

The 6 Components of a Visual SLAM Algorithm
If you were asked to explain "Chat-GPT" to a friend, how would you do it? The task can seem difficult, there is SO MUCH to tell, to the point where many gave up on the idea of understanding LLMs at all... But what if, instead of trying to understand it, we would reduce it to the following 3 ideas:
- Idea 1: The core architecture is a Transformer Network.
- Idea 2: It's trained on the entire Internet using Self-Supervised Learning and can be fine-tuned on datasets using supervised learning
- Idea 3: The core task is to predict the next word, or token, in a loop.
See? We significantly reduced the problem, now we only have 3 things to understand: Transformers, Self-Supervised Learning, and Next Word Prediction. We may still need a bit more after this, but we will have the gist of it.
Many concepts can seem very abstract at first, but once they're broken down into a few elements, we can suddenly "get it".
Visual SLAM is a similar problem. At first, it can feel very hard to understand; there are all these different types of SLAM algorithms using Kalman Filters, Particle Filters, Graphs, and there is Online vs Offline SLAM, and Loop Closing, and many more...
Once we break it down to simpler concepts, we can understand how it works. In our case, the 3 concepts are going to be following this map I saw in a fantastic research paper on Deep Learning. Here it is:
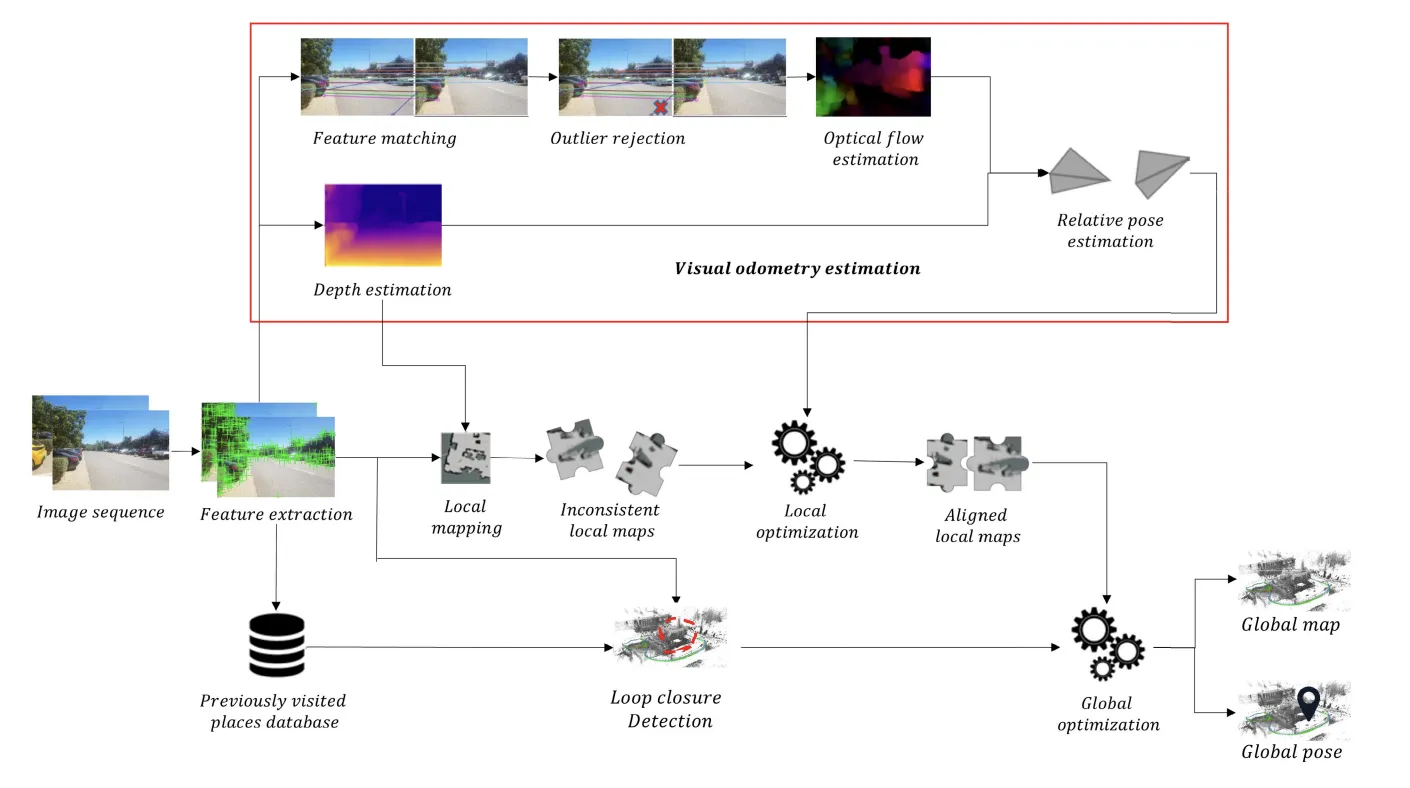
