A Look at Tesla's Occupancy Networks
In 2022, Tesla announced a brand new algorithm about to be released in their vehicles. This algorithm is named occupancy networks, and it is supposed to improve the HydraNets from Tesla. But how does it work? Why is it needed?
Let's find out...
Why a new kind of algorithm is needed for self-driving cars
The self-driving car industry is technically divided in two categories: vision based systems, and LiDAR based systems. While the later uses laser sensors to determine the presence of an object, vision systems are purely based on cameras. And this is what Tesla does with their Tesla Vision software; as well as Comma.ai, or other startups.
But vision based systems have lots of flaws, and still face lots of crash caused by object detection failures, or other issues.
What if you see an object that isn't part of the dataset?
In LiDAR based systems, you can physically determine the presence of an object because of particles detected — but in camera systems, you must detect the objects using Neural Networks first.
Lots of accidents have been caused because of this alone.
At CVPR (Computer Vision And Pattern Recognition) 2022, Ashok Elluswamy, the new Tesla Autopilot Head, has introduced a new kind of algorithm named:
Occupancy Networks
And these networks are far better at detecting objects than the usual object detection systems. These aren't the only problems we have with "classical" algorithms, see for yourself:

Notice a few of the problems listed:
- Depth at the horizon is extremely inconsistent, only 2 or so pixels determine the depth of a big region.
- It's impossible to see through occlusions, or drive past vehicles.
- The structure provided is in 2D, but the world is in 3D.
- We don't get overhanging obstacles, we classify and then set fixed rectangles.
- There may be ontology cracks, for example if you see an object that isn't part of the dataset.
Which means we must evolve to a new kind of algorithm:
Occupancy Networks
Occupancy Networks are a different kind of algorithm, based on the robotics idea named occupancy grid mapping; which consists of dividing the world into a grid cell, and then define which cell is occupied and which is free.
The idea of Occupancy Network is to get volumetric occupancy.
Meaning it's 3D.
It's using "occupancy" rather than detection.
And it's multi-view.
So here's what it looks like:

Notice we don't get the exact shape of the object, but an approximation. We can also predict between static and dynamic objects. And finally, it runs at over 100 FPS (or 3x more than the camera can produce). It's therefore super memory efficient.
This network is improving 3 existing ideas implemented in the former Tesla algorithm:
- Bird-Eye-View
- Fixed Rectangles
- Object Detection
Let's see them:
Bird Eye View
The first idea is Bird-Eye-View. At Tesla AI Day 2020, Andrej Karpathy introduced Tesla's Bird-Eye-View Networks (you can learn more about it here). This network showed how to put detected objects, drivable space, and others into a 2D Bird-Eye-View.
What Occupancy Networks do are finding occupancy volumes.
