Breakdown: How Tesla will transition from Modular to End-To-End Deep Learning
December 2022, Tesla Headquarters, Palo Alto...
During a meeting, an Autopilot Engineer named Dhaval Shroff pitched a new idea to Elon Musk:
"It's like Chat-GPT, but for cars!!!" "Instead of determining the proper path of the car based on rules, we determine the car's proper path by using neural network that learns from millions of training examples of what humans have done."
Convinced, Elon Musk and the entire Autopilot team rushed into applying a new algorithm to the next FSD Version (from FSD v11 to FSD v12).
And that was the beginning of End-To-End Learning at Tesla...
In this post, we're going to do a breakdown of how Tesla plans to migrate from its current architecture to a full end-to-end one. And for this, I'm going to cover 3 key points:
- Tesla in 2021: Introducing the HydraNets
- Tesla in 2022: Adding an Occupancy Network
- Tesla after 2023: Transitioning to End-To-End Learning
These 3 points will matter, especially because you'll notice how they've actually been ready for End-To-End for a long time.
So let's begin with #1:
Tesla in 2021: Introducing the HydraNets
When it started, Tesla's autonomous driving system relied on a Mobileye system for its Perception module. Quickly, it went to a custom built system, going from rasterization of images, to Bird-Eye View Networks, and at some point, they introduced a multi-task learning algorithm called the HydraNet.
The goal of the HydraNet is to have one network with several heads. So, instead of stacking 20+ networks, we have just one, and don't repeat many encoding operations.
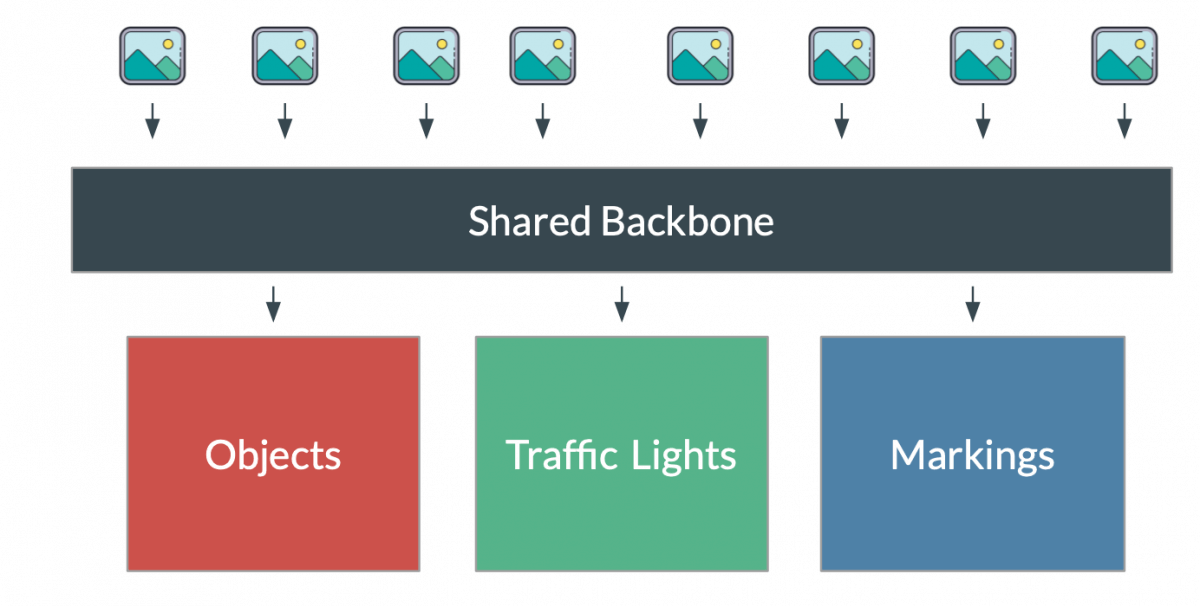
This model has been a key element in the Tesla's architecture, because it allowed them to run multiple tasks using a single neural network.
Yet, it's worth reminding that this was just one component (the Perception component) of a larger modular architecture made of several blocks. Back when they explained it, they mentioned 2 main blocks:
- Perception, used to detect objects and environment with the HydraNet
- Planning & Control, used to plan a route and drive
Perception & The HydraNet
So the HydraNet is similar to what I just showed. I have an entire post on it on my dedicated article, and even an entire course just on multi-task learning and how to build these models on Computer Vision.
So let me quickly move to the next part:
Planning & Control: How Tesla Autopilot plans a route to destination
At AI Day 2021, Tesla introduced 3 types of Planning systems, and showed the example they ran on an autonomous parking example:
1) The Traditional A* Algorithm — known by every robotics engineer as the "key" algorithm in search. This example shows nearly 400,000 "expansions" before finding the correct path.
Video of the Original A* Algorithm for Search takes around 44,000 nodes to compute (source: AI Day 2021 Video)
2) The A* Algorithm, enhanced with a Navigation route — This approach is the same one, but rather than a "heuristic" given, we give more inputs (the map? the routes? the destination?). This leads to only 22,000 expansions.
Video of the A* Algorithm, enhanced with Navigation information takes only 22k nodes (source: AI Day 2021 Video)
3) A Monte-Carlo Tree Search Algorithm, enhanced with a Neural Network — This approach is the one used by Tesla in 2021. By combining a Neural Network, with the traditional tree search, it can reach the objective with less than 300 nodes.
Video of the Tesla Planning Algorithm in 2021 is super fast thanks to a Neural Network + Monte Carlo Combo (source: AI Day 2021 Video)
This last approach is the one they're using for Planning.
Summary of Tesla in 2021
So let's do a quick recap of 2021:

We have 2 main blocks: The HydraNet doing the vision task, and the Monte-Carlo combined with a Neural Network to do the planning task.
Now let's move to 2022, and see how both Perception and Planning evolved...
Tesla in 2022: Introducing The Occupancy Networks
In 2022, Tesla introduced a new algorithm they call the Occupancy Network. Thanks to the Occupancy Network, they've been able to not only improve perception, but also highly improve planning.
When I first talked about this idea, many people told me "So they're no longer using HydraNets!".
Well, they are!
What Tesla did in 2022 is to 'add' an occupancy block to Perception, so they divided the Perception module in 2 blocks:
- The HydraNet, finding objects, signs, lane lines etc...
- The Occupancy Network, finding the occupancy in 3D
So let's see these 2:
The Occupancy Network
Let's begin with the Occupancy Network.
In my article on Occupancy Networks, I talked about how Tesla has been able to create a Network that converts the image space into Voxels, and then assign a free/occupied value to each.
This enhances the perception block, helping them find more relevant features too. This has been a really great improvement to their stack, as it allowed them to add a great context understanding, and this especially in 3D.
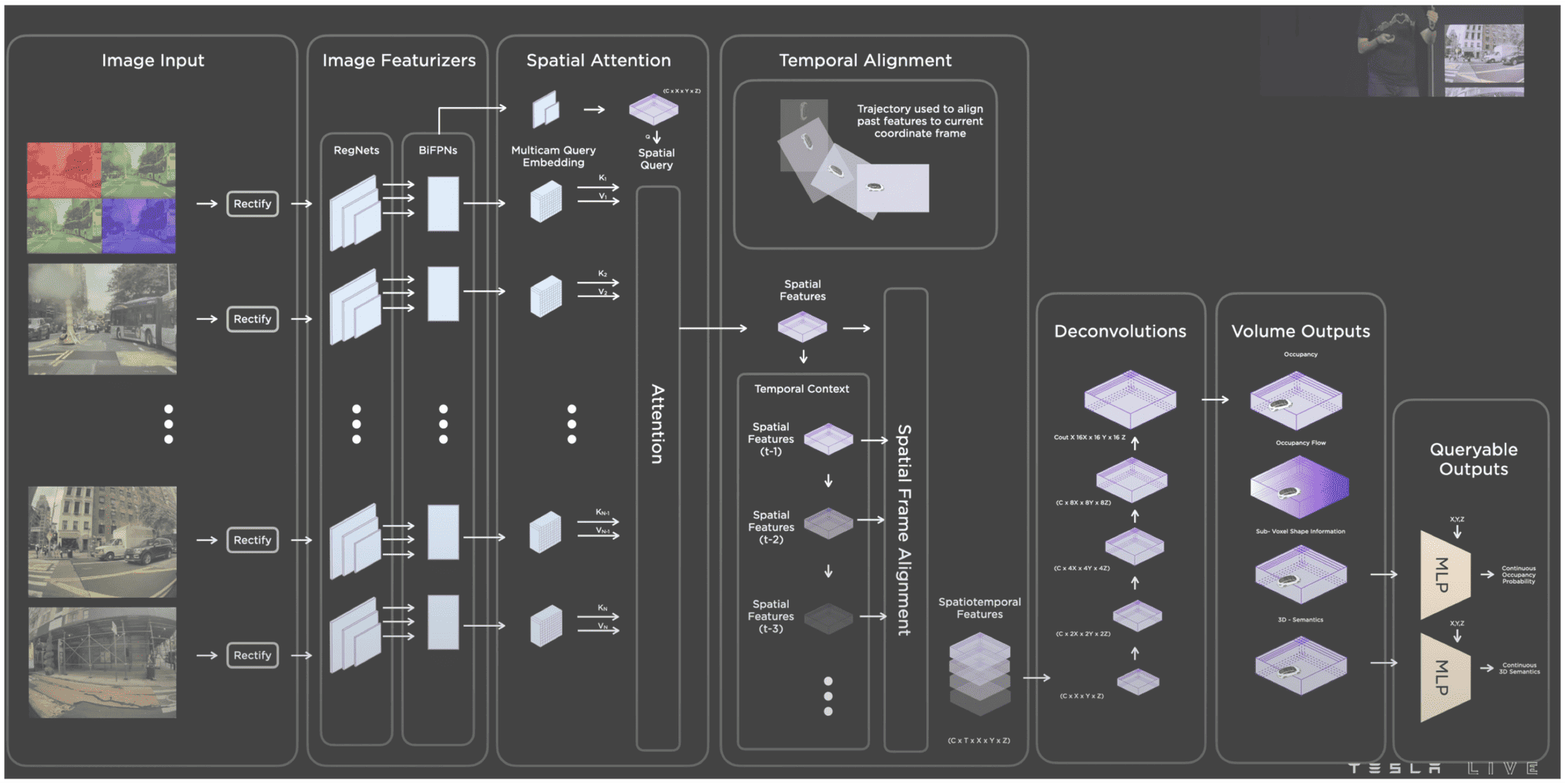
This Occupancy Network is predicting the "Occupancy Volume" and "Occupancy Flow" — 2 important pieces, that help us understand what's free and what's occupied in the 3D space. If you want to understand it better, you can read my article.
