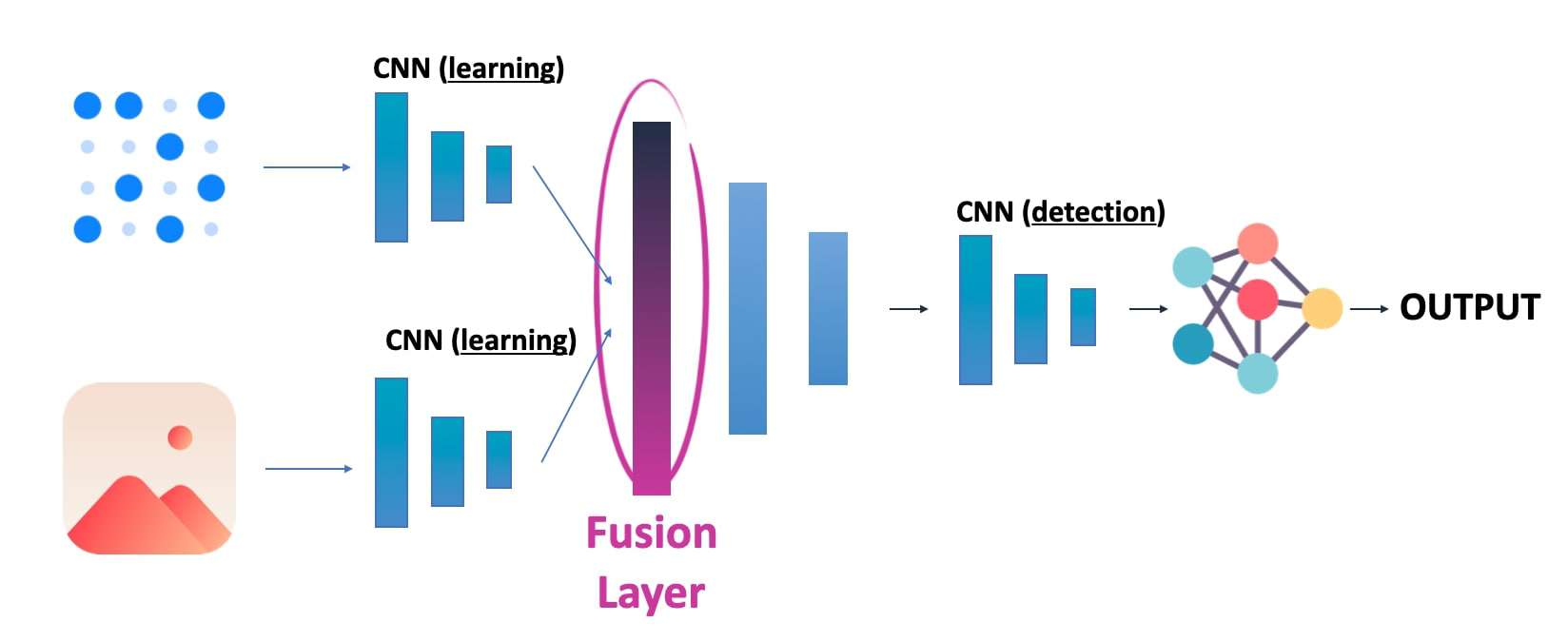
But that would no longer be "Early" Fusion, we rather call it "Mid" or "Intermediate Fusion". Notice how it's incredibly similar to the idea of "feature fusion" before? It's because we can either do a "direct" fusion, or a "feature" fusion, and this either using traditional or deep learning techniques.
Now comes the problem of actual fusion. What happens if you mix eggs and chocolate? It doesn't work right? You need to mix the eggs first, and make the chocolate melt. Then you can do a cake. The fusion is the same idea, we're not going to "learn", but we are going to process things anyway.
For example, we could turn the LiDAR into a range view image, and fuse that with an image.