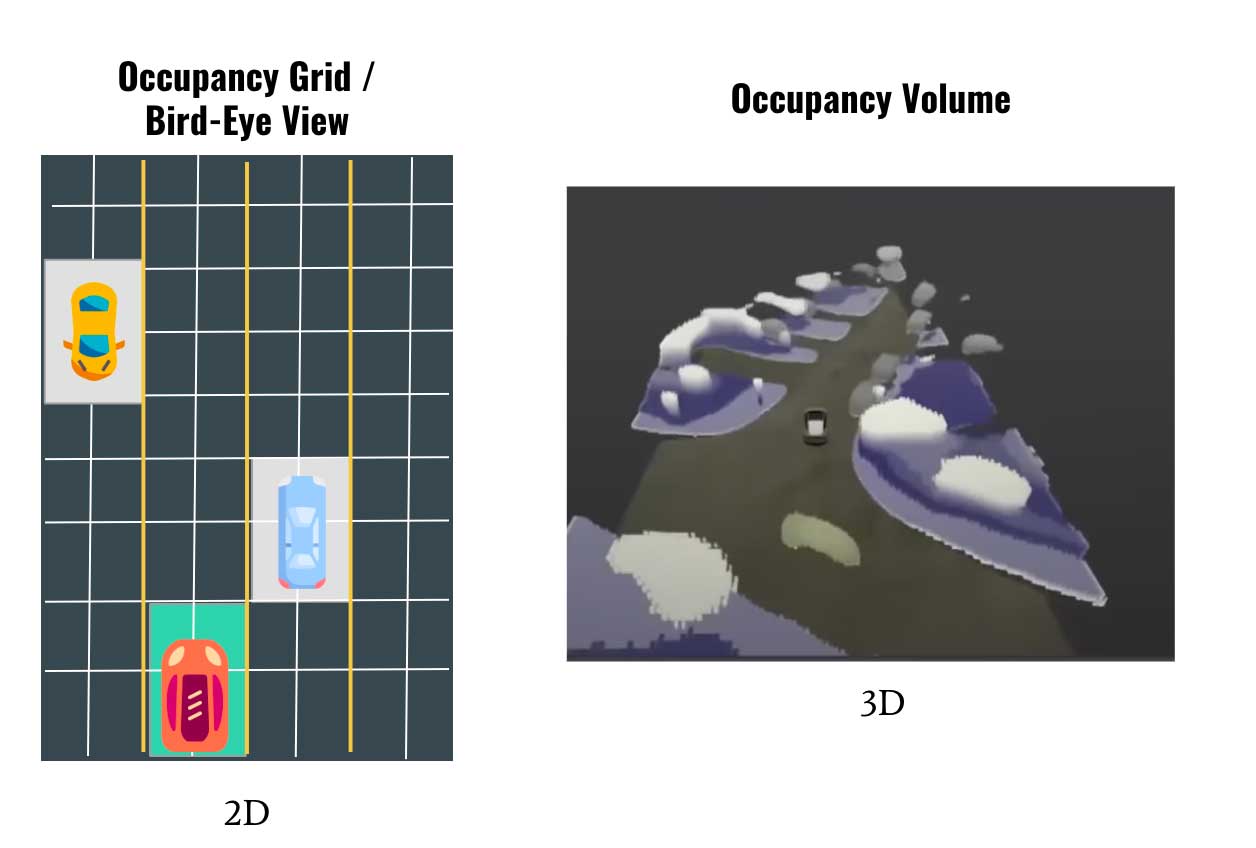
Notice the main difference? One is 2D, and the other is 3D.
And this brings us to the second improvement:
Fixed Rectangles
When designing a Perception system, we often try to link our detections with fixed outputs. If you see a truck, you'll put a 7x3 rectangle, and if you see a pedestrian, you'll just use a 1x1 rectangle in your occupancy grid. The problem is, you can't predict for overhanging obstacles.
If a car has a ladder on top of it, if a truck has a side trailer, or an arm; then your rectangle doesn't work anymore.
The occupancy network here is precise enough to see this:

How is this possible? The way it works is as follows:
- Divide the world into tiny (or super tiny) cubes or voxels
- Predict if each voxel is free or occupied
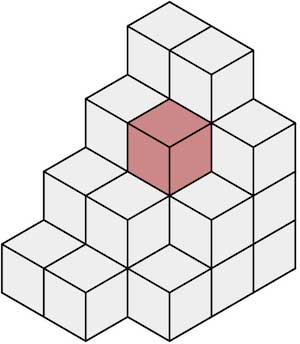
Which means that instead of assigning a fixed size rectangle to an object, we'll simply say "is there an object in this tiny cube?".
To Tesla, the solution to crashes is here: Geometry > Ontology.
Which brings us to the third improvement:
Object Detection
Every year at the Computer Vision And Pattern Recognition conference, a new object detection algorithm is released. A new object detection? No, at least 30+ new object detection research papers are released, detailed, and studied.
But there is a major problem in object detection: it only detects objects that are part of the dataset.