You can see there are many ideas in this workflow, but we can actually reduce it to 3 core parts:
- Feature Extraction & Visual Odometry
- Local Mapping & Optimization
- Loop Closure & Global Optimization
So, let's see these 3 blocks one by one, we'll do two things:
- We'll understand "what" they do
- We'll list the possible algorithms that can work, the "how"
Part 1: Feature Extraction & Visual Odometry
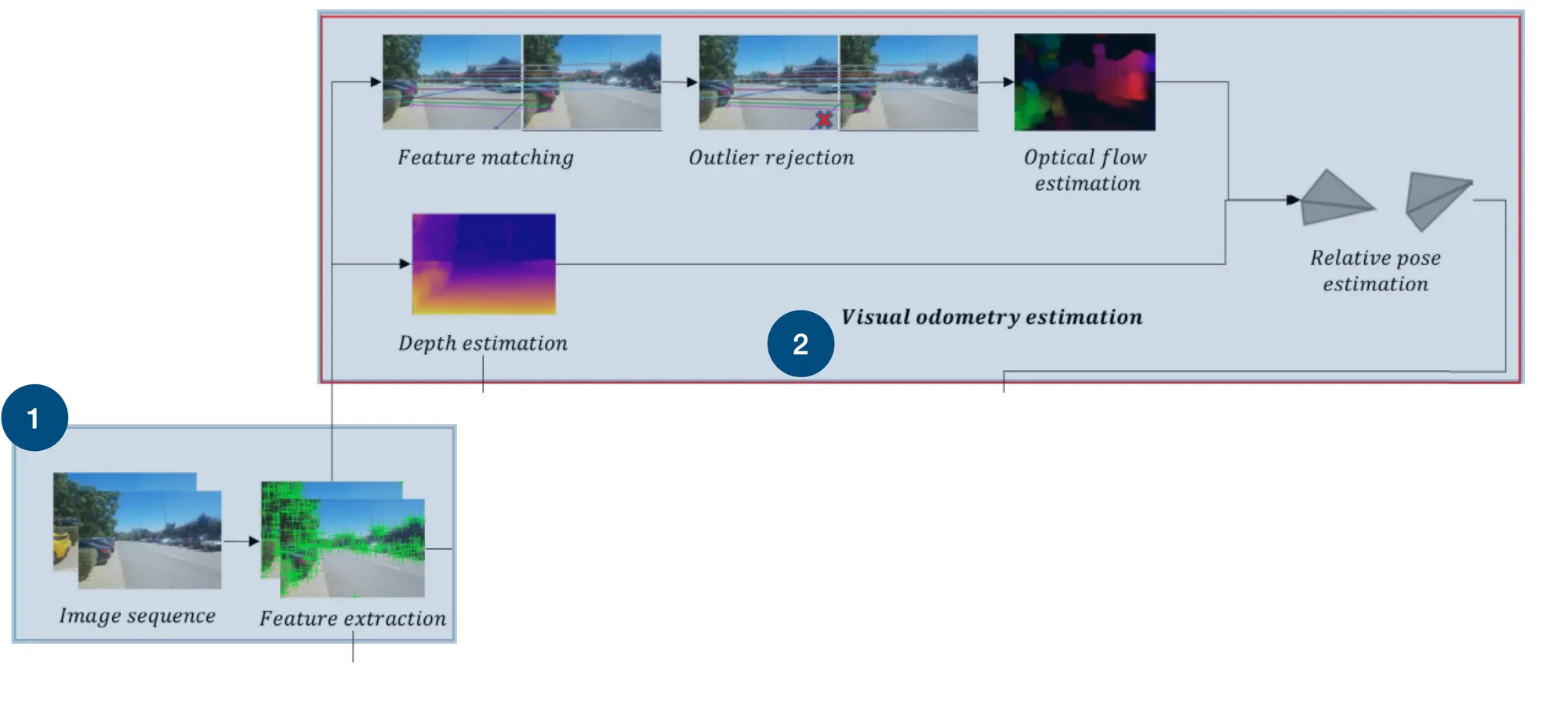
The first thing I would like to talk about are these two little blocks here. One is called "Feature Extraction", and the other "Visual Odometry Estimation".
1 - Feature Extraction
Why feature extraction? And what kind of features are we talking about? The thing to understand is that Visual SLAM works with cameras. Therefore, we don't have a LiDAR. So how could we replace our Point Clouds from LiDARs? We could compute features on images, and then treat them as points!
Therefore, we'll use algorithms to compute Visual Features (edges, corners, gradients, etc...). Below is an image showing the top (visual features) versus bottom (point clouds).

How it works
So now, how does it work? You can learn more about these algorithms for Visual Features on my dedicated article, the gist of finding feature points would be:
- Corner Detectors: FAST (Features from Accelerated Segment Test), Harris corner detector.
- Blob Detectors: SIFT (Scale-Invariant Feature Transform), SURF (Speeded-Up Robust Features).
- Edge Detectors: Canny edge detector.
- Feature Descriptors: ORB (Oriented FAST and Rotated BRIEF), BRIEF (Binary Robust Independent Elementary Features), BRISK (Binary Robust Invariant Scalable Keypoints).
- Deep Learning: Using convolutional neural networks (CNNs) for feature detection and description. I have to say, every brave researcher who has ever tried to replace Visual Features with Deep Learning has FAILED! Don't do this.
Algorithms to check: ORB, FAST, Harris Corner Detector, SIFT, SURF, ...
2- Visual Odometry
The second part is about Visual Odometry. Visual Odometry is the science of calculating how much your car moved based on the visual information. For example, how much did the point clouds move in the last second? How much did the visual features moved?
To achieve this, we have the pipeline that estimates the camera motion by analyzing the changes in the apparent motion of features across a series of images.
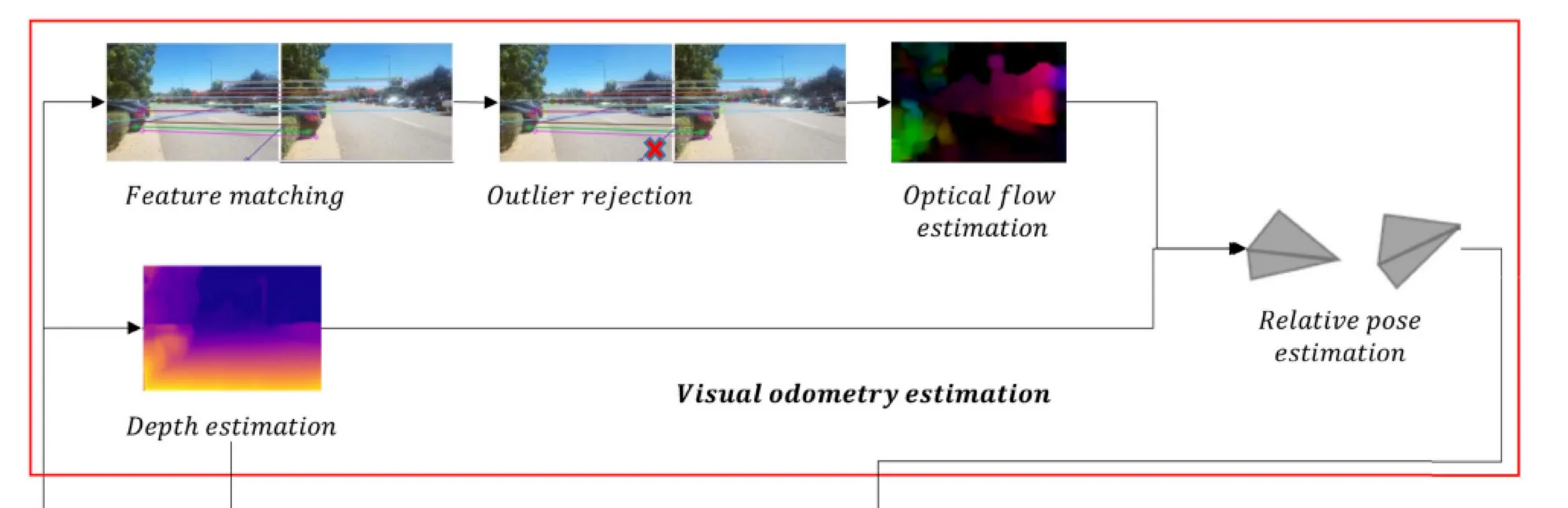
Can you identify the core components from it? These are:
- Feature Matching: matching and tracking features from frame to frame
- Outlier Rejection: rejecting the features we matched wrongly
- Optical Flow Estimation: Calculating how much each feature moved over time
- Depth Estimation: Because knowing the depth is always helpful. Note that depth can be obtained using stereo cameras, which would likely make it better than using a monocular camera
The output? The visual odometry — the motion of your camera. See it in action below:
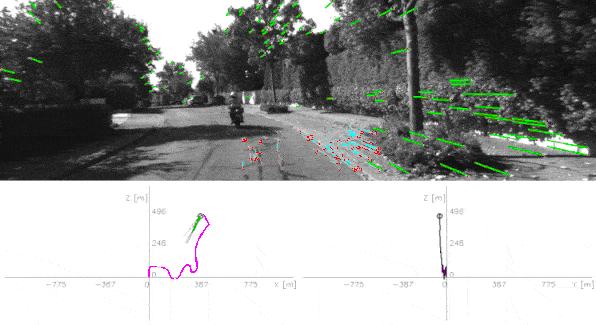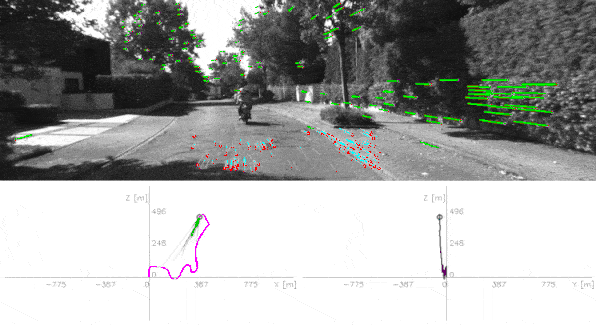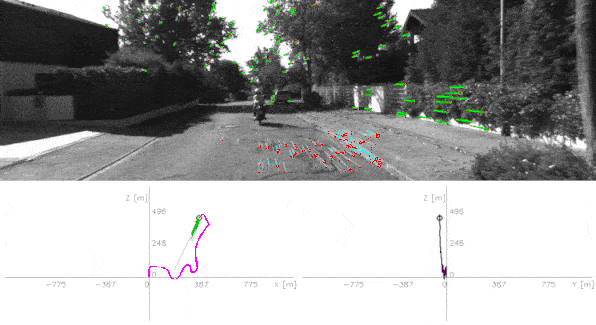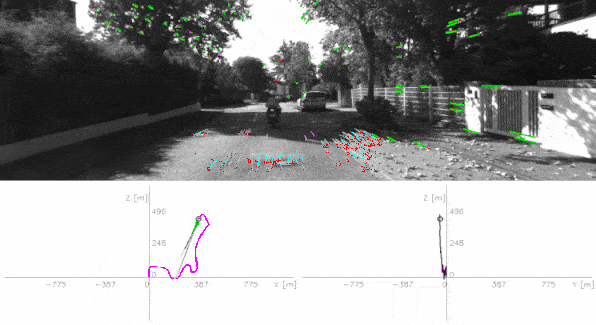
How it works
We've seen a way to make monocular Visual Odometry work, but it's not the only way. We could use stereo vision and do it differently. We could very well abstract this entire part, and say that there are many ways to compute the motion of the camera. In fact, we could even use an IMU (Intertial Measurement Unit) and that would give us Visual Inertial Odometry (VIO).
Algorithms to check: RANSAC, Perspective N Point (PnP), 5-Point Algorithm, Feature Matching, Direct Sparse Odometry (DSO)
Part 1 was about extracting features and identifying their motion. What is this going to be used for? Let's find out.
Part 2: Local Optimization & Mapping
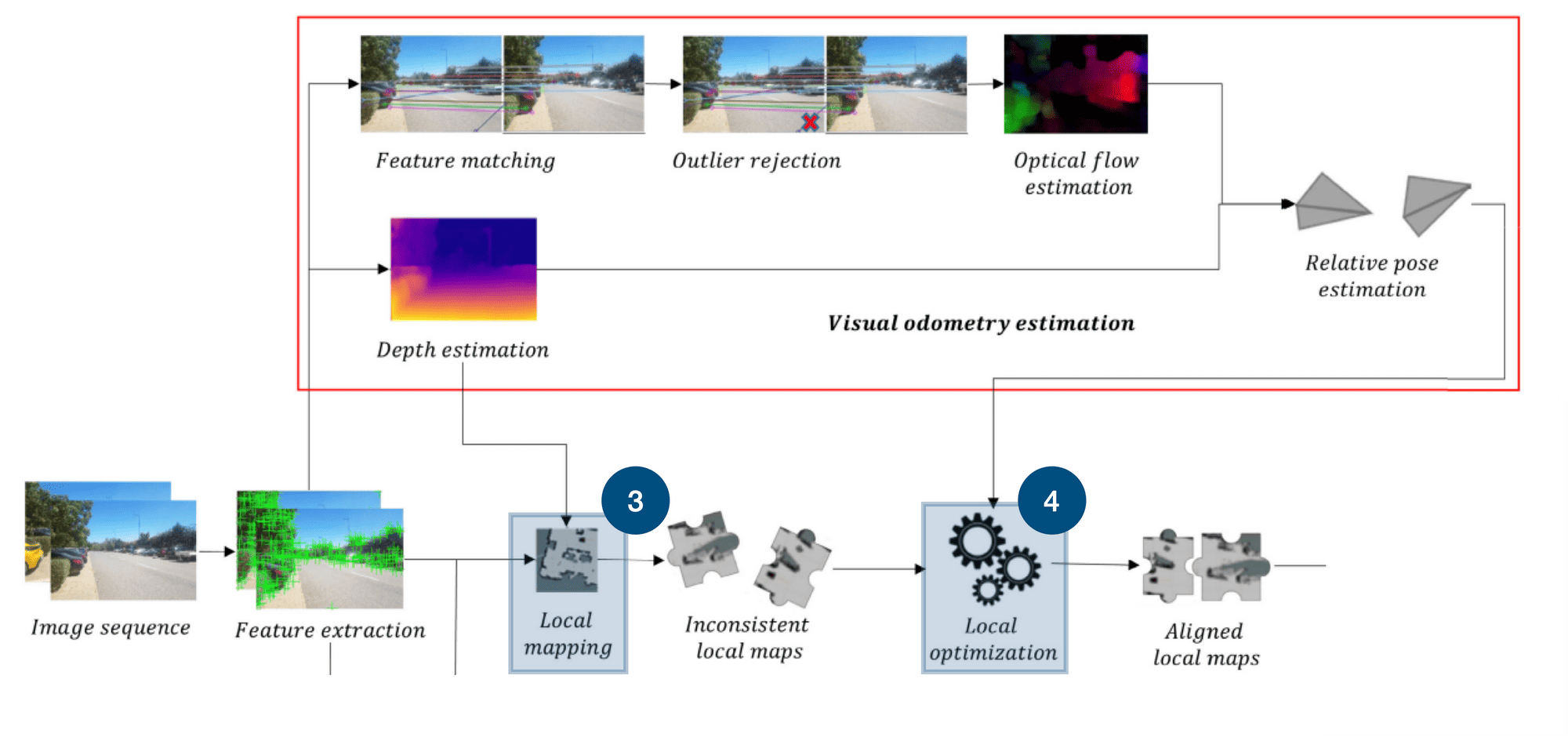
The next two blocks are local mapping and local optimization.
3 - Local Mapping
Do you remember when I told you that we could replace the point clouds with the visual features? Well, this idea has a flaw:
- The point clouds are in 3D
- But the visual features are 2D pixels on the image
And so, when you look at robot mapping, and the types of maps that robots use (I have a great article on this here), you see that we have point cloud maps, vector maps, occupancy maps, feature maps, etc... But we don't really have a way to use the visual features.
It would be great if we could "project" these 2D pixels to 3D, and this is what this step is about. Local Mapping takes a depth map and the extracted features, and put them in a 3D map. This is a real "mapping" step, where we map the 2D features to their corresponding locations in 3D.

How does it work?
There are MANY ways to make this step work; and this is THE core of SLAM. We could use Sparse Maps or Dense Maps. We could use 3D Reconstruction techniques like Multi-View Stereo & Structure From Motion. We could use Kalman Filters or Particle Filters, because at every step, we'll want to:
- Predict and Update the position of each feature in 3D
- Predict and Update the position of the camera in this 3D environment
Algorithms to check: Triangulation, Stereo Vision, LSD-SLAM, EKF-SLAM, Fast-SLAM
4 - Local Optimization
At this step, you have, at each frame, a mini local map. This is cool, but is has an issue: it's prone to error accumulation. Think of it like a Kalman Filter, without it, we don't really have the consistency over time, and here, we have the exact same thing: we want to align our maps to be consistent from frame to frame.
If we project our features to 3D at each step, we could accumulate errors, and therefore this step is here to re-align the consecutive maps.
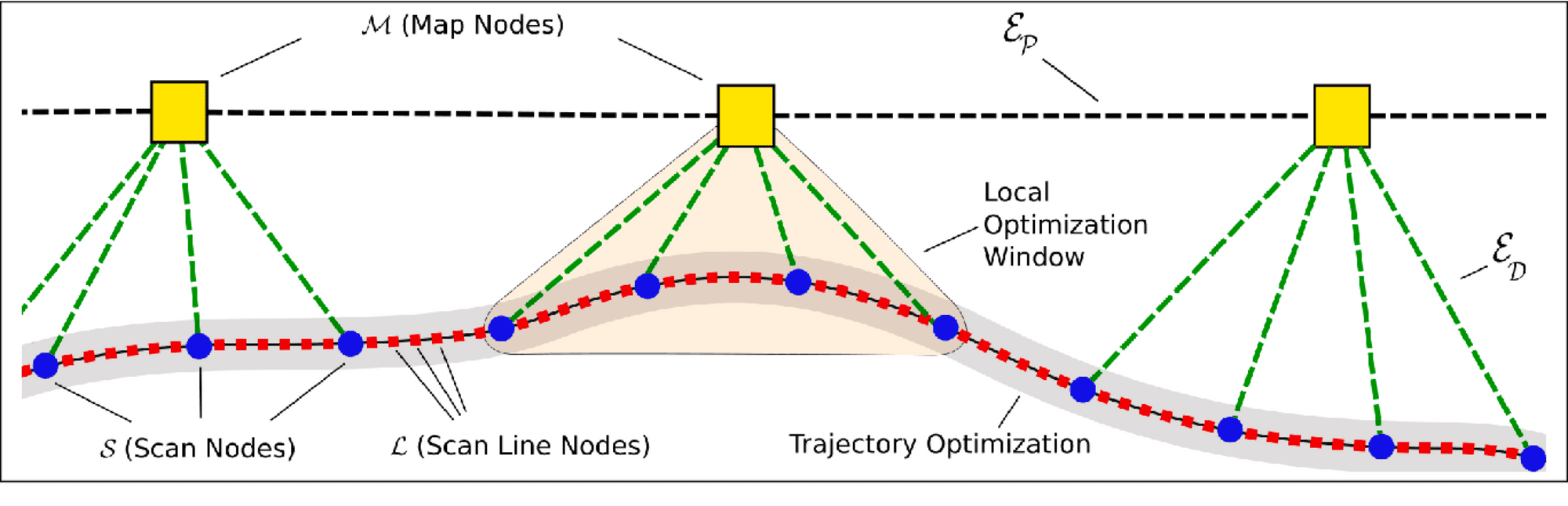
How it works
This step depends on the core SLAM algorithm you're using. If you're using a Kalman Filter, the Update step is going to handle the alignment of everything. If you use Graph-SLAM, you're keeping a giant graph with the pose of each landmark and yours, and this step becomes graph optimization. Algorithms like Iterative Closest Point can be also very relevant here.
Algorithms to check: Iterative Closest Point (ICP), Bundle Adjustment, Ceres Solver
We are, at this point, in possession of tons of local maps, synchronized and aligned through time. We have done it all locally, but never really globally. It's therefore time to align the global map!
Part 3: Loop Closure & Global Optimization
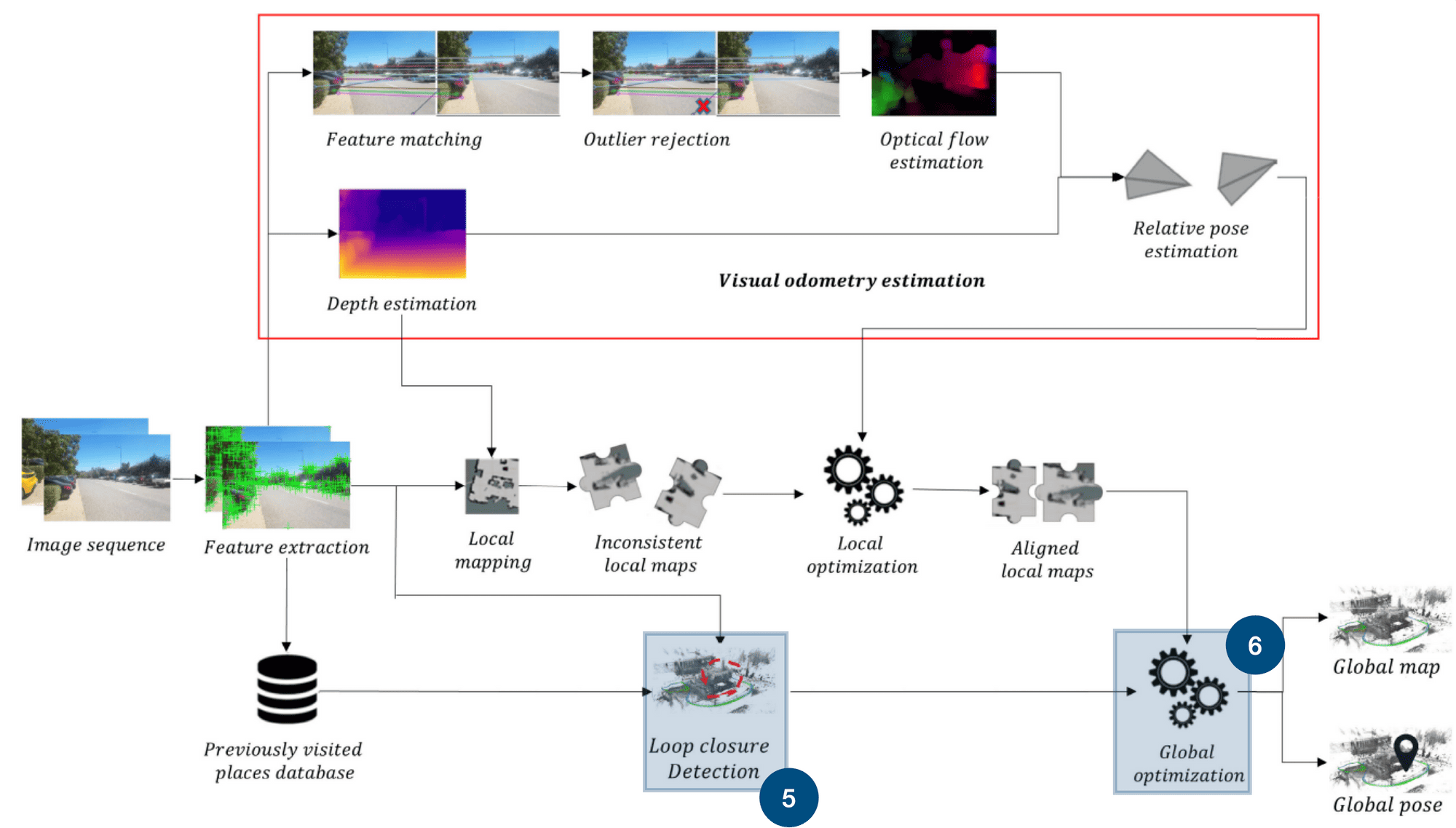
The previous 2 blocks were "local". We were dealing with consecutive maps. The next and final 2 blocks are global. We are going to build global maps of the world we're visiting, and this using two ideas:
5 - Loop Closure Detection
Loop closure is one of the most interesting ideas in Visual SLAM and in SLAM in general. It's the idea of aligning points or features that have been already visited a long time ago. So, my drone passes the Empire State Building, then circles around Manhattan, then sees the Empire again. Boom. We close the loop, we align the point clouds from the first and the second visits.
See from this Visual SLAM example how it works by recognizing previously visited areas, correcting any drift that has occurred in the map or trajectory over time, and updating the overall map and robot's pose within it.

How it works
The "loop closure detection" step is about detection. A very common approach for this is using Bag-Of-Words. There are graph based approaches too. If you'd like to learn more about Loop Closure, I have an entire article about it here.
Algorithms to check: Bag-Of-Words, FLANN, DBoW2
6 - Global Optimization
Finally, we aggregate all the information from the local maps, run the bundle adjustment and optimize the map completely. This step is the alignment of the entire map! We can again use the techniques from local optimization, at a global scale. In many approaches, we're using graph optimization.
Algorithms to check: Pose Graph Optimization, ATLAS, Bundle Adjustment
And here they are, the 6 components of Visual SLAM!
Let's do a quick summary, and then go see some -in-the-wild- Visual SLAM algorithms.
The Summary
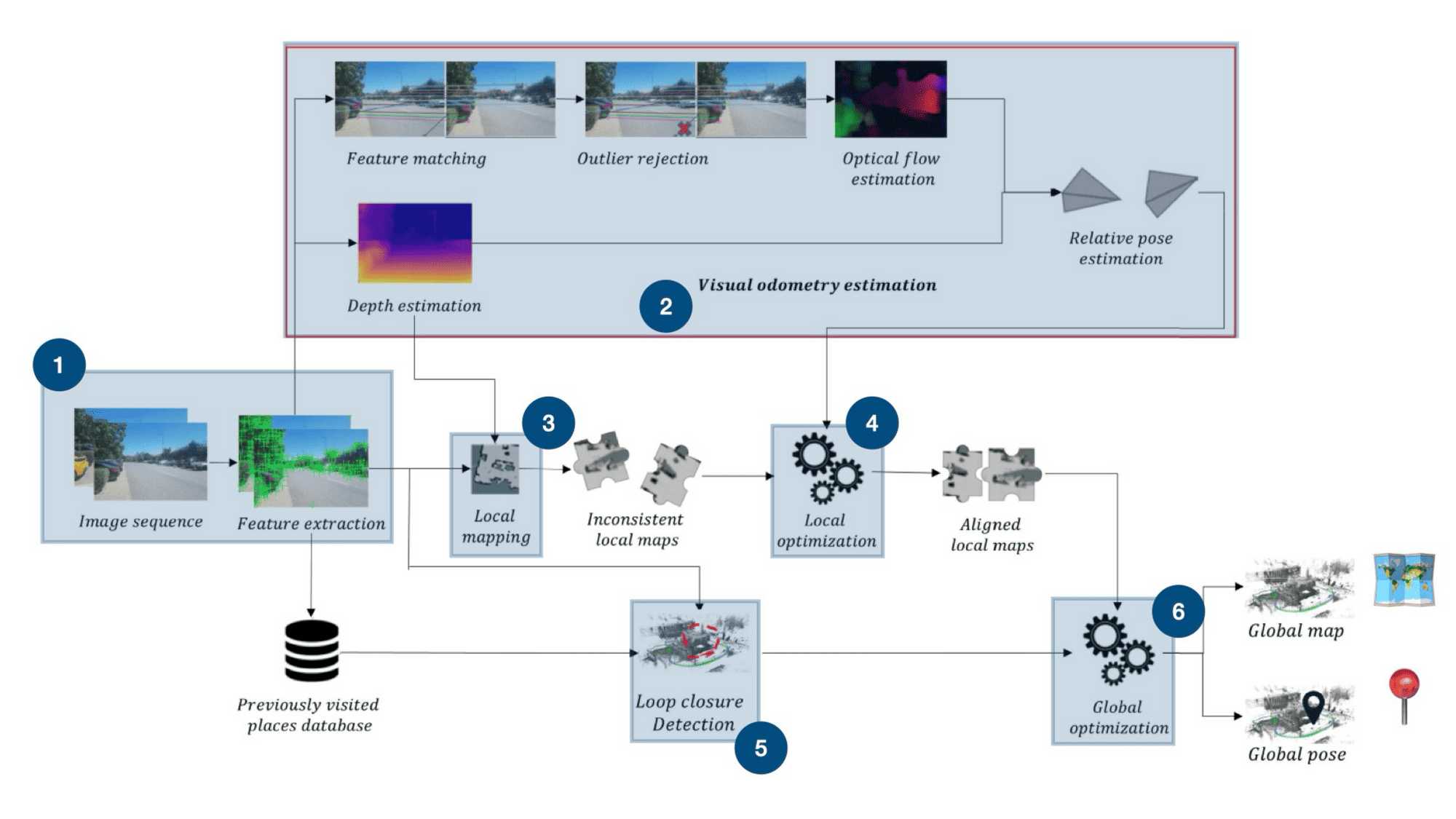
Here are our 6 steps! Notice how we naturally flow from the images to the maps and poses! Let's do a final breakdown:
- Feature Extraction is the step where we try to extract visual features from images.
- Visual Odometry is the immediate next step where we compute the camera motion by computing the motion of features from frame to frame.
- In Local Mapping, we're projecting the features in the 3D space. This step IS the core SLAM step where we create the map, can be done using triangulation, a depth map, or others.
- In Local Optimization, we want to align the consecutive maps from frame to frame using the local maps and the odometry.
- The goal of Loop Closure detection is to identify previously visited places. We'll do this by comparing the current features with the history of features.
- Finally, global optimization is about aligning the entire map and producing the final output: a map and a pose.
Get it? Awesome, now, let's see a few examples...
Example 1: ORB-SLAM
One of the most well-known algorithm in Visual SLAM is called ORB-SLAM. Before going in the details, here is a demo of how it works:
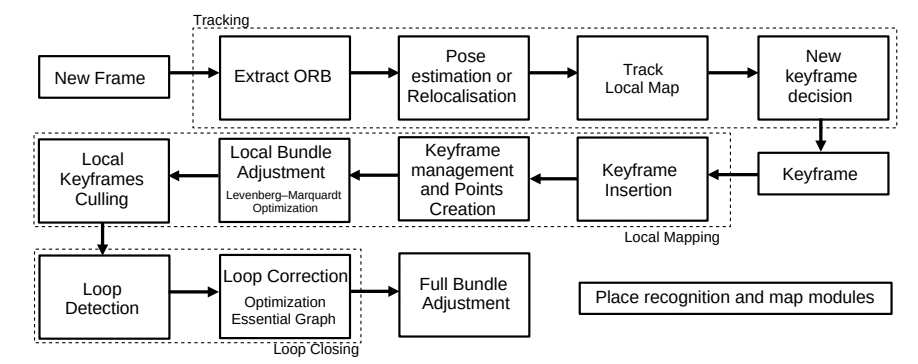
- Feature Extraction: As the name suggest, we're using the ORB Features. These are very popular and work great in this case.
- Visual Odometry: Next, we'll be matching these features with those in the previous frame or with the local map, estimating the camera's motion based on these matches, and refining the estimate through optimization techniques like RANSAC to minimize reprojection errors, thereby determining the camera's pose relative to its previous position.
- Local Mapping: We create a local map by triangulating matched ORB features and optimizes it using local bundle adjustment. The "3D" is computed via the motion of features.
- Local Optimization: This step is done using something named the "Bundle Adjustment". I won't describe it here, but it's an algorithm that minimizes the gap between observed feature positions in images and their predicted positions based on the camera model and 3D point estimates.
- Loop Closure: This step works by using a Bag of Words (BoW) model to efficiently compare the current frame against all previous keyframes. When a potential match with a high similarity score is found, geometric verification is performed to ensure the loop closure is valid, leading to a pose graph optimization to correct accumulated drift and ensure global consistency of the map.
- Global Optimization: This step is the final optimization, and in this case we're updating a graph, so it's a GraphSLAM.
Now, it's a bit more complex than this, the actual steps look like this:
Conclusion
Visual Simultaneous Localization And Mapping means visually localizing your robot while simultaneously mapping the world with a camera. Today, Visual SLAM systems have become so good that they're used to build maps! Yes, originally, SLAM was used when you didn't have a map, and it was an edge-case. Today, it's probably one of the main ways companies use to build HD Maps.
In this article, I told you about the idea of detecting point features, but this is very "sparse". In fact, we could even call it "Sparse SLAM". When we get access to a LiDAR, or at least an RGB-D camera, we can also build Dense Visual SLAM algorithms. You could check Elastic Fusion or LSD-SLAM and see the difference when doing dense mapping. This is also a way to build an even more accurate monocular slam system.
We've discussed SLAM in autonomous driving, but realize that Visual SLAM can be used in so many other places... Like 3D Reconstruction, Computer Vision, or mixed and augmented reality. In fact, I'm pretty sure some of these algorithms run in Apple's Vision Pro. And that would make sense, considering the use case!
If you want to learn more about SLAM, and in particular about Visual SLAM, then I invite you to read the next steps...
Bonus Video
Next Steps ↪️
- You can read this article on Robot Mapping which could help you understand what is a map (useful, huh?)
- To get more in-depth on some topics, you could read my Point Cloud Registration article (about aligning point clouds) and my Loop Closure article (about closing loops). You're gonna have some fun there.
- If you're interested in becoming a SLAM Engineer, you would also benefit from my SLAM Engineer Roadmap, in which I reveal the core skills to learn.
- Finally, I have a course on SLAM, but I am not sharing it with just everybody, so I invite you to check the yellow box below to join the daily emails, in which I'll send you more information about it 😉




