

Stereo Vision vs Sensor Fusion - Which approach is better?
Would you use Stereo Vision or Sensor Fusion to detect an obstacle in 3D?
In the self-driving car world; there is an old debate about Stereo Vision versus LiDAR. Some companies, such as Tesla or Comma.ai, bet everything on Computer Vision. To them, human vision works with two eyes , and there is no reason for a car to drive differently than using a minimum of two cameras. Other companies want to rely on LiDARs, and use Sensor Fusion with the camera.
Interested in this comparison, I took a self-driving car recording and created code for the two approaches.
👉 My goal was to find the obstacle and its distance to the car in this image.

The image is comming from the KITTI VISION BENCHMARK SUITE, where the car has been equipped with a Velodyne HDL-64E LiDAR and four Point Gray cameras from FLIR.
Before showing you the results, and determining who is right about this topic, please note that I have published articles and courses on both approaches in detail.
- If you're interested in more details about How Stereo Vision works, here 's an article for you and here is my course MASTER STEREO VISION: Killer Approaches to pseudo-LiDARs & 3D Computer Vision .
- If you're interested in more details about how Sensor Fusion works, here's the article discussing LiDAR and Camera fusion.
Now, let's start with Stereo Vision.
Stereo Vision
fusion of two images.find the Stereo Disparity matching algorithms
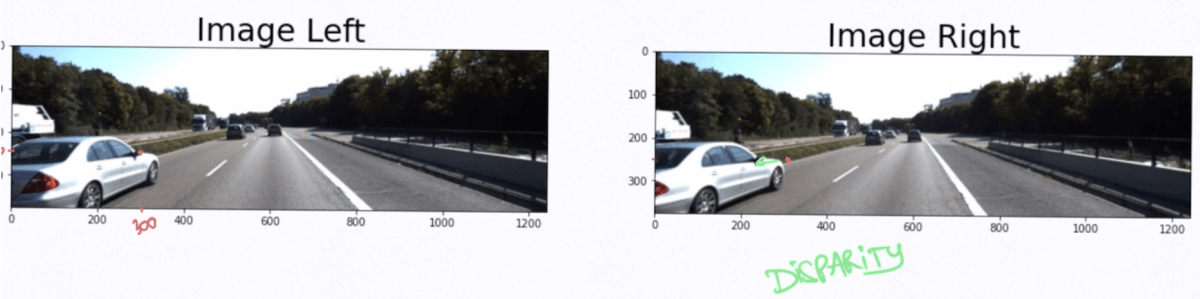
From there, we are able to use calibration and geometry to build a depth map. The depth map gives the depth of each pixel. An object detection algorithm then helps to find which pixels are interesting to us, and we correlate that with the depth map.
I like when things are visual, so here's the drawing.
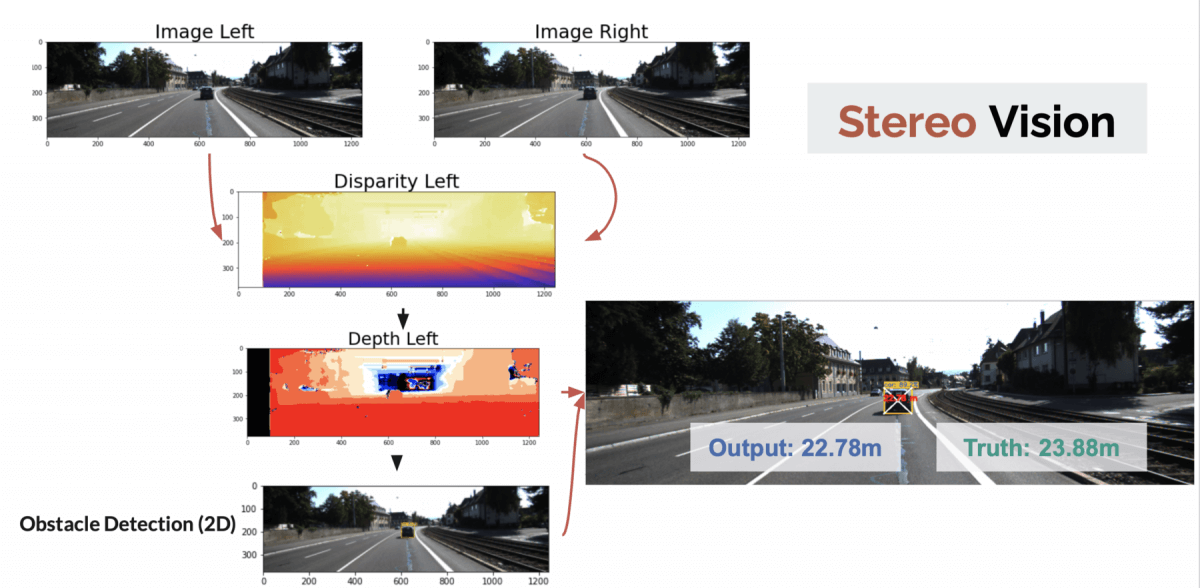
👉 To get the distance, I'm taking the depth of the center of the bounding box. The object is detected using a Tiny YOLOv4 algorithm, and is estimated at 22.78 meters.
Error: 1.10 meters
➡️ For an algorithm that had almost no optimization, it's pretty good!
LiDAR/Camera - Sensor Fusion
LiDAR Detection and Sensor Fusion is different; we want to use the camera and the LiDAR to detect the obstacle's class, and it's distance. In this example, we'll be using a low level sensor fusion technique, also called early fusion .
Instead of using two images, we'll simply use one image, and the point clouds. We'll then project the points clouds on the image, detect obstacles, and take the values of the points inside the bounding boxes.
Here's the drawing showing that:
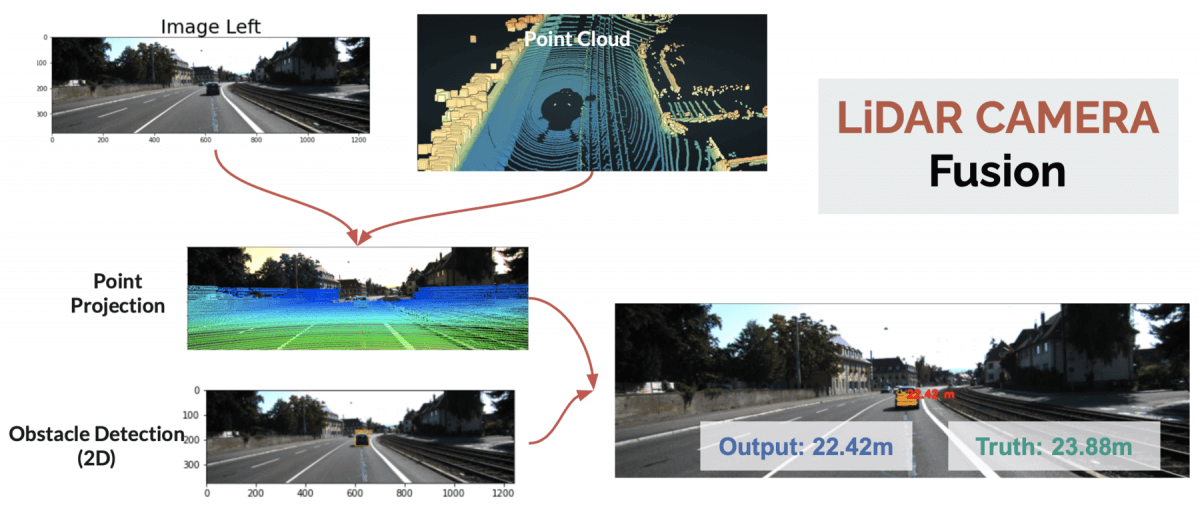
👉 To get the depth, I'm taking the Z value of the closest pixel inside the bounding box. The object is detected using a Tiny YOLOv4 algorithm, and is estimated at 22.42 meters.
Error: 1.46 meters
Results - Which approach is better?
- The ground truth distance was 23.88 meters.
- The Stereo Vision technique got 22.78 meters.
- The Sensor Fusion technique found 22.42 meters.
For this particular example, we can see that the Stereo Vision approach is the closest to the ground truth. In many other examples, LiDAR had better results. Also, I haven't compared with the other approach yet, involving Late Fusion, or mid-level sensor fusion!
👉 Is there a correct conclusion to give? What I can tell you is that today, both approaches are incredibly powerful. For the distance estimation problem, stereo vision works just as good as LiDARs.
📩If you're interested in learning how Stereo Vision works, I will be sharing more details about it through the Think Autonomous mailing list where you will receive everyday content about 3D Perception, Sensor Fusion, and in general, how to become a super edgeneer working in the cutting-edge?