It doesn't really do object detection, because it only detects a specific set of objects. Which means that if you detect something that isn't part of the dataset (a kangaroo?), you will just see nothing. — and crash.
When thinking and training a model to predict "is this cell free or occupied, no matter the class of the object?", you're avoiding this kind of issue.
Here is an example:
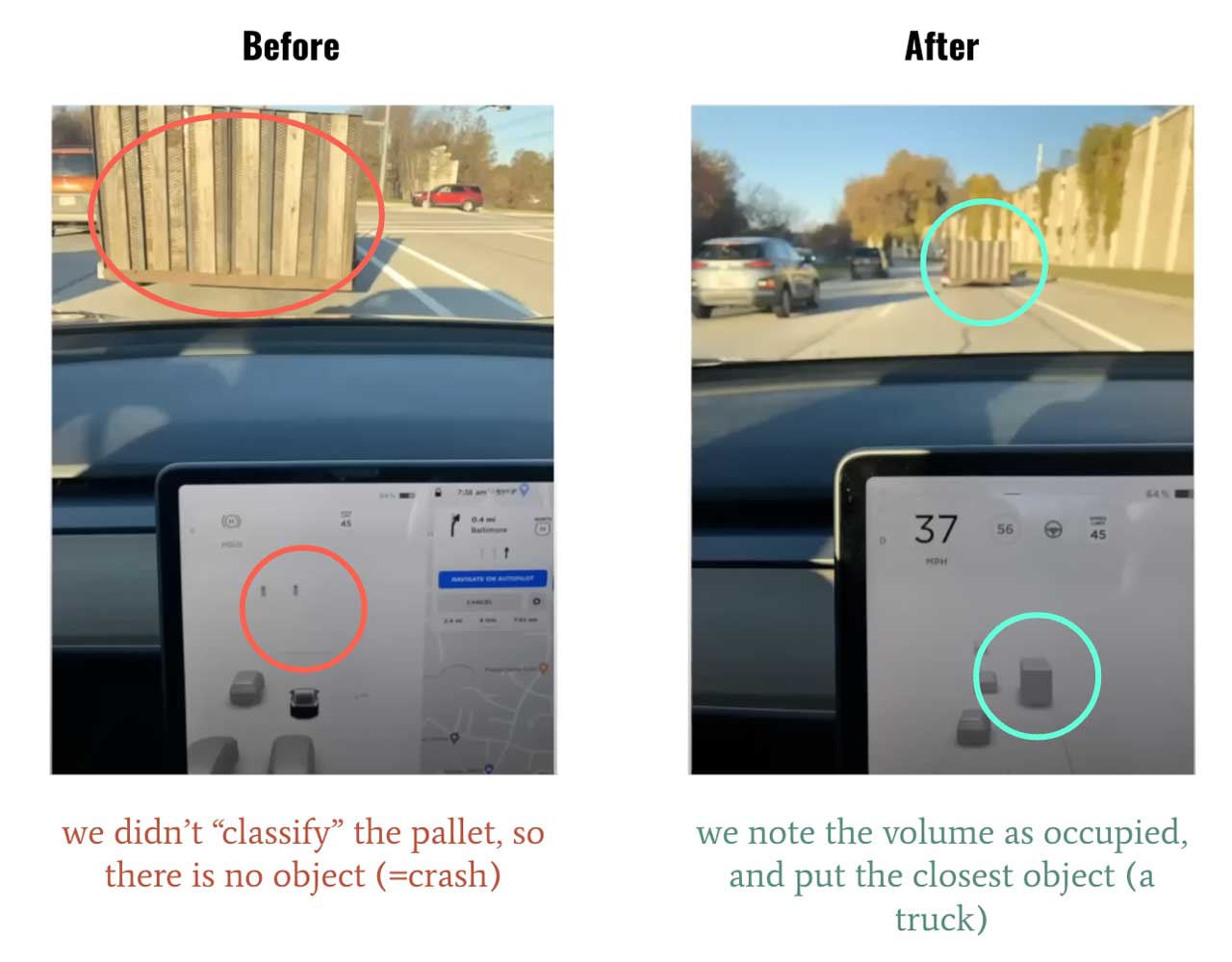
Notice how the pallet is detected on the right, but not on the left because the Tesla dataset doesn't have it.