But it's not the only thing used, it's an additional piece, to understand 3D better, the objects and lanes are also detected with the HydraNet.
The HydraNet 2.0: Lanes & Objects
The HydraNet isn't much different than last year, except that it has an additional "head", that isn't really a head, but a complete Neural Network doing a lane line detection task.
The overall architecture looks like this (heads in red):
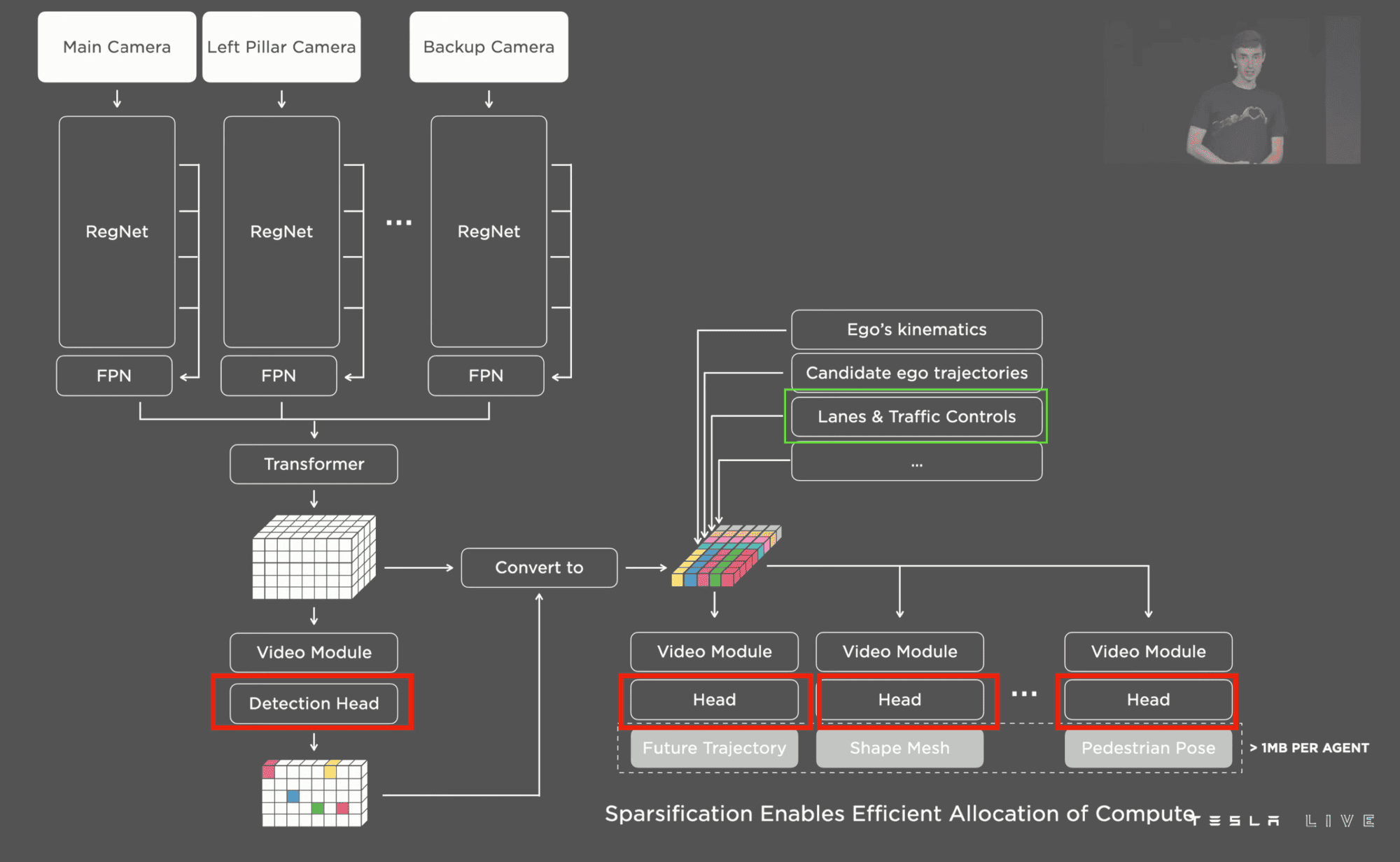
Now, one part of the architecture (in green) is actually another Neural Network stacked here to find the lane lines. When looking at it, it looks like this:
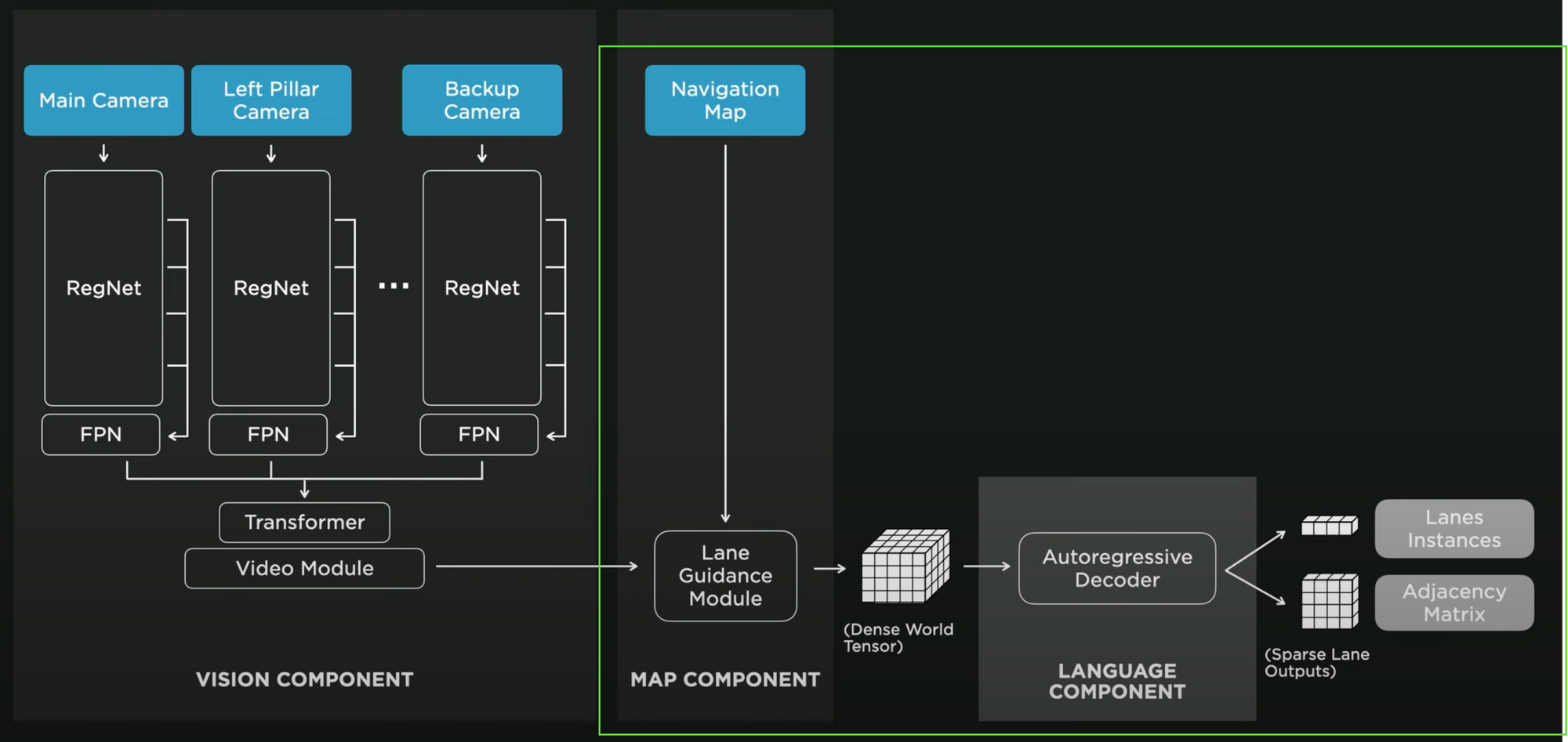
I want to stay "high level" in this article, so I won't dive into how they steal from natural language processing and use semantics etc... to determine lanes, but do you see how the left part is the same as on the above image? It's all a HydraNet, and the right part is just an additional part for lane line detection.
So, this is for Perception, we have:
- An Occupancy Network, doing 3D understanding
- A HydraNet, doing lane & objects understanding
Now let's see Planning:
The New Tesla Planner
The original Neural Network planning was great, but now that we get access to the Occupancy in 3D, we should use it! So, the new planning module integrates the Occupancy, as well as the lanes, into (still) an architecture made of a Monte-Carlo Tree Search & a Neural Network.
To understand the logic of the Tree, let's take the example Tesla gave at their AI Day 2022:

In this example, the vehicle has to:
- Yield to the pedestrian crossing illegally
- Yield to the car coming from the right
And, so, it build a tree structure, where it will generate and evaluate exactly these choices.
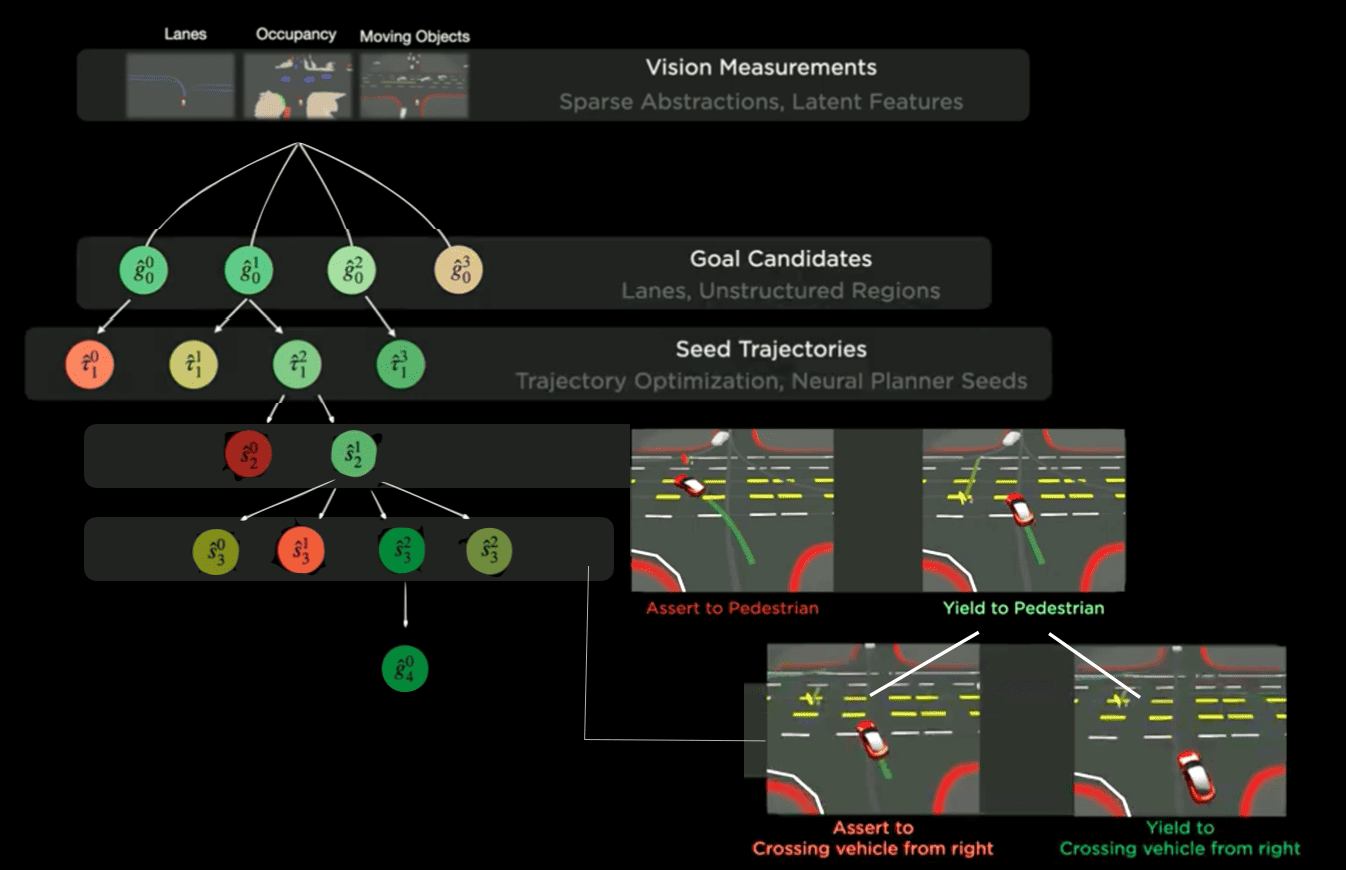
From top to bottom:
- Step 1: We start with the vision measurements (lanes, objects, and occupancy)
- Step 2-3: We then generate goal candidates and trajectories
- Step 4: We evaluate the first choice: pedestrian yield vs assert
- Step 5: We evaluate the second choice: Right car yield vs assert
How do we evaluate these choices? We have manual rules and criterias for this. After we've generated trajectories, each of these will have a cost function, that will depend on 4 factors: the collision probability, the comfort level, the intervention likelihood, and the human-likeness.
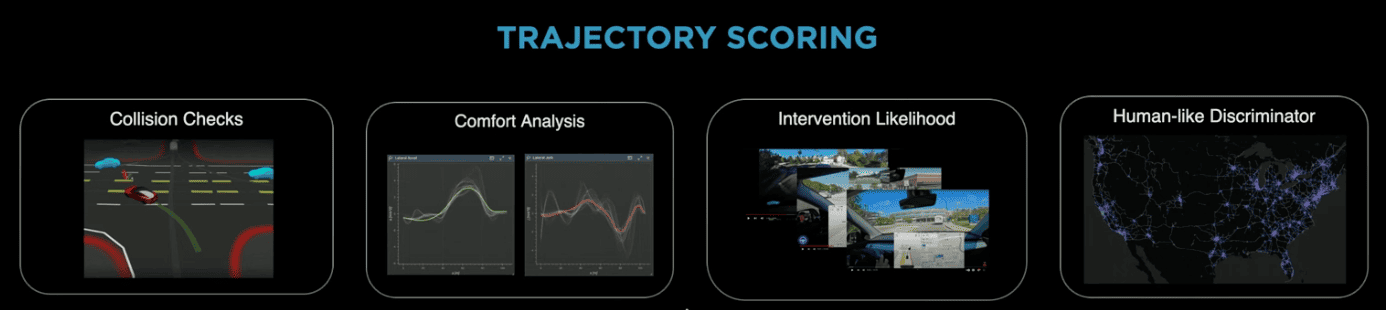
So, if you have 20 trajectories generated, each of them has a cost function, and you end up picking the lowest cost function.
Again, this is all "manually" done. To my knowledge, there are no machine learning models or deep neural networks used, no training data — we really write rules and algorithms.
So let's see a quick summary of what we have:
Tesla in 2022: Summary
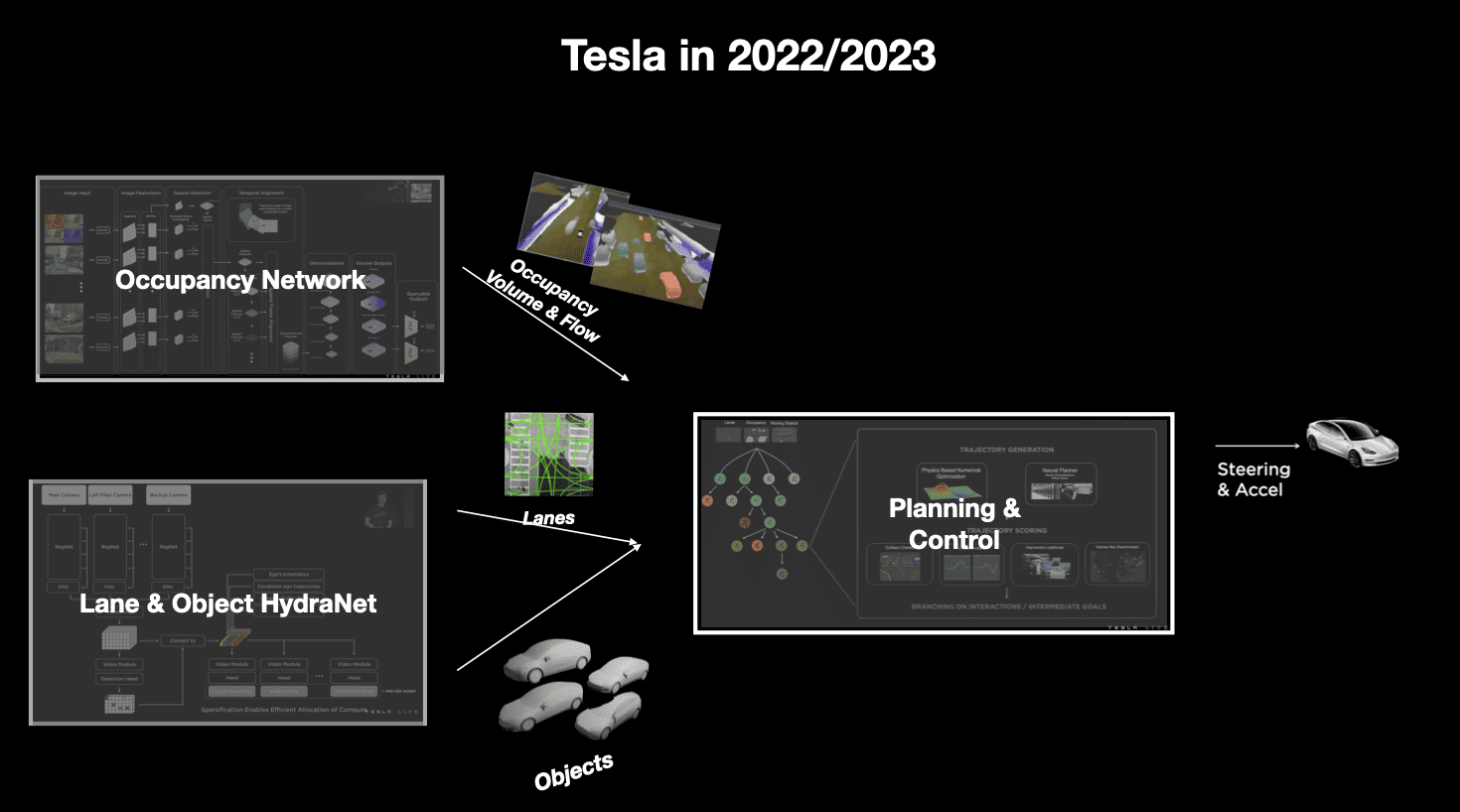
We have 2 key components:
- The Perception has been enhanced with Occupancy Networks and Lane Detection
- The Planner has been rewritten to use the Occupancy Networks outputs
So you can see how the input data (8 images) flows from Perception to Planning, to the output.
Now, let's see what they want to do for 2023/2024:
Transitioning to FSD v12 and the End-To-End Architecture
What does End-To-End Deep Learning mean? And what "changes" to this architecture will it require?
If we google "end to end learning definition", this is what we got:
"End-to-end learning refers to training a possibly complex learning system by applying gradient-based learning to the system as a whole. End-to-end learning systems are specifically designed so that all modules are differentiable."
So, in a nutshell, Tesla has 2 things to do:
- A Deep Neural Network for every block
- An End to End Model, assembling these neural networks together
Currently, for Tesla:
- Perception uses Deep Learning ✅
- Planning uses a combo of a Deep Learning model + a traditional Tree Search ❌
And this is this Planning part that they'll need to turn into a Deep Learning part. They'll have to get rid of the trajectory scoring, the manual rules, the code saying "if you're at a stop sign, wait 3 seconds", and the code saying "if you see a red light, slow down and break.". All of it is gone!
So, here is what it'll look like:
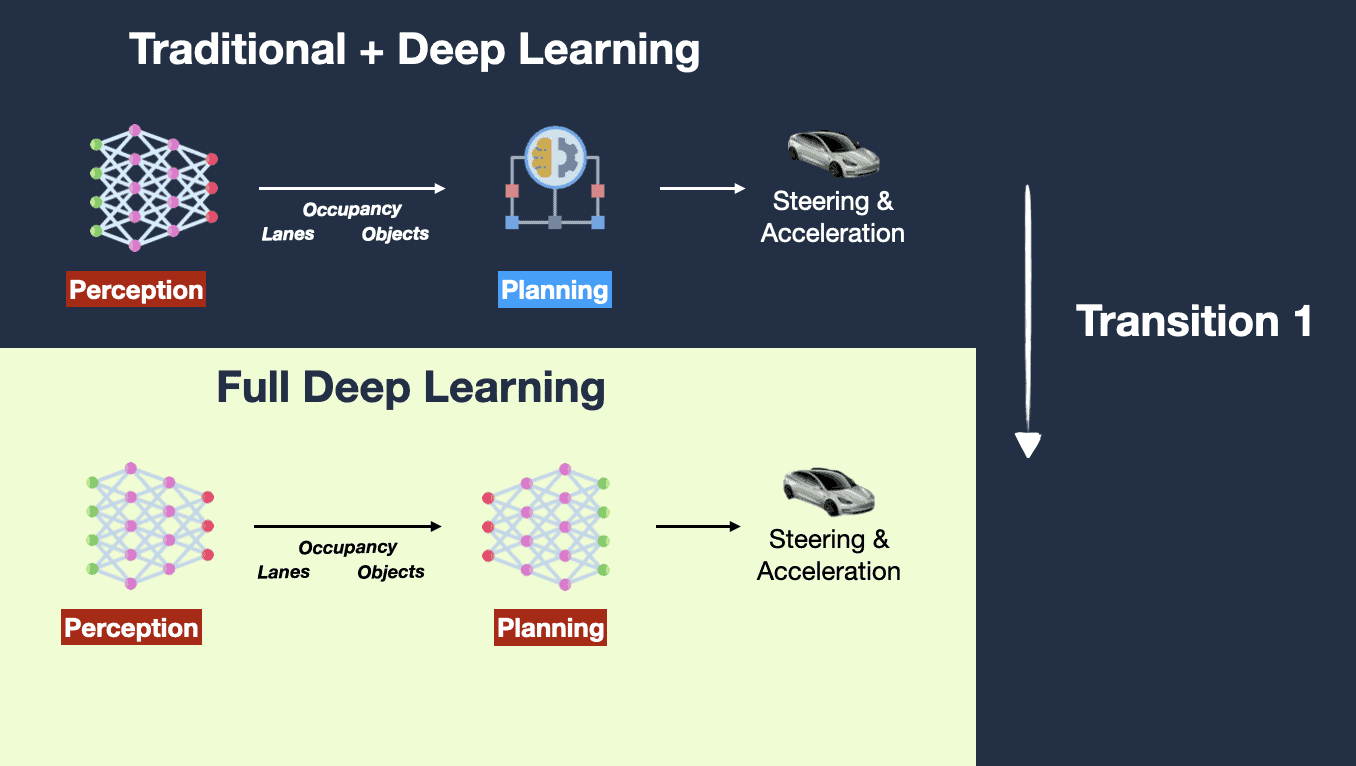
Yet, it won't be enough, because if we may have 2 Deep Learning blocks, but still need an End-To-End operation. So there's full Deep Learning, and there's End-To-End.
In a non-end-to-end, yet full Deep Learning setup:
- You train Block A independently on a dataset to recognize objects.
- You then train Block B independently, using the output from Block A, to predict a trajectory.
Key point: During training, Block A does not know anything about the objectives of Block B. And Block B is also unaware of Block A's objectives. They are two separate entities trained independently, and their training loss is not jointly optimized.
Now consider an end-to-end setup with the same Blocks A and B.
- You have a single objective function that considers both recognizing the objects in the image (Block A's task) and predicting the trajectory (Block B's task).
- You train both Block A and Block B together to minimize this joint loss.
Key point: Information (and gradients during backpropagation) flows from the final output all the way back to the initial input. Block A's learning is directly influenced by how well Block B performs its task, and vice versa. They are jointly optimized for a single, unified objective.
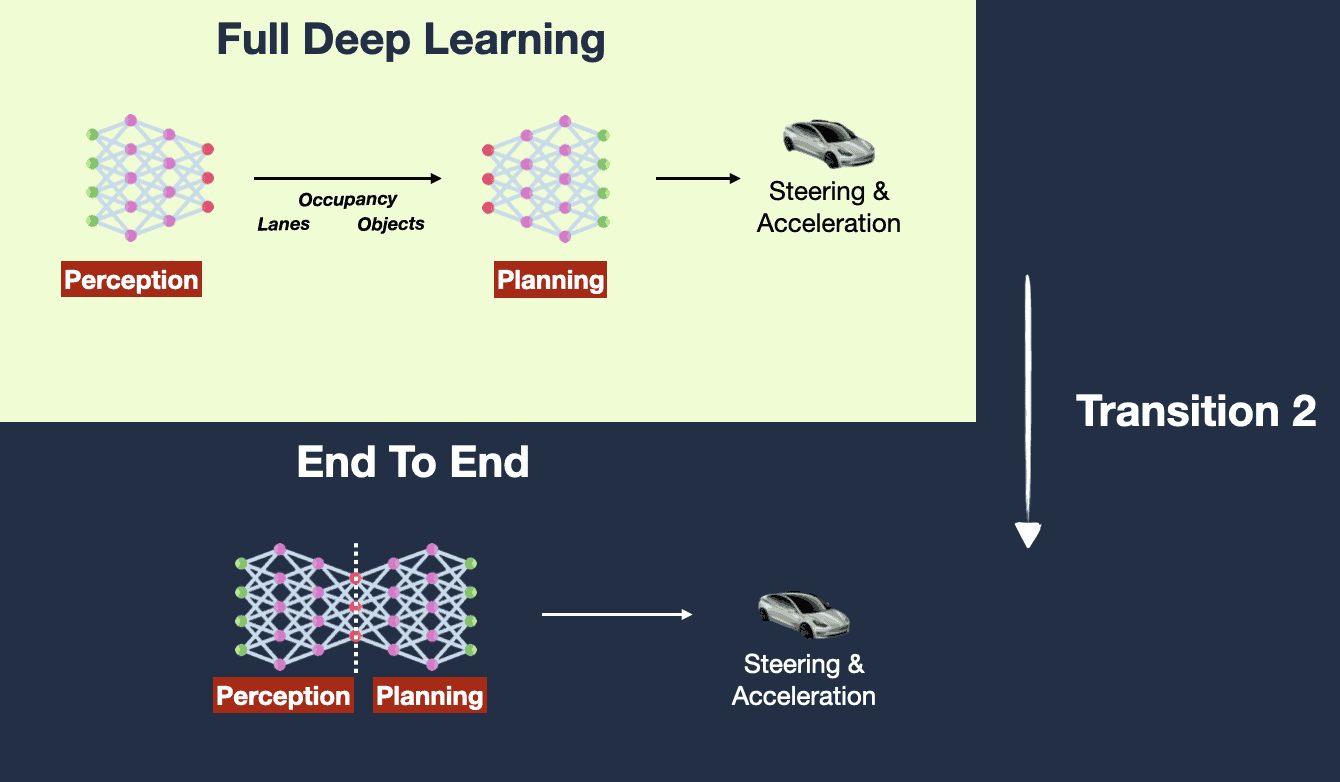
So, the main difference is not in the blocks themselves but in how they are trained and optimized. In an end-to-end system, the blocks are jointly optimized to achieve a single overarching goal. In a non-end-to-end system, each block is optimized individually, without consideration of the larger system's objectives.
Wait: Isn't it more of a Black Box now? How do we even validate this thing and put it on the road?!
Hey, I'm just the messenger here.
But yes, it can seem more of a Black Box, but you can also see how we're still using Occupancy Networks and Hydranets and all of these, we're just assembling the elements together. So, it's a Black Box, but we can also, at any point in time, visualize the output of Occupancy, visualize the output of Object Detection, visualize the output of Planning, etc...
We can also train these elements separately, and then finetune in an End-To-End way. So, it's a Black Box, but not necessarily more than it already was. There's just one additional level of complexity: the overall training.
For validation, and anything like this, I'm not the right person to ask. Tesla is not the only company doing End-To-End, there is also Comma.ai with OpenPilot, and Wayve.ai.
Now — something important notified by Elon Musk is that using an End-To-End approach, we no longer "tell" the vehicle to stop at red light, or at stop sign, or to verify xyz before changing lanes...
The vehicle figures it out on its own by "imitating" the drivers from the 10M videos they used. So, this means they've been using a dataset of 10M videos, they graded the drivers on each of these, and they trained the machine to imitate what the "good drivers" were doing.
This can be huge in theory, because it would mean the models could generalize much better when facing unknown scenarios — it would simply find the closest behavior to adopt in its training, rather than staying stuck.
Video of the Livestream from Elon Musk
You can watch the livestream where they first demo-ed it here. And yes, there is a disengagement towards 20:00.
— Elon Musk (@elonmusk) August 26, 2023
It's now time for a summary...
Summary
- Up to now, Tesla is using a modular approach to autonomous driving, with 2 main blocks communicating together: Perception & Planning.
- In 2021, they introduced the HydraNet, a multi-task learning architecture capable to solving many Perception tasks all at once.
- They also announced their Planner to be an assembly of a Monte Carlo Tree Search, and a Neural Network.
- In 2022, they added an Occupancy Network, which helps with better 3D understanding. The HydraNet also had an extension for lane line detection.
- To transition from their current system to End-To-End, they will need to (1) turn the Planner into a Deep Learning system, and (2) train these with a joint loss function.
- The system may look like a blacker box, but it's actually an assembly of existing blocks — they won't get rid of everything they've already built, simply glue them together.
Next Steps
If you liked this article, then I invite you to read these 3 related articles, on Tesla and architectures:
- Tesla's HydraNets: How Tesla Autopilot Works
- A Look at Tesla's Occupancy Networks
- 4 Pillars vs End To End: How to Pick an Autonomous Vehicle Architecture