So this is another way; not as for the practical fusion code, we're going to be in the concatenation, or addition layer; and this because we'll want to fuse a 2D range view with a 2D image, or things like this; that go together and can be added or concatenated.
Now, I'm going to digress a bit, but this idea will make much more sense if I talk about Mid-Fusion:
Bird Eye View Fusion
The most common way to do this is by converting both to a "common representation". I like to call it the "common ground". And it's often a Bird Eye View. You can get a full understanding of this via my post on BEV Fusion. For now, here is a picture I took from it:
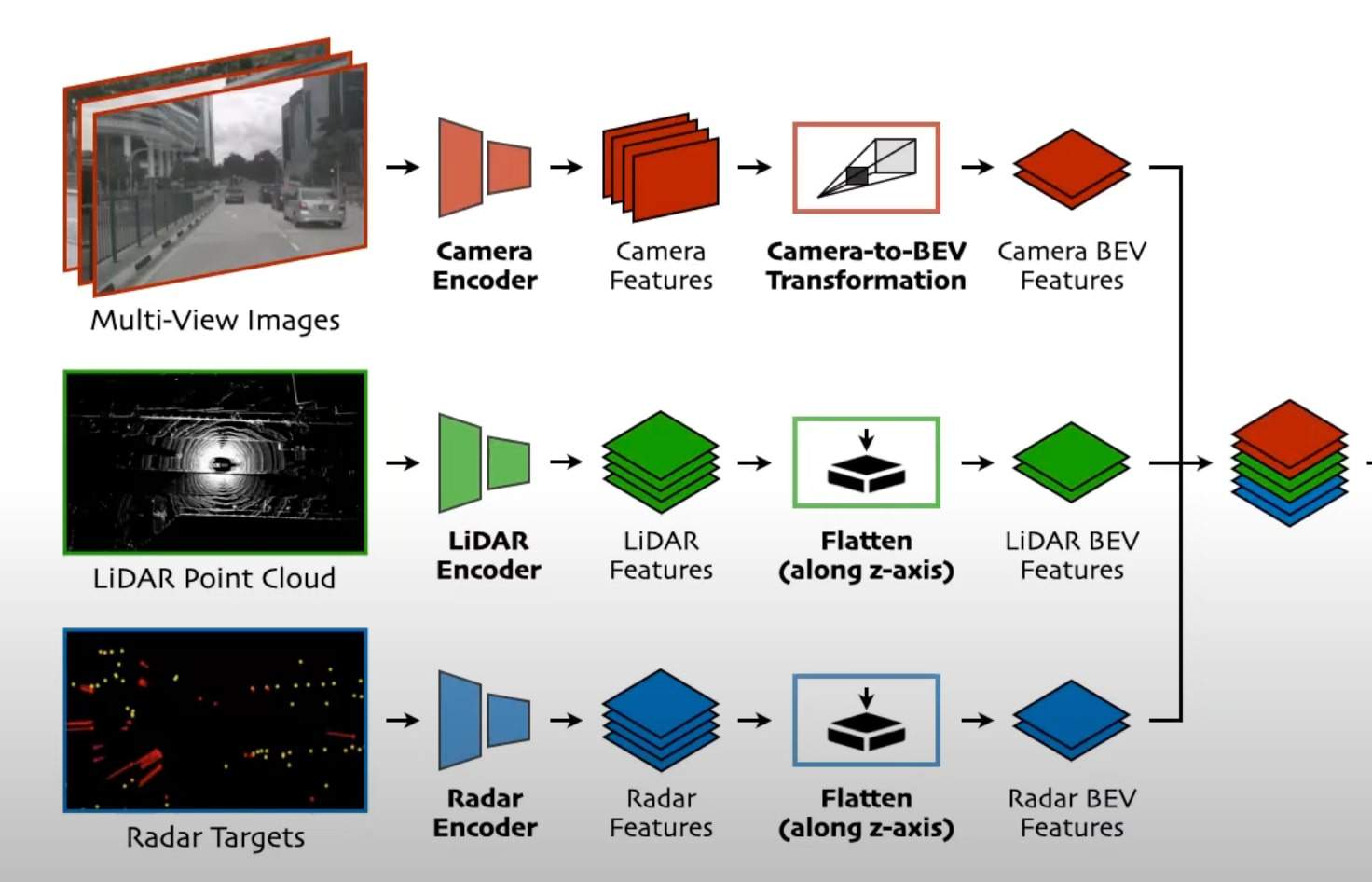
This may look like a "Mid Fusion" (and it is), but at least it shows the individual transformations to a Bird Eye View space, and these get fused. We use Bird Eye View because this way, everything is common. Pixels showing vehicles are exactly at the same position of point clouds showing the same vehicles, and so on... In this example, the data goes to Convolutional Neural Networks, and then gets converted to a Bird Eye View.