And this is our 3rd improvement.
To briefly summarize what we learned so far:
- Vision based systems have 5 main flaws: inconsistent depth at the horizon, fixed object shapes, static and moving objects, occlusions, and ontology cracks. Tesla aims to create an algorithm to solve these issues.
- The new occupancy networks fix these problems by implementing 3 core ideas: Volumetric Bird-Eye View, Occupancy Detection, and Voxels Classification.
- These networks can run at over 100 FPS, can understand moving vs static objects and are super memory efficient.
But how do they work?
Let's now study the network.
The Architecture presented at Computer Vision and Pattern Recognition (CVPR) 2022
So let's see the architecture, and comment it from left to right:
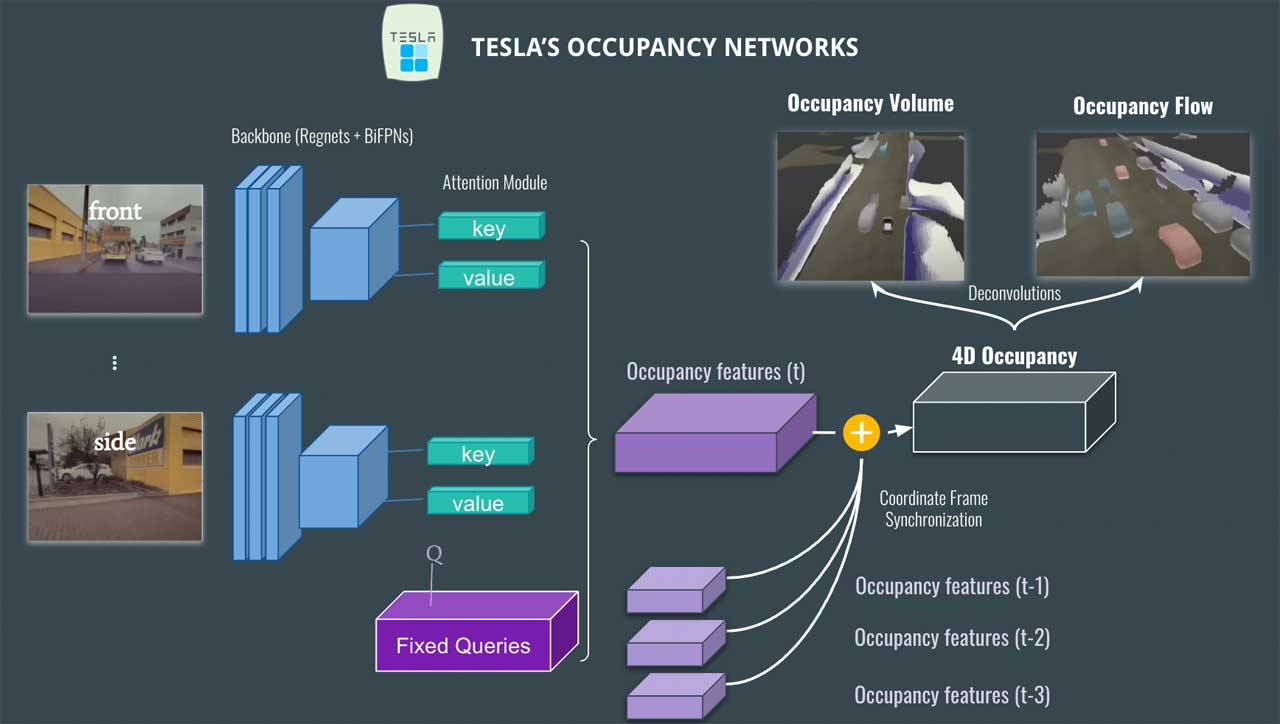
- On the left, you can see Tesla's cameras (8 in total: front, side, rear, etc...).
