How to Deploy a Deep Learning Model at the Edge?
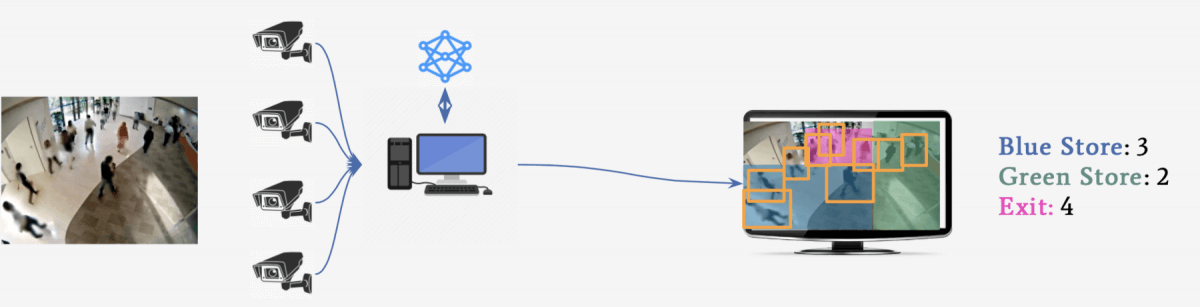
In this article, we're going to learn how to deploy a Deep Learning model in a shopping mall equipped with CCTV cameras.
➡️ Our main task will be to use the camera images, detect people using 2D Object Detection algorithms, and count the number of people per area.
There are many things we must consider:
- Picking a Deep Learning Model
- Overview of the Hardware
- CPU
- GPU and iGPUs
- VPU
- FPGA
- Choosing a Hardware for a Shopping Mall
- How to run several models in parallel?
This article is the second of a series on Deep Learning optimization & deployment, the first one is here.
Picking a Deep Learning Model
Deep Learning
There are many Deep Learning models available for people detection.
One great thing is that we don't need to train a model from scratch.
We're going to select a pretrained Deep Learning model for person detection trained with Tensorflow or Optimized for Intel OpenVino.
I'll go back to that part later, the point is, we don't train.
How to select the model?
YOLO, Faster RCNN, SSD, EfficientDet, CenterNet, RetinaNet...
Many models can do the job.
Our task to pick one based on a time/accuracy tradeoff.
Here, YOLOv4 can be a good fit.
So we have 3 more things to cover:
- How to code the people monitoring?
- What is the output we want to give to the Mall.
- How to deploy our model "physically"?
People Traffic Monitoring
The algorithm will need many things:
- Extract the bounding box output.
- For each bounding box, increment the counter
- Define areas based on the pixels, and match the boxes with areas (3 people in front of Store 2, 4 in front of Store 3, ...)
- At next step, perform a re-identification/tracking.
- If a bounding box is not matched, increment the counter
- Else, don't.
- ➡️ You can learn more about it in my course on tracking.
- Update counters per areas..
Output
For each store, we want the number of people per store.
For that, we'll have a list of stores, and the number of people in front of each.
➡️ To implement this, we'll use technologies such as MQTT, Mosca, Node and FFMPEG Servers.
I won't give much details here, probably in a dedicated article.
🧐 "Hey guys, which laptop should I use for Deep Learning?"
🥸 "Use Nvidia Gipius! There is CUDA!"
Well, no.
In our case, that's the last thing we'll do!
Let's first have a look at available hardware.
Overview of Hardware
CPUs - Central Processing Units
It's the electronic circuitry that executes the instructions of a computer program.
- They can be super powerful (Intel Xeon), average (Intel i5 SkyLake), or low power (Intel Atom).
- They can have one core, or be multi-cores (contains multiple CPUs).
- They can also carry an integrated GPU (iGPU).

GPUs - Graphics Processing Units
A GPU can perform operations in parallel (vs sequentially for a CPU).
- At first, it was used to display videos or to make video games. Today, it's a must-have in many cases.
- An integrated GPU (IGPU) is a GPU that is located on a processor alongside the CPU cores and shares memory with them.
- Integrated GPUs are much less powerful than external GPUs.
- Nvidia GPUs have CUDA/CUDnn accelerators, made for AI.
➡️ Performance varies similarly.
It's still relatively good.🏃♂️🏃♂️🏃♂️
VPUs - Vision Processing Units
These are accelerators that are specialized for AI tasks related to computer vision—such as Convolutional Neural Networks (CNNs) and image processing.
👉You can read my article on VPUs here.
- The Intel Neural Stick Compute 2 is an example of VPU: it costs 100$.
- They can carry their own processor, such as the Myriad X in the Neural Stick Compute 2.
- In this case, you can plug the USB stick to a computer. The CPU will be used only to transfer data through USB.
- You can also stack multiple VPUs and increase performance.
➡️ Performance 🏃♂️

FPGAs - Field Programmable Gate Arrays
These are chips designed with maximum flexibility, so that they can be reprogrammed as needed in the field (i.e., after manufacturing and deployment).
- Most of these processors have a very long lifespan. It makes sense to use that for over 10 years.
- They are also very robust and can run 365 days/year.
- They can work with Deep Learning very well.
➡️ Performance 🏃♂️🏃♂️🏃♂️
Picking a Hardware for a Shopping Mall
Now that you know about it, you might realize that, in some cases, using a powerful CPU makes more sense than adding a GPU.
In other cases, adding a 100$ USB stick is the solution.
In the case of our shopping mall...
We're NOT going to purchase 1,000$ GPUs to put these on every CCTV cameras they have.
It just doesn't make any sense.
Our procedure will be as follows:
- Since their budget is limited, we'll try to work with their existing computers (CPUs).
- If these computers are saturated due to the cameras, we'll see if the integrated GPUs can do the work.
- If they are saturated, we'll see if we can add 100$ VPUs.
- If this is not powerful enough, then we might consider adding an external GPU.
- When they have a stronger budget, we can even switch to FPGAs.
How to run several models in parallel on a CPU?
It might be hard to picture. If you run a basic YOLO algorithm, it can work at 10 FPS, maybe 5 on a CPU.
- How to deal with people moving every second?
- How to deal with multiple cameras?
- With powerful neural nets? Running on every cameras?
- With person re-identification models?
➡️ One word: Optimization.
If we're going to use Intel CPUs for example, we can add the OpenVino toolkit.
It's something that will optimize the models for inference, so well that you can have amazing results.
Here's how it works:
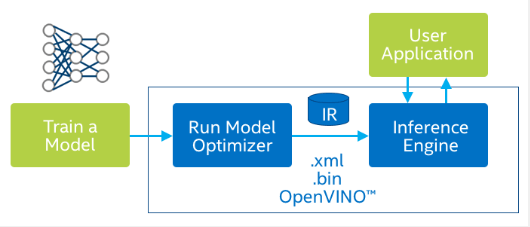
Once a model is trained, we're going to optimize it.
Many operations exist: Fusion, Quantization, Pruning, ...
They can all reduce the size of the network while keeping the accuracy.
Once it's optimized, we'll convert it to an Intermediate Representation (IR), that will sent it to an Inference Engine.
Et voila.
Here's something I did with the Intel OpenVino toolkit (through the Intel AI Nanodegree Program).

Can you notice the inference time? 0.053 ms.
That's a lot of FPS...and the model is one of the slowest!
Conclusion: The Intel Platform for Deep Learning Optimization
As we just saw, the Intel platform has been created to deploy deep learning models at the edge. It includes several pretrained models, optimization, a possibility to train your model, and most of all, the possibility to run several models at the same time using their platform. Other platforms exist, from other companies such as NVIDIA. But Intel's platform is the best platform to run your models on... Intel's devices!
I would recommend it if you're trying to implement models to companies already equipped with Intel's devices, or who have low budgets!