Quick Recap?
We are here:
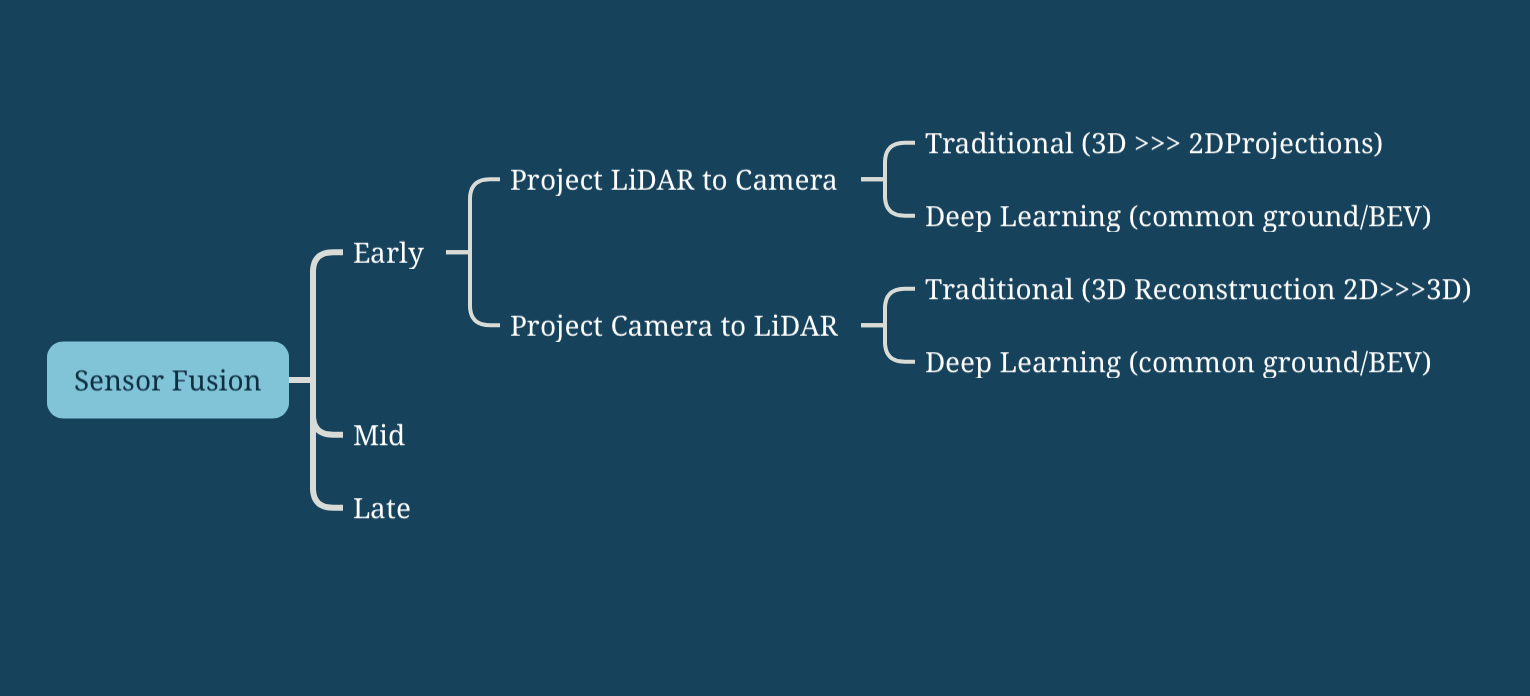
And now the question becomes... What if we want to look at Mid or Late Fusion?
When to use Early Fusion... and when to use Mid and Late Fusion?
So, you may be thinking: "Okay, but is Early Fusion better than Late Fusion? Or are there cases where one should be used and not the other?"
I'm glad you asked.
There are 3 ideas I want to talk about:
- In theory, Late Fusion would be better
- But in practice, Early Fusion may be better
- Or, does it depend?
Late Fusion in theory
Late Fusion is the idea of fusing objects, after they've been detected. In a Perception example, Late Fusion is the idea of mixing bounding boxes detected from the camera and from the LiDAR. If your bounding boxes are good, you should have no problem with the fusion.
To perform late fusion, many possibilities exist, but one I like is from my LiDAR/Camera Fusion article where you're fusing bounding boxes using criterias like 3D IOU, or by building a cost function.
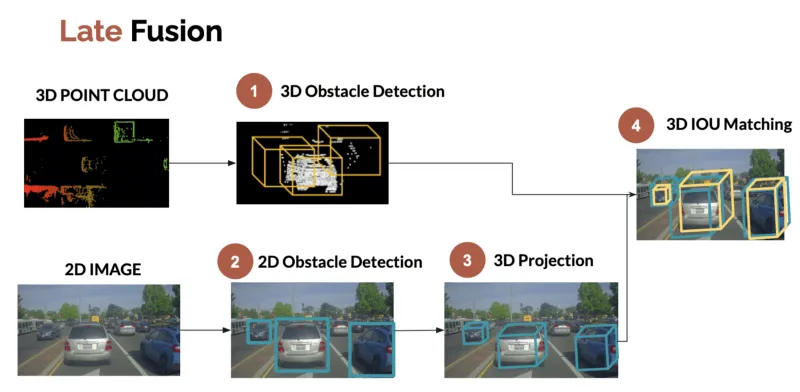
Now this is theory.
In practice, is Early Fusion better?
What we're doing here has a more technical name: multimodal data fusion. You're fusing data, from multiple modalities/sensors. And this using artificial intelligence, or robotics, or machine learning. So this can get complex.
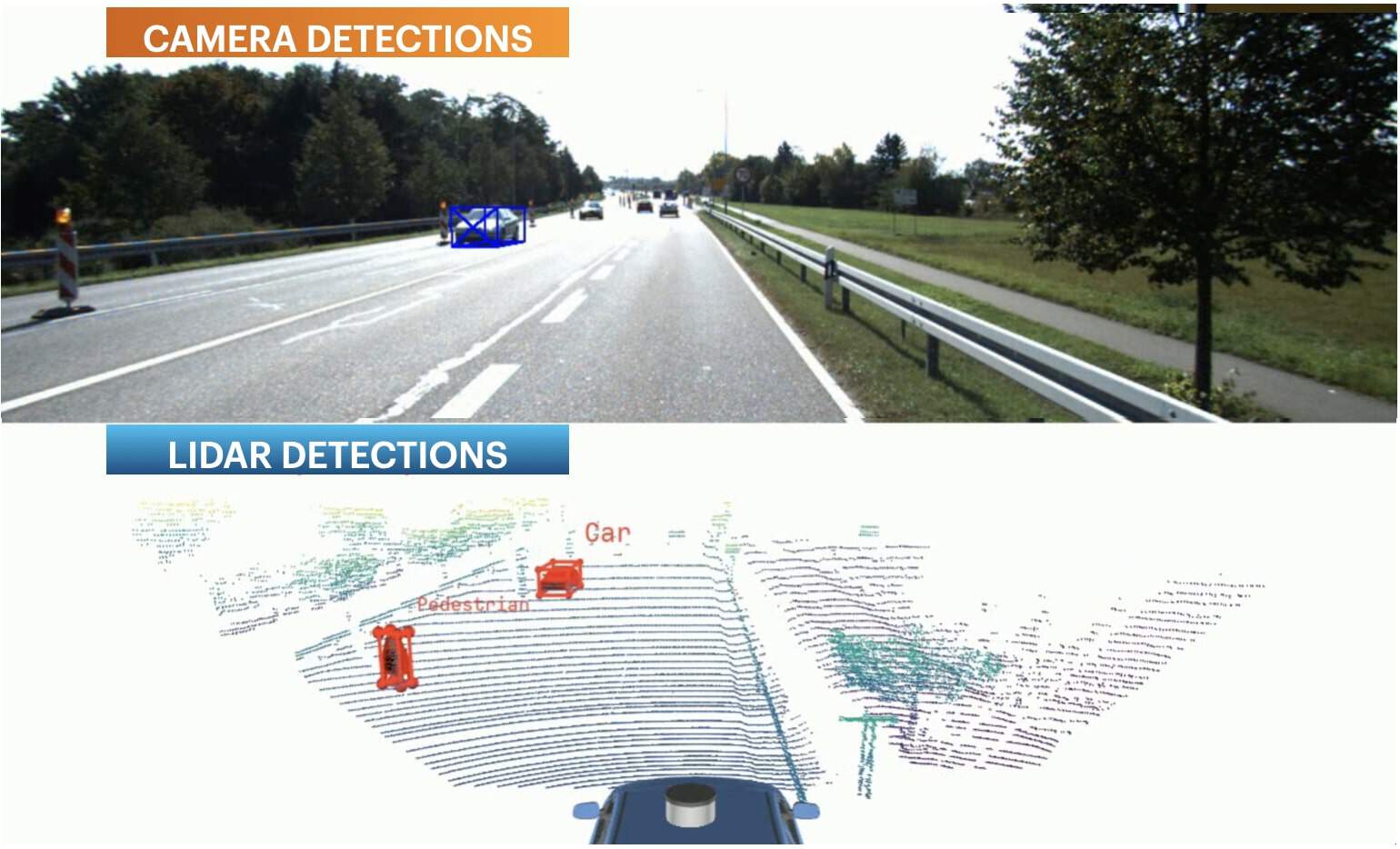
A first reason why late fusion may not work so well is, if one of your sensors isn't great. Back in 2018, I was working on autonomous shuttles with a 4-Layer 2D LiDAR SICK. The detections were there, but it wasn't really the 3D Bounding Boxes we see today.
In fact, here's a picture of the camera detections (in red) and the LiDAR detections (in green):

See? Late Fusion here is very difficult, because one of your sensors isn't great.
A second reason could be the algorithms themselves. If you're using a LiDAR Object Detector and this fails to detect objects, you're in trouble when doing the fusion. Same if you're doing 3D Object Detection on the camera.
See this example where the LiDAR confuses a traffic item with a pedestrian:
This is just one example, but hundreds of different examples of sensors disagreeing can occur; hence you have to build complex multimodal fusion strategies to handle unknown objects, or objects under-represented, etc...
Does it depend?
Now, I'm not saying Early Fusion is better. It could depend. If you're using similar sensors, with good algorithms, on simple tasks at low-speed, with handled environments, late fusion could be really what you're looking for. Especially since it's not that complex to design, and you have a lot of freedom.
On the other hand, early is either a projection of points to an image, or Deep Learning Feature Extraction, and this can become super complex to handle. So context matters, are your engineers comfortable enough with geometry? With deep learning? Or are they mainly sticking to basic pattern recognition and classification tasks?
So what's being done today in research? Let me show you...
Example 1: Late-To-Early Fusion by Waymo
In Late 2023, Waymo unveiled a new paper they named LEF: Late-To-Early Temporal Fusion for LiDAR 3D Object Detection; and this mixes both early and late fusion together. Now this is state of the art!
Here is what it looks like:
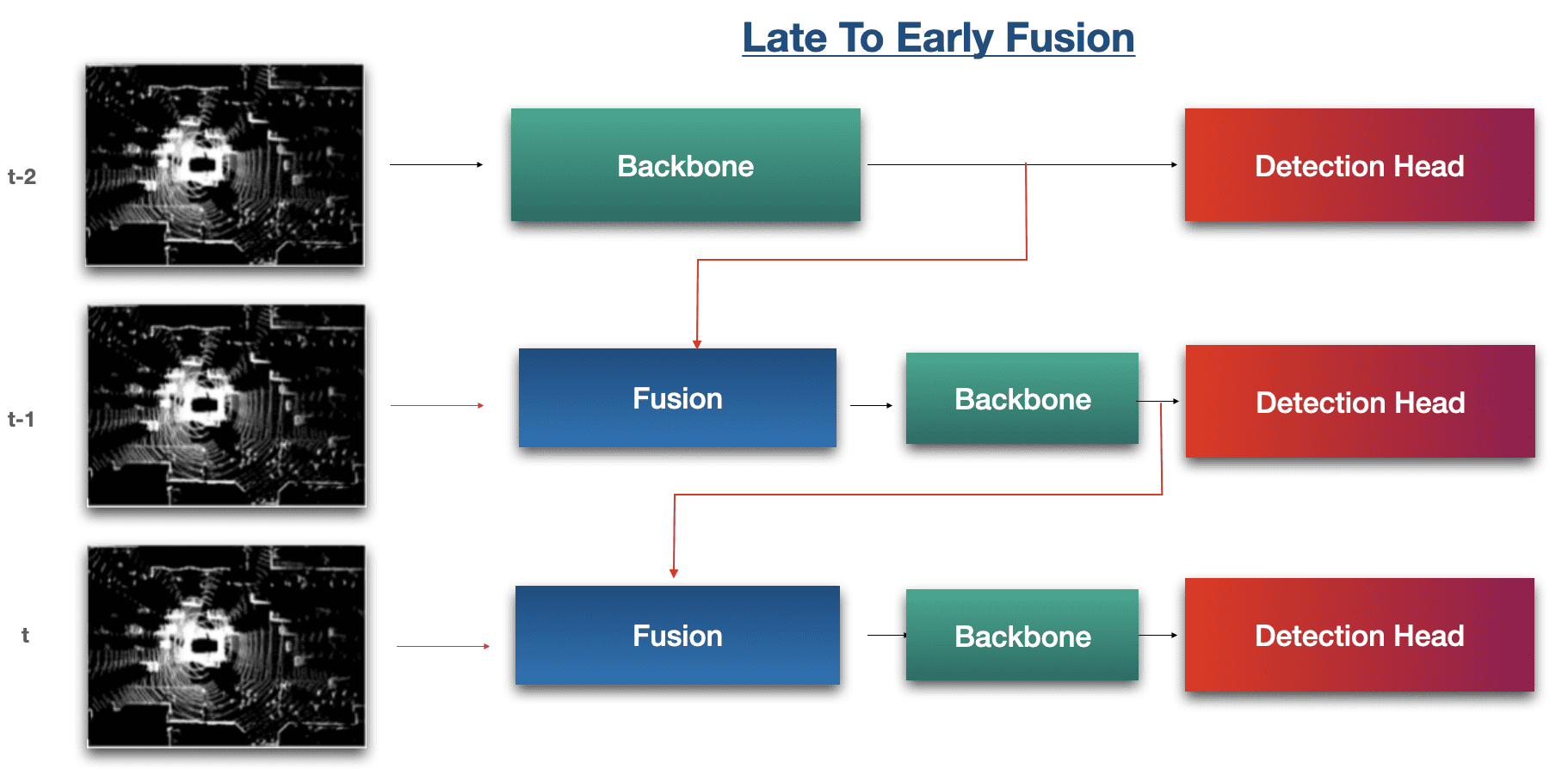
You can find my complete explanation of this architecture in the video:
<iframe src="https://www.linkedin.com/embed/feed/update/urn:li:ugcPost:7167898277210738688" height="896" width="504" frameborder="0" allowfullscreen="" title="Embedded post"></iframe>The highlights:
- Early-to-early: we fuse raw data (t-1) with raw data (t)
- Late-to-late, we fuse backbone (t-1) with backbone (t)
- Late-to-early, we fuse backbone (t-1) with raw data (t)
In this same idea, we could see the Early-To-Early Fusion, but this time done temporally:
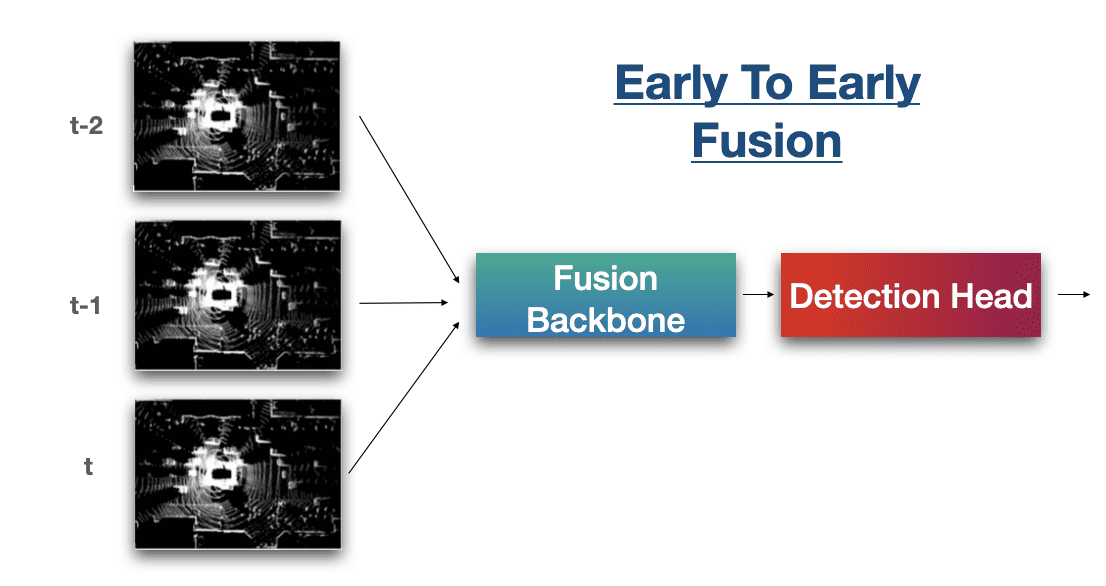
Example 2: Aurora's Deep Fusion Architecture
I've written an entire article on Aurora's sensor fusion algorithms already, and I've used the example so much that I feel like it's been overdone. Yet, I believe it's the most representative fusion out there:
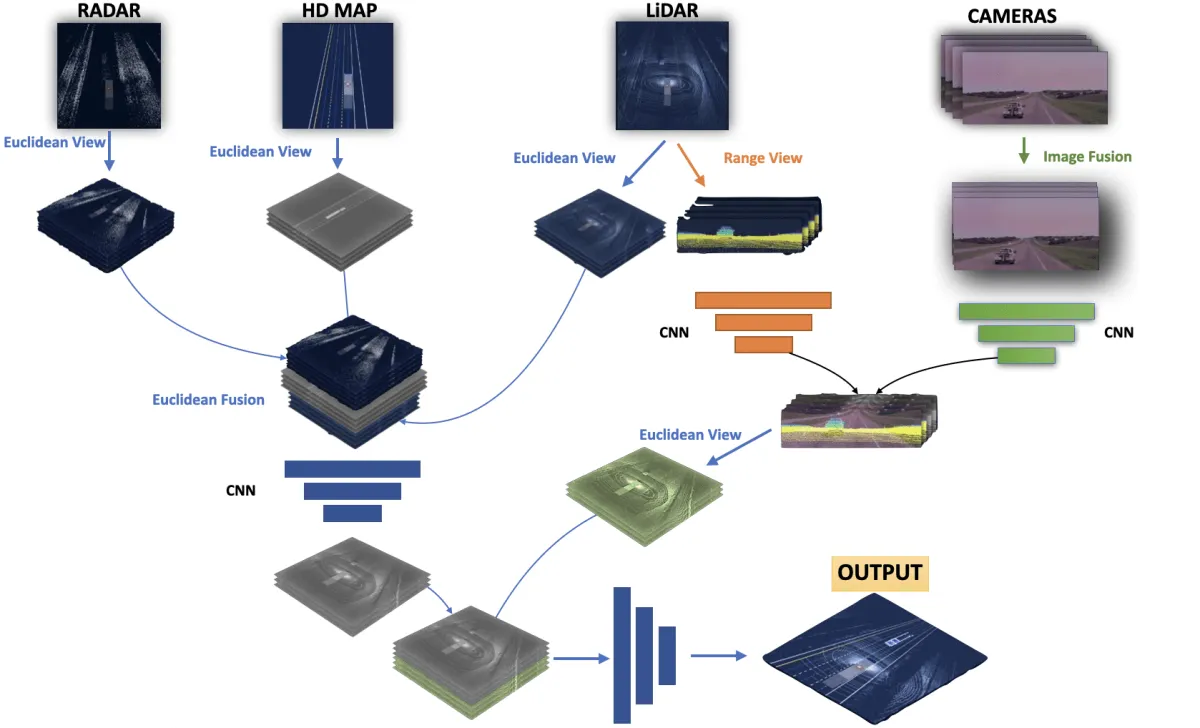
The highlights:
- "Euclidean View" means Bird Eye View
- "Range View" is the 2D LiDAR view we mentioned before
- Fusion is done using RADAR, HD MAP, LIDAR, and multiple cameras
I highly invite you to read my post on it here to understand it better.
Alright, let's summarize:
Summary
- When using multiple sensors, we have many different options as to "when" we want to fuse them. It could be at the data level, which would be called early fusion, or at the feature level, which would be called mid-fusion, or at the object level, which is late fusion.
- Early fusion involves merging the data before you even process them. You can do this via projections from one frame to another (for example point clouds to image space); or by using neural networks.
- The classical way (projections) involves geometry and formulas. It can be very reliable, but highly depends on your sensors and how they're calibrated. They're also involving you're "losing" a dimension, because projecting 3D points to 2D means you're now working in 2D.
- The Neural Network way can feel more complex. In practice it involves merging data via concatenation layers, and then using the merged information. However, most researchers prefer to do feature extraction first, or fuse range views, and then fuse the sensors in the Bird Eye View space (mid-fusion).
- Neither Early nor Late Fusion is better than the other; it's very dependent on context. Easier problems can be solves with Late Fusion, while others could try both approaches. Late Fusion has the drawback of being highly dependent on the sensors and the detection algorithms.
Next Steps
If you've enjoyed this article on Early Fusion, you're probably going to LOVE my article on Bird Eye View Fusion! It's all about how to fuse points and pixels in the Bird Eye View space, which I refer to as Mid-Fusion.
More important next step?
You can get access to the recording here and continue your adventure with me!