- First, they're sent to a backbone made of Regnets and BiFPNs; these are state of the art feature extractors in 2022 (and you can swap that with something else if you want to).
- Then, an attention module takes the positional image encoding and uses key, value and fixed queries (car vs not car, bus vs not bus, traffic sign vs not traffic sign) to produce an occupancy feature volume. This is a concept where you need to understand attention.
- This produces an occupancy feature volume, that is then fused with previous volumes (t-1, t-2, etc...), to get a 4D Occupancy grid.
- Finally, we use deconvolutions to retrieve the original size and get two outputs: The Occupancy Volume, and the Occupancy Flow.
You already know about the Occupancy Volume, but what is the Occupancy Flow?
Optical Flow Estimation & Occupancy Flow
What Tesla actually does here is to predict the Optical Flow. In Computer Vision, the Optical Flow is how much a pixel moves from one frame to another. The output is usually a flow map (you can learn how to do that here).
In this case, we have the flow of every single voxel, and thus the movement of every single car; this can be super helpful with occlusions, but also with other problems such as prediction, planning, etc...

The Occupancy Flow is actually showing the direction of each object: red: forward — blue: backward — grey: stationary, etc... (we actually have a colour wheel representing every possible direction).
So this is what's happening here.
It looks like we're done, but there is a final idea implemented called:
NeRFs

Neural Radiance Fields, or NERFs, have recently taken over 3D Reconstruction; and Tesla is a master at this topic. The original idea is to reconstruct a scene from multi-view images (you can learn more about 3d reconstruction in my 3D Reconstruction course).
Wait a minute... isn't it very similar to what we're doing? Using multiple images, and reconstructing a scene?
Yes, this is very similar, but the difference here is that we're doing this also from multiple positions. Driving around a building, we can reconstruct the building. This can be done using a single car, or a fleet of Tesla's driving around a town.
How are these NeRFs used? Mainly for sanity check.
Since our occupancy networks produce 3D volumes, we can compare these 3D volumes with 3D Reconstructed volumes (trained offline), and therefore compare whether our reconstructed 3D scene matches the "map" (the NeRFs produced 3D reconstruction).
A problem can also happen during these reconstructions is blurred images, rain, fog, etc... To solve this, they use fleet averaging (every time a vehicle sees the scene, it updates the global 3D reconstructed scene); and descriptors rather than pixels.

And this is how we have the final output!
These algorithms are currently not in the Autopilot of FSD software, but could be in a very near future! It's state of the art, and doesn't crash. With that, Tesla also announced a new kind of network called Implicit Network, and the main idea is similar: avoid collisions by finding whether a view is occupied or not. More on that in the original video.
Let's summarize!
So let's summarize everything we've learned:
- Current algorithms for vision based only systems have issues: they aren't consistent, they don't do well with occlusions, they can't tell whether an object is moving or static, and they rely on object detection.
- Therefore, Tesla decided to invent the "Occupancy Networks" that can tell whether a cell in a 3D space is occupied or not.
- These networks improve 3 main aspects: Bird-Eye View, Object Ontology, and Fixed Size Rectangles.
- The Occupancy Network works in 4 steps: Feature Extraction, Attention and Occupancy Detection, Coordinate Frame Synchronization, and Deconvolutions, leading to Optical Flow Estimation and Occupancy Estimation.
- Once the 3D volume is produced, NeRFs (neural radiance fields) are used to compare the output with the trained 3D reconstruction scenes.
- Fleet averaging is also used to solve issues such as occlusions, blurs, weather, etc...
I hope this helps — you can learn more on the video from Tesla: